1.딥러닝이란?
-
CNN : MNIST 데이터 - image 문제 , classification
-
image classification을 다룰 수 있는 tasl : object detection (심화)
-
딥러닝 종류
: image classification = 이미지 분류
: object detection = 객체 탐지 (위성탐지 등)
: oriented bounding boxes
: semantic segmentation = 픽셀 단위의 분류
: pose = 포즈 문제 (사람이 어떻게 서있는지)
: vision and natural language
2.object detection
1.예시

포항공대에서 8년전 발표한 사람 인식 객체 인식 기술

자동차 차선 인지
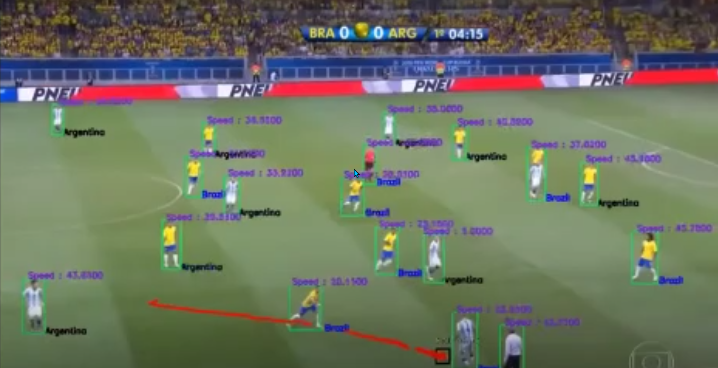
사람과 공에 대한 구분 및 팀, 선수별 스피드 인지
-> 탐지를 놓친 경우도 존재하며,심판을 특정 팀으로 인식하는 오류도 있으나
프레임을 활용해서 자동으로 팀을 선택하고 추적하도록 한다.
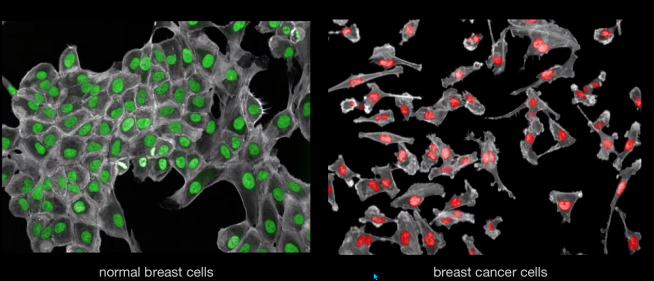
의료 : 정상세포와 암세포를 구분하는 인식 기술
2.object detection 정의
classification + localization
classification + bounding box regression(회귀)
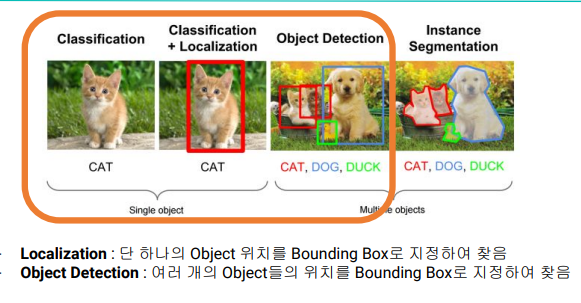
- object detection은 하나의 이미지에서 여러개의 object을 탐지
- 위치를 bounding box로 지정하여 객체를 탐지한다.
3.object detection 개념

꼭 알아야할 파트
- bounding box
- class classification
- confidence score
1.bounding box

- 하나의 object가 포함된 최소 크기의 박스이다.
- 지도학습, 학습하는 과정에서 정답이 있어야한다.
- 이때 박스는 '정답 박스'라고 할 수 있다.
- ground-truth bounding box와 predicted box을 비교하여 정답을 확인해야한다.

- normalize된 yolo
- 0에서 1사이 값을 가진 위치정보가 있다.

해당 의미는? 꼭짓점 예측을 잘한다.

