PY4E CH.10 Tuples
이번에는 세 번째 콜렉션 타입인 튜플이다.
Lists vs Tuples
Tuples Are Like Lists
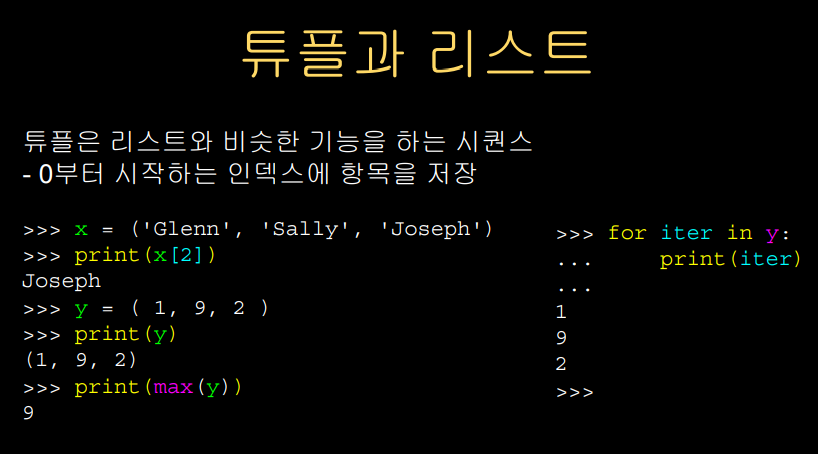
튜플은 리스트와 굉장히 비슷한데,
조금 다른 버전이라고 생각하면 된다.
튜프를 리스트처럼 인덱스가 부여된다.
이런 인덱스 문법으로 튜플을 선언하거나 출력할 수 있다.
리스트와 다르게 소괄호를 사용하여 선언한다.
또, 튜플 뒤에 for ~ in 뒤에 넣으면
튜플을 순회할 수 있다.
튜플은 순서를 보존한다.
원소를 순서대로 출력하기 때문에,
리스트건 튜플이건 같은 역할을 한다.
but... Tuples are "immutable"

튜플이 리스트와 다른 점은
변경할 수 없다는 것이다.
한번, 튜플을 만들게 되면
정렬만할 수 있고 수정은 할 수가 없다.
다시말해, 어떤 인덱스 자리의 값을
내가 원하는 값으로 수정할 수 없다.
튜플을 수정할 수 없는 이유는
바로 '효율성' 때문이다.
튜플은 지금까지의 다른 자료구조보다
용량도 적게 차지하고 접근도 훨씬 빠르다.
그렇기 때문에 값만 저장하고 접근만 한다면
튜플을 사용하는 편이 좋다.
append나 count, extend, index, insert, pop 등 대부분 값을 변경하는 메소드는 사용하지 못하고
오직 튜플은 count, index 메소드만 사용가능하다.
Tuples are More Efficient
즉 튜플은 제한이 있는 리스트이다.
그런데, 우리는 왜 튜플을 사용하는가?
단순히 조금 더 효율적이기 때문이다.
튜플은 build의 과정이 없다.
파이썬 내부에서는 이미 튜플이
절대 변경되지 않는다는 것을 알고 있다.

튜플을 또 사용하기 좋은 때가 바로
임시로 변수를 만들어야 할 때이다.
Tuples and Assignment

튜플은 좌변에 변수를 가진 채로
튜플을 선언할 수 있다.
이게 무슨 말 이냐하면,
(x, y) = (4, 'fred') 이런식으로
선언할 수 있다!
이는 파이썬에서만 가능한 기능이다.
이건 그냥 할당 구문이 두개인 것과 다름없다.
중요한 것은 좌변과 우변의 원소의 개수가 같아야한다는 것이다.
개수가 맞지 않으면 에러가 난다.
- 괄호는 생략이 가능하다!
Dictionaries vs Tuples
Tuples and Dictionaries
튜플은 이전 챕터에서 배웠던 딕셔너리와도 관계가 있는데,
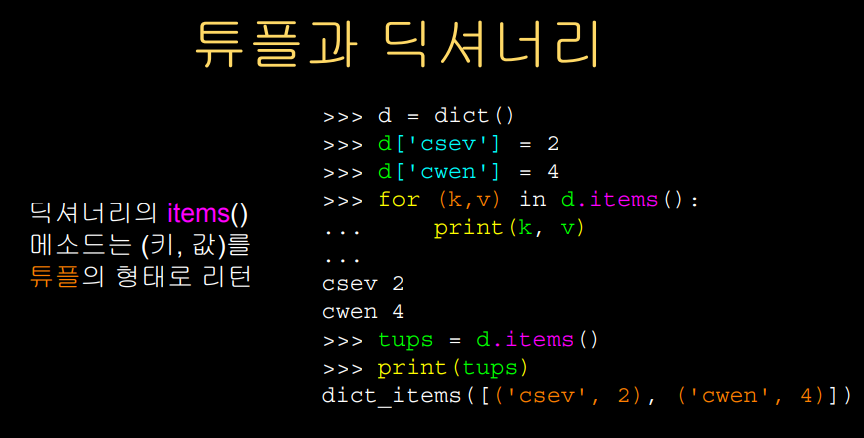
예를 들어 위와 같이
반복문에 반복변수를 (k,v)와 같이
키와 값의 쌍으로 넣어 루프를 돌리게 할 수 있다.
그러면, k와v는 연속적으로 키와 값을 받으며
루프를 돌게 된다.
tups = d.itemps()로 받은 배열을 보면
특별한 종류의 클래스이고
튜플로 이루어진 리스트를 반환한다.
Tuples are Comparable
또, 튜플이 좋은 점 중 하나는
튜플끼리 서로 비교가 가능하다는 점이다.

