PY4E CH.8 Python Lists
Algorithm vs Data Structure
Algorithm : A set of rules or steps used to solve a problem
알고리즘은 컴퓨터가 문제를 해결하도록
우리가 원하는 작업에 대한 여러 단계의 과정을
프로그래밍 언어를 통해 표현하는 개념이다.
Data Structure : A particular way of organizing data in a computer
자료구조는 자료를 똑똑하게 배치하고 구성하여
자료를 가지고 그 구조로 하여금
우리가 원하는 일을 보다 더 잘 수행할 수
있도록 하는 방법이다.
리스트!는 이 과정에서 우리가 첫번째로 살펴볼 가장 간단한 자료구조이다.
Collection
컬렉션이란 무엇인가?
무엇이 컬렉션이 아닌가?
What is Not a "Collection"?
우리가 이미 배웠던 '변수' 개념을 떠올려보자
변수는 라벨이 붙어있는 작은 메모리 조각이다.
우리가 값을 할당한다.
하지만, 이 '변수' 에는 한번에 한 개 이상의
변수를 가질 수 없다.
이런 문제점에 착안하여 컬렉션 개념이 나타났다.
컬렉션은 마치 suit case와 같다.
그 안에 많은 것을 담을 수 있다.
그 안을 구성하는 방법에는 여러가지가 있는데,
그 구성방법에 따라 다양한 자료구조가 있다.
A List is a Kind of Collection

대괄호에 안에 ',' 로 구분되어 있는
세 개의 원소를 가지는 friends, carryon 리스트를 볼 수 있다.
리스트는 기본적으로 리스트 상수이고 어떤 변수에 할당된다.
위 슬라이드 예제에서는 하나의 변수에 세개의 문자열을 가지고 있다.
하지만, 리스트의 원소가 꼭 정수거나 문자열일 필요는 없다.

파이썬에서 리스트 안에서 다양한 것(정수, 부동소수점수, 문자열, 또 다른 리스트 등)을 다양한 위치에 담을 수 있다.
필요하니깐 이렇게 다양한 것들을 담을 수 있도록 하지 않았겠는가...
Looking Inside Lists
리스트는 문자열과 비슷한 면이 참 많다.
리스트는 position 위치가 정해져 있고,
order 순서를 또한 가지고 있다.
리스트 내 순서는 0, 1, 2 ... 순으로 간다.
이러한 특징들 때문에 for 루프와 함께 자주 사용된다.
Lists are Mutable
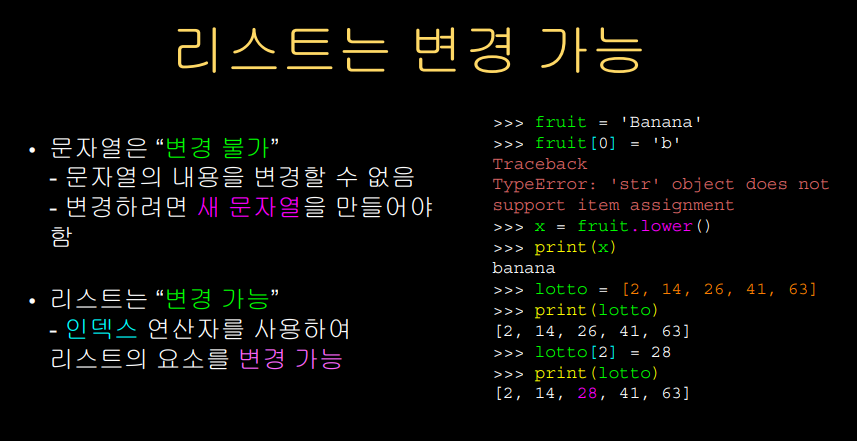
리스트와 문자열의 가장 큰 차이점이라고 한다면 바로 "가변성" 이다.
리스트는 기존 아이템을 새로운 아이템으로 대체 할 수 있다.