해당 의미는? 박스 크기에 대한 예측을 잘한다.
-> 즉 , 위치를 잘 예측한다.
2.confidence score

- 객체가 bounding box안에 있는지 확신의 정도
- ex: airplane에서 예측한건 99% 정도이다. 76%정도이다.
- predicted bounding box의 confidence score : 0과 1 사이
- 확신정도가 1에 가까울 수록, object가 있다고 판단
- 0에 가까울수록 박스안에 object가 없다고 판단
- 모델에 따라서 계산하는 방식이 다르다.

(이 모델이 어떤 형태에 적용되어있는지에 따라, 확률이다 아니다로 말할 수 있는데
여기서 해당 확신의 정도를 확률이라고 보기는 어려움)
3.IoU (Intersection over Union)
- 얼마나 겹치는지 확인하기 (두 박스의 중복 영역)
- 겹치는 영역이 넓을수록 좋은 예측
- 두 박스의 중복 영역 크기를 통해 측정
- 0과 1 사이의 값
예시
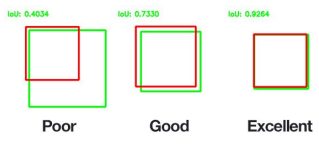
중복이 잘될수록 예측이 잘되었다고 본다.
4.NMS (Non-Maximum Suppression)

