nlp공부하며 인풋, 아웃풋의 길이가 다양할때의 학습과정을 공부해야겠다.
Attention Is All You Need
https://arxiv.org/abs/1706.03762
마스킹 필요성, 트랜스포머의 배치처리에 대해서 정리해 보고자 한다.
마스킹 필요성
학습시에 실전에서 생성하듯이 decoder에서 이전 출력을 추가해가며 새로 인풋으로 넣음을 반복하는 방식으로 output을 생성하게 되면 학습이 답이 없다.
따라서 target을 바로 decoder에 넣어서 생성하게 된다.
예를들어
< sos > I like apple 를 넣고 I like apple < eos >를 반환
이때 마스킹을 사용함으로서 < sos >만을 사용하여 I를 만들고,
< sos > I 만을 사용하여 like를 만들도록 해주는 원리이다.
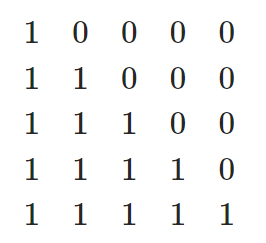
디코더의 첫번째 self-attention에서 어탠션값에 위 0인 부분의 값을 0에 가깝게 만들어서 softmax값이 0이 되도록한다.
따라서 output시퀀스의 i번째 벡터는 i+1이후의 단어와 관련이 없게 된다.
두번째 self-attention에서는 key와 value가 encoder의 context vector이므로 의도대로 뒷부분 단어와 관련된 연산이 발생하지 않는다.
(Feedforward계층 또한 시퀀스에서 각 단어들이 별개로 작동한다.)
트랜스포머의 배치처리
여러 시퀀스를 모아서 배치처리를 하게 되면 시퀀스의 길이와 정답의 길이가 달라서 문제가 발생한다.
이때 뒷부분을 < pad >토큰으로 패딩처리를 하고, 트랜스포머의 self-attention부분에서도 그 위치에 마스킹을 함으로서 문제가 발생하지 않도록 한다.
loss function
문장이 정확하지만 한 단어씩 밀려있는 경우에 낮은 loss값을 반환하는 함수로는 뭐가 있을까..?
cross-entropy는 위같은 상황에서 잘 작동하지 않음.