변수 자체를 바꾸어 넣는 것이 아니라,
인덱스 연산자를 사용하여
변수가 속한 위치를 이용하여 바꿔 넣는다.
이런 과정으로 원소에 변형을 준다.
How long is a List?
지금까지 우리는 문자열 자료형에서
문자열의 길이를 재는 데 len 함수를 사용했다.
리스트의 경우에 len 함수는
리스트 안의 원소의 개수를 세어준다.
글자 수 를 세는 것이 아니라,
몇 개의 원소가 있는지 알려준다.
Using the range Function
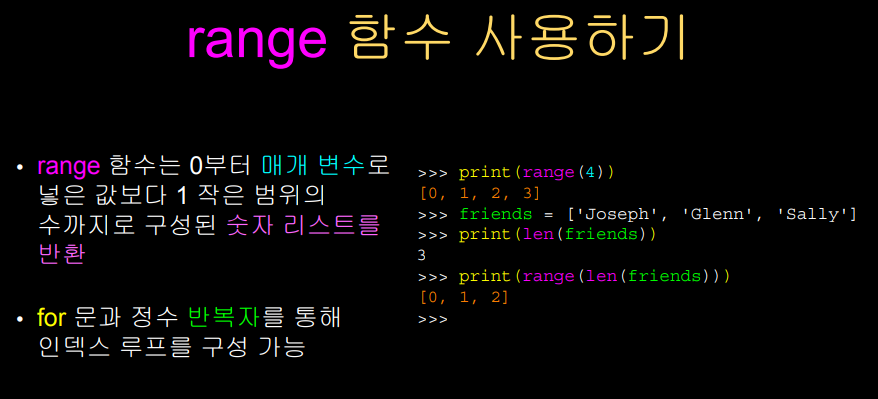
range 함수를 사용하면,
0 으로 부터 시작해서
매개변수로 넣은 값보다 하나 작은 값까지
범위의 수로 구성된 숫자 리스트를 반환한다.
for 루프와 len 함수 등을
range 함수와 함께 사용하여
인덱스 루프를 편리하게 구성할 수 있다.
!위 슬라이드를 보며 range 함수 반환값을 확실하게 이해해보자!
List Operator
리스트 가지고 연산하기
파이썬은 연산자에 대하여
객체지향적 접근법으로 다가간다.
Concatenating Lists Using '+'
덧셈과 뺄셈은 문자열, 숫자, 부동소수점 수, 정수, 문자열 등을 더할 수 있다.
덧셈은 리스트에서도 비슷하게 작동한다.
Lists Can Be Sliced Using ':'
리스트를 : 기호를 이용해 슬라이싱 할 수 있다.
문자열을 슬라이싱 했던 방법을 떠올리면
같은 방식이기 때문에 쉽게 기억할 수 있다.
끝 숫자는 항상 미만의 범위이다.
중요하고 잘 기억해야 한다!
List Methods

https://docs.python.org/tutorial/datastructures.html
리스트에 관련한 여러가지 메서드가 존재하고
dir 함수를 이용해서 찾아보고 자주 상기시키는 것도 좋다.
- append는 원소를 하나 추가한다.
count는 특정한 요소가 리스트내에서 몇개가 있는지 알려준다.
extend는 리스트의 끝에 원소를 추가해준다.
index는 특정원소를 찾아 위치값을 반환한다.
insert는 리스트 중간에 요소를 삽입하여 리스트가 확장될 수 있게 한다.
pop은 리스트에서 마지막 원소를 꺼낸다.
reverse는 리스트의 원소들의 배열순서를 뒤집는다.
sort는 값에 따라서 원소들을 정렬한다.
Building a List from Scratch
리스트를 생성하는 방법은 두 가지가 있는데,
첫번째는 대괄호를 그냥 만들어 변수에 할당하는 방법과
list() 함수를 이용해 생성자 형태로 만들 수 있다.