-
해당 과정을 통해 박스가 3개에서 1개로 줄어들었다.
-
단계

1.일정 확신점수 이하의 bounding box을 제거한다.
: 이하의 값 모조리 다 제거시킴
2.남은 박스들 , confidence score 내림차순 정렬
3.같은 object을 가리킨다고 생각해서 IoU값이 일정이상인 박스를 제거한다.
-> 즉 , 동일 객체에 대한 중복하는 박스를 제거한다.
-> 두박스의 IoU가 일정값 이상이면 같은 객체를 가리킨다고 인식이 되어,
더 스코어 점수가 낮은 값을 제거하는 것이다.
-> Conf Threshold가 높아지면 그 기준 이하의 Conf Score를 가진 박스는 아예 안 그려짐
Q. 여러개 박스 중에 컨피던스 스코어가 가장 높을 것을 선택하면 간단한 거 아닌지?
A. 박스 자체를 그리고 안에 object 가 있는지 확인 , but IoU는 겹치는 정도를 확인하는 것이다. 여러 bounding box 을 그리게 되면, 그 중 1개만 남기기 위해 동작을 시킨 것이다.
Q. NMS는 Box가 인식되면 이미지 픽셀 데이터와 관계 없이 Box 데이터로만 진행되는 것이 맞나요?
A. bounding box은 regression문제이며, 순수하게 box자체로 진행되는 것이다.
Q.정답 박스가 없을 때의 IoU는 어떻게 구하나요?
A.일단 IoU는 object가 있는지 확인하기 전에 점수를 먼저 내림차순으로 나열하고, 그 다음 객체 중복을 확인하는 것이다.
Q.여기서 임계값이란?
A.그 이하의 값은 제거, 이상의 값만 살려서 가는 것= relu함수
우리가 이걸 조절할 수 있음, 하이퍼파라미터 영역이 맞음. 예측할 때 쓰임
Q.임계값은 어느정도로 잡는지?
A.강사님 기준 보통 디폴트로 잡으심
5.Precision, Recall, AP, mAP
-
이 관점에서 recall?
:실제 object 중 object라고 예측한 비율 -
IoU Threshold 값에 따라 Precision, Recall 변화함
-
예시
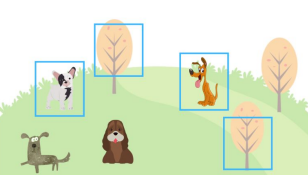
강아지에 대한 precision : 0.5 & recall : 0.5
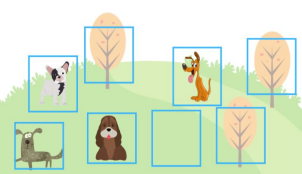
강아지에 대한 precision : 0.5 & recall : 1
- average precision
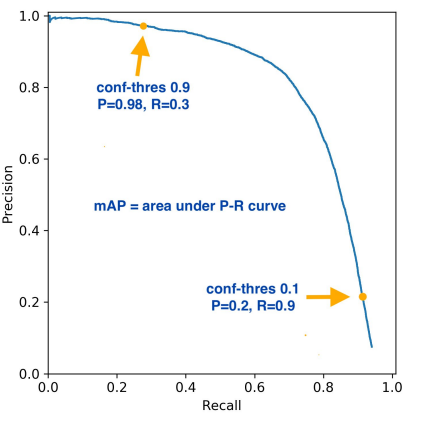
AP : 그래프 아래의 면적이다.
mAP : 성능 측정 지표, 각 클래스별 AP 합산해 평균 낸 것
만약 임계값을 높게 설정하였다면,confidence score 점수에 따라서 precision과 recall값이 달라진다.
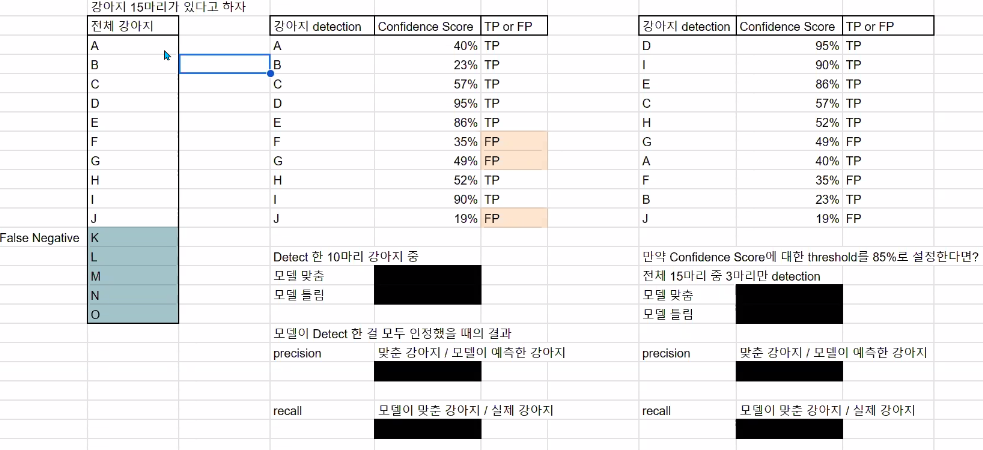
임계값이 85%라면?
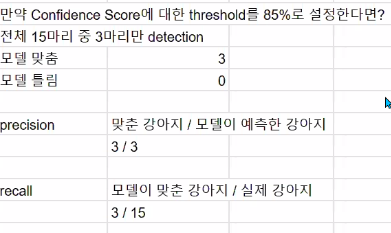
임계값이 30%라면?
-> 확신 정도 30%이상인 것만 취급
모델 맞춘 데이터: 6, 모델 틀린 데이터: 2
-> precision:6/8 & recall:6/15
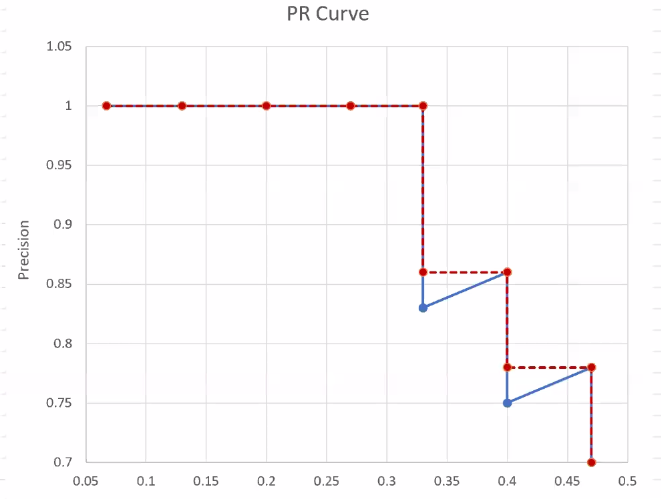
IoU와 Confidence score은 서로 유기적으로 연결된다.
mAP : 0~1값, 높으면 좋다
6.Annotation