문자열과 같은 방식으로 비교를 한다.
왼쪽에서 오른쪽으로,
0번 부터 비교를 시작한다.
하지만 명확하게 비교의 답을 내릴 수 있을 때까지
비교를 진행한다.
Sorting Lists of Tuples

이렇게 비교가 가능했던 성질을 가지고
sorting 작업도 많이 한다.
딕셔너리의 키는 중복이 되지 않기 때문에,
value를 비교하지 않고
key 끼리만 비교를 해서 정렬한다.
using sorted()
sorted(d.items())
sorted 메소드를 사용하면,
튜플로 이루어진 리스트를 정렬해서 반환한다.
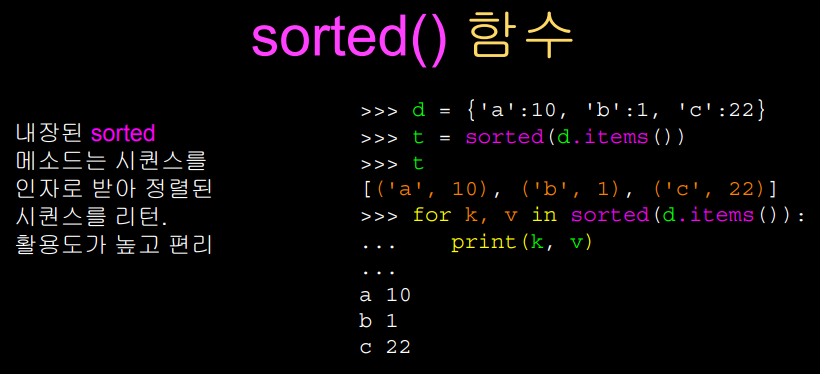
이런 식으로 루프를 짜면,
정렬된 순서(작은것부터 큰것, 오름차순)로 값이 출력된다.
만약, 값이 처음에 키가 뒤에 원소로 나오는 튜플을 가지는 리스트를 만들 수 있다면 값이 큰 것을 정렬하여 우리가 원하는 대로 값을 기준으로 정렬을 할 수도 있을 것이다.
Sort by Values Instead of Key

만약 반복문을 순회할 때,
k, v로 쓰지 않고
리스트에 append 할 때,
tmp.append((v,k)) 이런식으로
배열에 튜플원소를 추가한다면
우리가 원했던 배열을 만들어 낼 수 있다!
Exercises
Exercise 1. 가장 많이 나오는 단어 10개 뽑기
version 1)
fhand = open('romeo.txt')
counts = dict()
for line in fhand :
words = line.split()
for word in words :
counts[word] = counts.get(word,0) + 1
list1 = list()
for k, v in counts.items() :
list1.append((v, k))
list1 = sorted(list1, reverse = True)
for v, k in list1[:10] :
print(k, v)version 2)
lamda, closed form을 사용해
모든 것을 한 줄의 구문으로 해결할 수 있다.
이것을 list comprehension이라 부른다.
이런 구문은 파이썬이 얼마나 아름다운 언어인지
느끼게 해준다.
fhand = open('romeo.txt')
counts = dict()
for line in fhand :
words = line.split()
for word in words :
counts[word] = counts.get(word,0) + 1
# even shorter version using lamda
list1 = list()
list1 = sorted([(v, k) for (k, v) in counts.items()], reverse = True)
for v, k in list1[:10] :
print(k, v)Exercise 2.
fname = input('Enter Files : ')
if len(fname) < 1 :
fname = 'clown.txt'
hand = open(fname)
di = dict()
for line in hand :
line = line.rstrip()
words = line.split()
for word in words :
di[word] = di.get(word, 0) + 1
x = di.items()
list1 = list()
for v, k in x :
list1.append((k, v))
list1 = sorted(list1, reverse = True)
for v, k in list1[:5] :
print(k, v)
Exercise 3.
Write a program to read through the mbox-short.txt and figure out the distribution by hour of the day for each of the messages. You can pull the hour out from the 'From ' line by finding the time and then splitting the string a second time using a colon.
From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16 2008
Once you have accumulated the counts for each hour, print out the counts, sorted by hour as shown below.
name = input("Enter file:")
if len(name) < 1:
name = "mbox-short.txt"
handle = open(name)
dict1 = dict()
i = 0
numbers = list()
list2 = list()
for line in handle :
if line.startswith('From ') :
i = line.index(':')
numbers.append(line[i-2:i])
for number in numbers :
dict1[number] = dict1.get(number,0) + 1
list2 = sorted(dict1.items())
for k, v in list2 :
print(k, v)
Quiz.
이상없음.

유용한 글이네요 잘보고 갑니다!