리스트에는 보통 같은 종류의 변수가 있는 경우가 많다.
하지만 꼭 그럴 필요는 없다.
Is Something in a List?

'in' , 'not in' 연산자는 문자열에서의 쓰임과 비슷하다.
있는지 없는지 여부에 따라 참, 거짓을 반환한다.
조건문을 굳이 쓰지 않아도 되서 편하다고 생각된다.
Lists are in Order
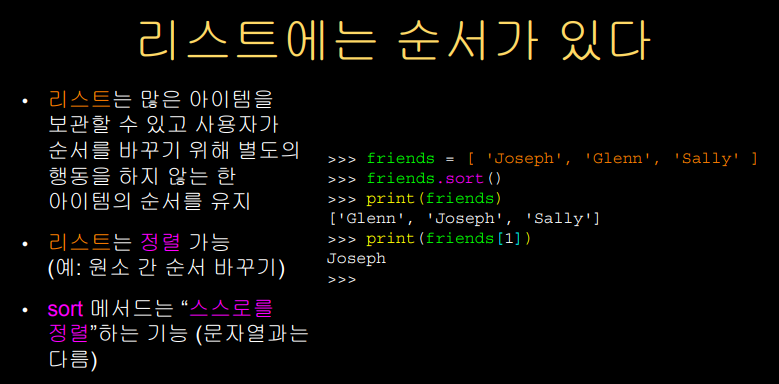
리스트에는 order 순서가 있고 sortable 정렬가능하다.
여기서 리스트의 많은 장점의 존재를 알 수 있는데,
우리가 컴퓨터에 원하는 많은 일 중에
하나가 바로 정렬 sorting 이다.
모든 원소를 살펴보고 추가하고 정렬한다.
리스트에는 이러한 메서드가 내장되어 있는데,
sort 메서드가 있다.
문자열 3개로 이루어진 리스트를 sort 하면
알파벳 순서로 변형시켜준다.
Built-in Functions and Lists
이것 말고도 리스트를 입력인수로 하는 여러가지 함수가 있다.
원소의 개수를 세어주는 len 함수,
리스트 내에서 최댓값을 알려주는 max 함수,
모든 값의 합을 구해주는 sum 함수 등등
평균을 내고 싶은 경우 sum함수와 len 함수를 이용해서
전체합을 리스트의 길이로 나누어 쉽게 구할 수 있다.
아마도 이런 함수들의 내부를 뜯어보면,
우리가 이전에 반복문을 이용해 만들었던 루프와 비슷할 거다.
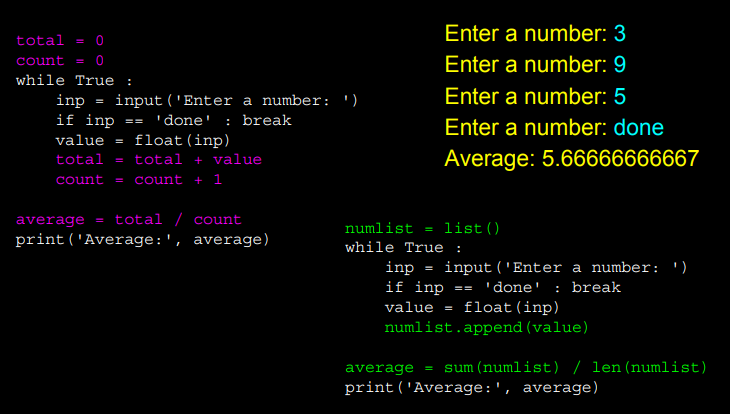
위 슬라이드를 보며 기존 방식으로 반복문 루프를 이용해
변수를 만들어 각각을 계산하고 평균을 구하는 방법과
리스트와 메서드를 이용해 평균을 구하는 방법 두 가지를 비교해보라.