- 정답정보
- bounding box 위치나 object이름을 특정 포맷으로 제공한다.
- 이미지 내 dectection정보를 설명 파일로 제공한다.
- 모델에따라서 정답정보의 파일형식도 달라진다.
3.UltraLytics : YOLO v8 모델 & roboflow
- 실습
진행시 document 확인해보는 습관 가지기
https://docs.ultralytics.com/modes/
확률 정보는 txt파일이 아닌 image 파일에 있다.
txt파일에는 class와 x,y,w,h이 있다.
실습
1.roboflow 설치 및 불러오기 & 데이터셋 가져오기
face detection project을 가져왔다.
(마스크 써도 얼굴인식이 되는 객체탐지)
https://universe.roboflow.com/mohamed-traore-2ekkp/face-detection-mik1i
#roboflow 설치,불러오기
!pip install roboflow
from roboflow import Roboflow
#데이터셋 가져오기
rf = Roboflow(api_key="ofcwPHNIuHjjUWT2299V")
project = rf.workspace("mohamed-traore-2ekkp").project("face-detection-mik1i")
version = project.version(18)
dataset = version.download("yolov8")
2.모델링 라이브러리 설치 및 불러오기
#모델링 라이브러리 설치
!pip install ultralytics
#모델링 라이브러리 불러오기
from ultralytics import YOLO, settings3.settings 확인 및 경로 수정
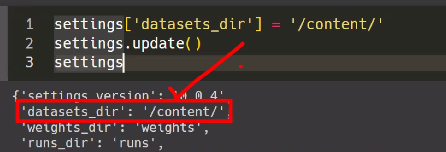
- settings 확인 결과 datasets_dir 경로가 datasets 내에 있어 contents 안에 있게 하도록 경로 수정
settings
#'datasets_dir': '/content/datasets',
#경로수정
settings['datasets_dir'] = '/content/' #경로수정코드
settings.update()
settings
4.yaml 라이브러리 불러오기
-
구조 확인가능
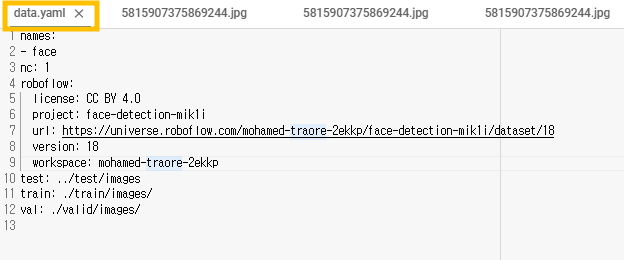
-
파일 읽고 수정 필요
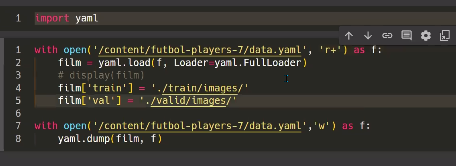
import yaml
with open('/content/Face-Detection-18/data.yaml', 'r+') as f:
film = yaml.load(f, Loader=yaml.FullLoader)
# display(film)
film['train'] = './train/images/'
film['val'] = './valid/images/'
with open('/content/Face-Detection-18/data.yaml','w') as f:
yaml.dump(film, f)5.모델 선택
#모델구조선택하기 : YOLO 모델 중 yolo8n 선택(?)
model_transfer = YOLO(model='yolov8n.yaml', task='detect')6.모델 학습
- 이때 에폭수의 디폴트는 100 , 그 이상 설정하는 것이 좋으나 학습데이터가 방대하여 에폭수를 20으로 설정
- 런타임 유형 변경 : CPU-> T4 GPU (CPU 진행시 에폭 1에서 멈춤 현상 O)
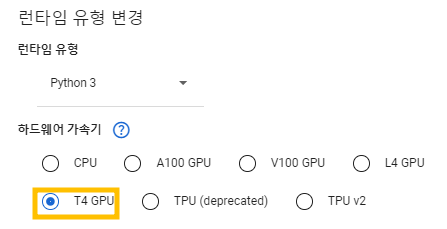
-30분 소요
#이떼 model 과 data 필수적으로 적어주기!
model_transfer.train(model='/content/yolov8n.pt', #학습모델 파일
data='/content/Face-Detection-18/data.yaml', #yaml 파일
epochs=20,#에폭수는 최소 100으로 하는게 좋음
#patience=5,
#seed=2024,
pretrained=True,
)
7.예측
- 코로나 사진 (마스크 쓰고 있는 사진) 활용

