attention에 대해서 공부해 보았다.
attention은 transformer에서 쓰이며, seq2seq의 한계를 개선한 모델이다.
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
https://arxiv.org/abs/1409.0473
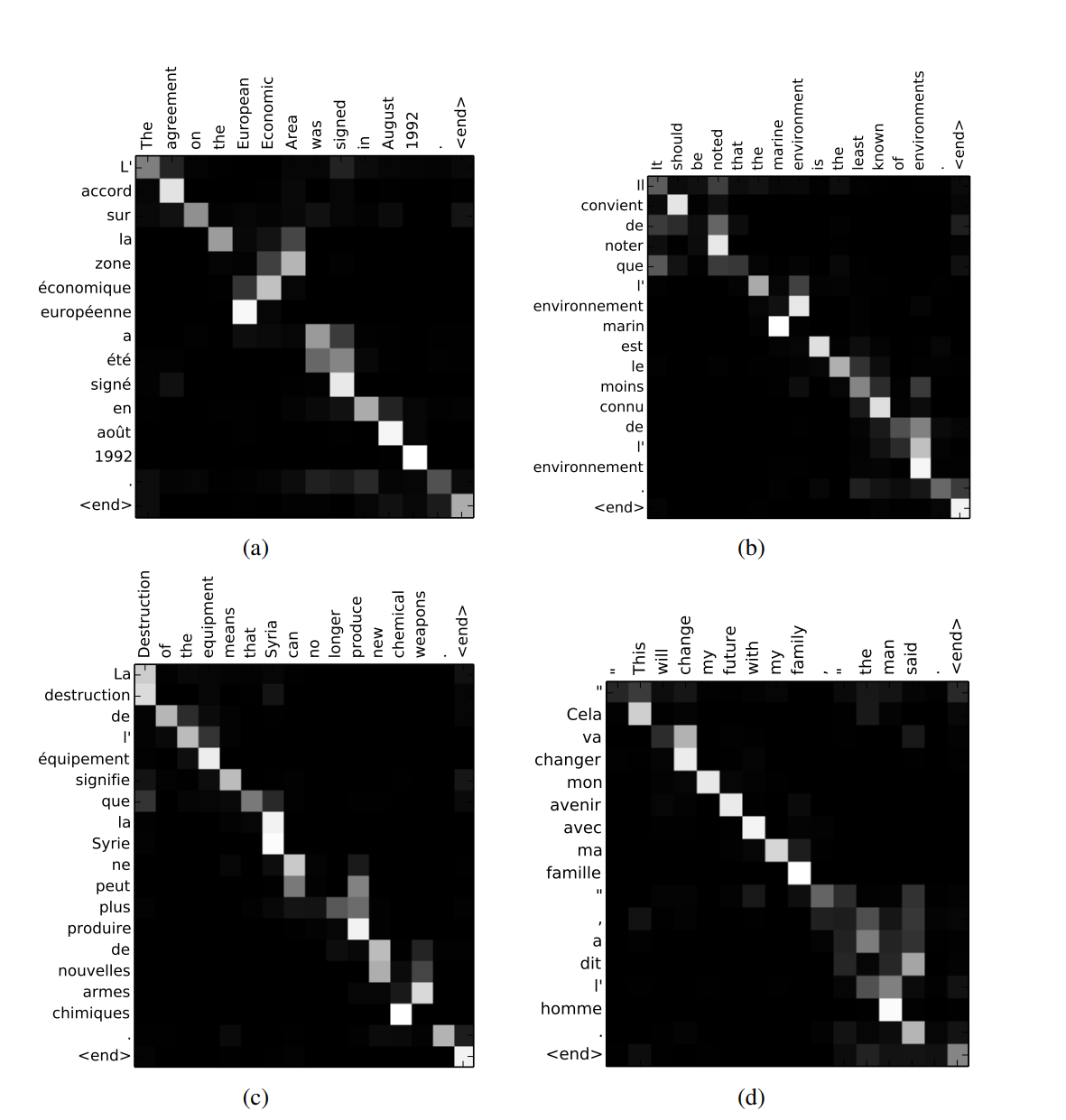
문장을 번역 할 때 단어들을 순서대로 하나씩 예측할 것이다.
다음 단어를 예측 할 때 source sentence의 모든 단어들에 집중할 필요가 있을까?
attention은 필요한 단어에 집중할 수 있도록 한다.
기존 encoder-decoder방식에서는 y를 예측할 때 encoder에서 나온 하나의 context 벡터를 필요로 했다.
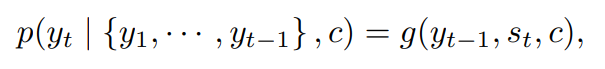
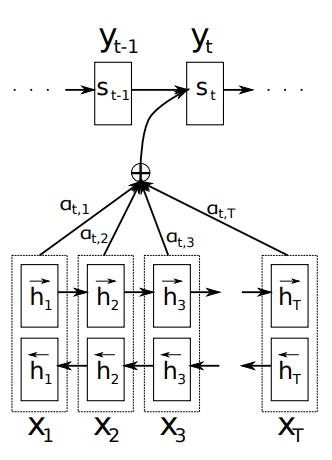
하지만 attention에서는 매 y마다 context벡터를 생성한다.
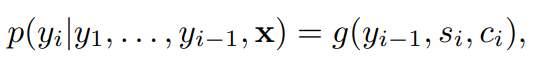
Decoder의 이전 hidden state를 query로 하고 Encoder의 hidden state들을 key와 value로 하여 Attention 값을 만들고 이를 이용해 context vector를 생성한다.
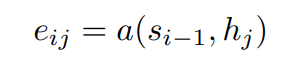
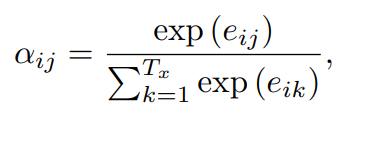

(h,s,c,i,j)가 각각 무얼 의미하는지는 https://velog.io/@nrye4286/RNN-Encoder-Decoder
를 참고하면 도움이 됨.
