attention is all you need를 읽어봐야겠다고 생각을 했다.
transformer를 다루는 논문인듯 싶은데 일단 attention이 뭔지 정확히 모른다.
그래서 attention에 대해서 찾던 도중 rnn, lstm, seq2seq등의 한계를 극복하기 위해 attention이 등장했다고 찾게 되었다.
seq2seq도 뭔지 모르기 때문에 seq2seq부터 알아보려고 한다.
Sequence to Sequence Learning with Neural Networks
https://arxiv.org/abs/1409.3215
DNN은 speech recognition과 visual object recognition에서는 훌륭한 성과를 보인다.
하지만 input과 target의 차원이 고정돼 있는 문제에만 적용될 수 있다는 한계가 있다.
seq2seq는 위 한계를 개선했다고 한다.
seq2seq
seq2seq는 인코더와 디코더로 이루어져 있다.
인코더는 rnn,lstm,gru등으로 고정길이의 벡터로 반환하는 역할을 수행한다.
디코더는 인코더의 출력을 기반으로 원하는 출력 시퀀스를 생성하는 역할을 수행한다.
이전 decoder의 output을 다음 decoder의 input으로 사용하며 output이 eos가 나올때 까지 반복한다.
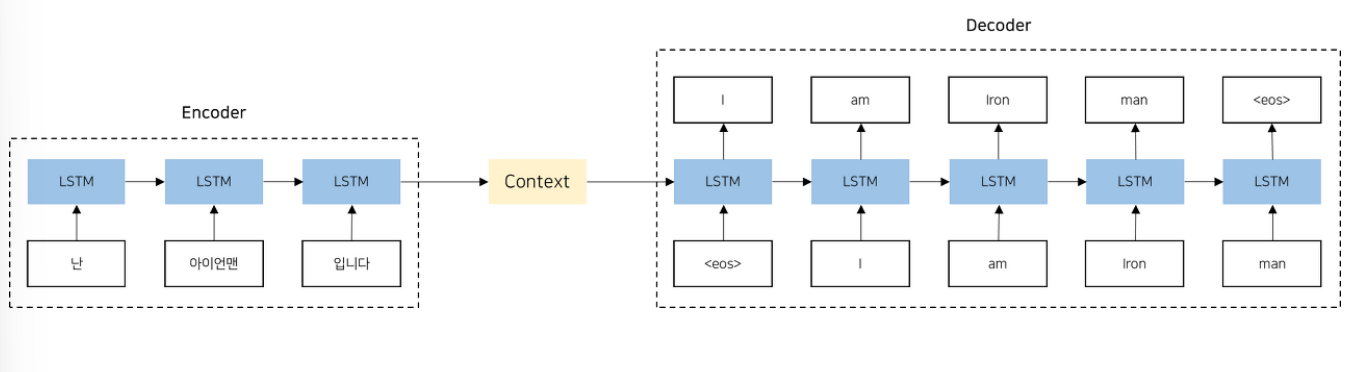
seq2seq의 한계는 인코더가 고정길이의 벡터로 압축하므로, 입력시퀀스의 길이가 길어질수록 정보의 손실이 발생할 수 있다는 점이다.
그리고 rnn의 고질적인 문제인 경사 소실 또는 폭발 문제가 존재한다.
https://github.com/bentrevett/pytorch-seq2seq/tree/main/legacy
(seq2seq 등의 코드를 볼 수 있는 깃허브 링크)
학습시에 teacher_forcing을 이용하여 decoder에서 다음 input값을 50%의 학률로 이전 target값을 바꿔주어 학습시에 도움이 되게 하고
evaluate시에는 teacher_forcing을 끄는 방식이 인상적이었다.
encoder에서 마지막 hidden state를 사용하므로 input의 길이는 상관이 없고,
decoder에서는 target값을 인자로 받긴 하지만 teacher_forcing을 끄게 되면 target의 길이만을 output의 길이로서 사용하므로 큰 길이의 0으로 이루어진 target을 넣어주게 되면
실전에서 모델 전체의 input과 output의 길이가 유동적으로 조정되는것을 볼 수 있다.