#예측
image_path='https://flexible.img.hani.co.kr/flexible/normal/970/633/imgdb/original/2020/0529/5815907375869244.jpg'
model_transfer.predict(source=image_path, stream=False, save=True)
#conf= iou=
#conf : confidence score 임계값 (객체가 bounding box에 있는지 확신의 점수 -> 높을수록 엄밀)
#iou : iou 임계값 (두 박스의 중복 영역 -> 낮을수록 엄밀) 8.결과 확인 및 임계값 조정하여 진행해보기
강사님 : 디폴트 진행 권장
1) 디폴트

2) conf=0.1, iou=0.9

3) conf=0.8, iou=0.2

4) conf=0.6, iou=0.4

- 주의점
1.test 데이터는 없어도 된다.
: 우리가 추론해야할게 test니까
train 과 valid 폴더 필요하며, 그 아래에 images와 labels 이 있어야한다.
: yolo가 요구하는 형식이다
: 직접 데이터를 만들때 다음과 같이 구성되어야한다. (참고하기!)
2.하이퍼 파라미터를 통해 임계값 조정이 가능하다.
: Conf Threshold 가 높아질수록 & IoU Threshold이 낮아질수록 중복박스에 대한 판단이 엄밀해진다.
-> Conf Threshold 가 높아질수록 그 기준이하의 score을 가진 박스는 그려지지 않는다.
-> IoU Threshold이 낮아질수록 그 기준 이상으로 bounding box가 겹치면 그려지지 않는다.
: 예측할 때 임계값 조정 필요하며, 우리가 직접 수정하여 조정이 가능하다.
4.summary
<개념>
1. bounding box : 하나의 object가 있는 최소 크기 박스
2. classification
3. confidence score: bounding box안에 object가 있는지 확신의 정도
4. IoU: 교집합/합집합
5. NMS: 겹치는 bounding box 제거하기
: 특정 Object라고 예측을 한 bounding box 중복을 제거함
6. recall & precision
recall에 대한 precision결과
: 커브 아래의 영역 = average precision
: 하나의 class에 대해서만 판단하는 것이 아니라 , 상위 하위 등 여러 class에대해서
구분하는 문제일수있다(애초에 이게 더 흔함)
-> mean AP = object detection의 평가 지표 (높을수록 좋음)
7. annotation
: 정답 bounding box에 대한 정보
: Yolo - txt 파일
< YOLO & roboflow >
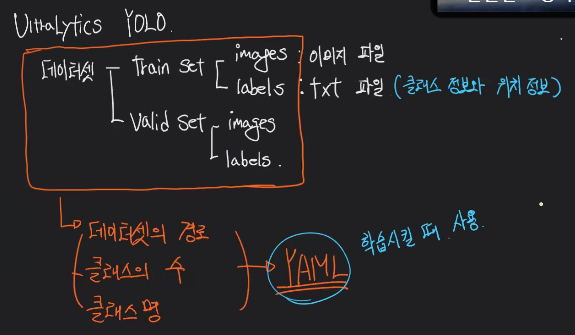
1.ultralytics YOLO (yolo 통해서 데이터 구성시 참고하기!)
- 데이터셋 -> train (images & labels) & valid (images & labels)
- images : 이미지 파일
- labels: txt 파일 (클래스의 정보와 위치 정보)
2.roboflow : computer vision(website)
- yolo와 같이 쓰면 좋음
- 다른 사람이 만들어놓은 데이터셋을 끌어다 사용해보기
- 나만의 데이터셋을 만들어서 사용해보기!!
(이미지수집과 annotation을 직접해봐야한다)
< roboflow을 활용한 YOLO8 모델 실습 >
1.라이브러리 설치 및 불러오기
2.데이터셋 설치

: 이후 futbol-players-7이라는 파일이 생성
: train, val, test 파일 구성
: data.yaml ) nc=클래스 개수=3, test 은 옵션
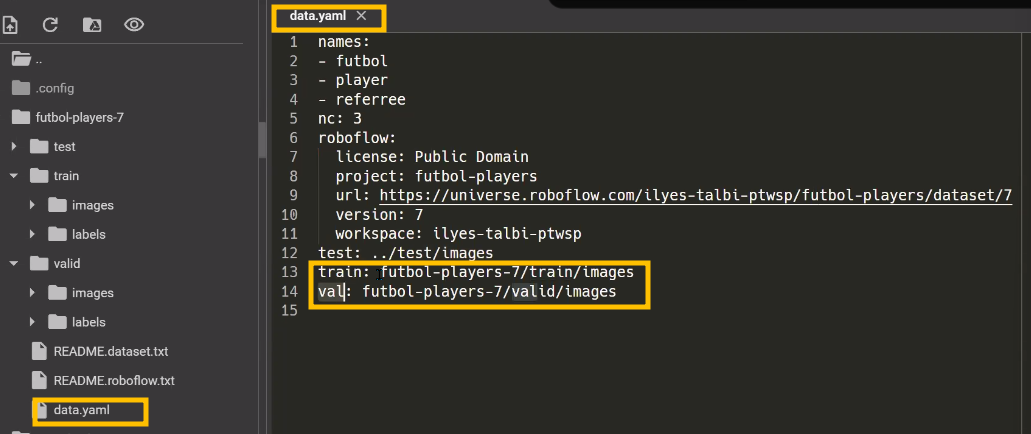
: 현재 train과 val)로컬 위치가 content가 없어 오류 위험 O
3.데이터셋 경로 수정
: data.yaml 내에 있는 train과 val 파일 위치도 변경해야함
- 모델 가져와보기

5.모델학습
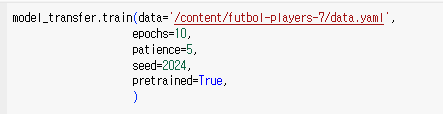
이때 model은 명시해주는 것이 좋음
.pt = 파이토치
Q.train이나 val 디렉토리는 딕셔너리 타입으로 수정하신거 같은데 names의 경우는 어떤 형식(?)으로 수정하였는지?
A.names은 수정할 필요가 없어서 수정하지 않았음
< 실습시 주의사항 >
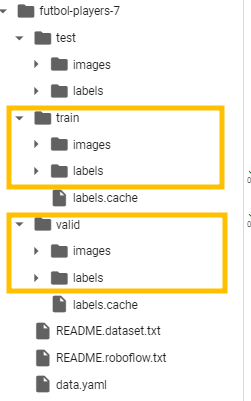
test 데이터는 옵션
train과 val데이터는 반드시 들어있어야한다.
이때 images 와 labels 이 있어야함

val 파일에 있는 data.yaml
: 데이터 구조 확인 가능