차이점 생각해보기
만약 숫자의 개수가 100만개, 10억개 처럼 많은 경우에
모든 숫자가 메모리에 동시에 저장되어 있어야 하는데
첫 번째 기존 방식은 계산을 바로바로 하기 때문에
숫자가 10억개라도 메모리를 많이 차지하지 않을 거이다.
반면에, 두번째 방식은 더 많은 메모리를 사용하게 될 것이다.
그렇다면 반대로 두번째 방식이 가지는 이점은 없을까?
- 입력값을 모두 저장해두기 때문에 추가적으로 계산이 가능할 수 있다.
입력값을 정렬하거나, 중복을 제거하거나 하는 등 코드의 확장이 훨씬 간편할 수 있다.
입력된 숫자들이 리스트에 저장되어 있기 때문에 입력값을 확인하거나, 계산이 맞는지 확인하기 쉽다.
Strings and Lists
문자열과 리스트는 어떻게 연관되어 있는가?
일단 둘은 모두 인덱스가 0으로 시작하고
대괄호 연산자를 이용해 여러가지 일을 해낼 수 있다.
리스트와 문자열을 결합하여 실제 사용하는 경우가 꽤 있다.
Split Function
split 함수가 하는 역할은
문자열을 살펴보고 공백을 찾고
공백을 기준으로 문자열을 여러 조각으로 나누어
분리된 각 조각으로 구성된 리스트를 반환하는 것이다.
문자열을 읽고 분리하는 작업은
문자열 라이브러리 메서드인
find와 slice 등을 이용해서도
비슷한 일을 할 수 있다는 것을 이미 우리는 알고 있다.
하지만, split 함수를 사용하는 것이 일반적이다.
(활용가능성이 더 높기 때문이 아닐까 싶다.)
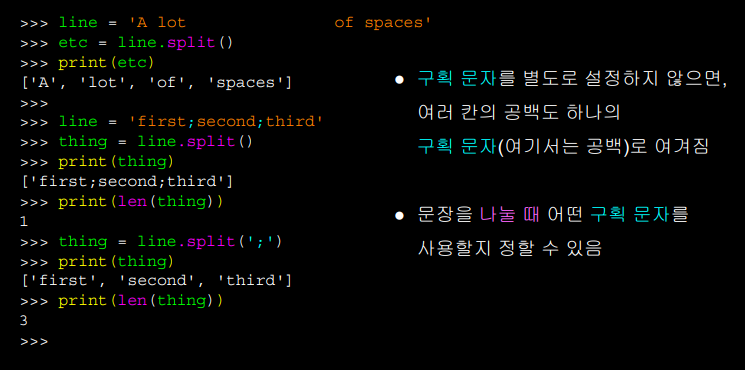
두 단어 사이에 공백이 길어도
split 함수를 사용하면 white space 공백에 대해서는
빈 공간에 대해서 탭이나 줄바꿈, 또 다른 문자에 대해서도
기본적으로 분할할 수 있다.
하지만, 우리가 다루는 데이터의 상당수는
다른 문자를 기준으로 분할하게 될 것이다.
예를 들어 세미콜론을 기준으로 분할 할 수 있다.
그치만 공백을 기준으로 나눌 때 보다 똑똑하게 나누진 않는다.
연속적으로 많을 때는 공백과 달리, 전부 분할구간으로 여길 것이다.
The Double Split Pattern
때로는 조금 더 깊이 파고들어가,
한번 분할한 결과물을
다른 구획문자를 기준으로 또 분할하기도 한다.
Exercise
Exercise 1 : Guardian pattern
guardian pattern 과 short circuit evaluation
보호 패턴과 단축경로 평가
case 1)
han = open('mbox-short.txt')
for line in han:
line = line.rstrip()
wds = line.split()
#guardian pattern a bit stronger
if len(wds) < 3 :
continue
if wds[0] != 'From' :
continue
print(wds[2])case 2)
han = open('mbox-short.txt')
for line in han:
line = line.rstrip()
wds = line.split()
#guardian in a compound statement
if len(wds) < 3 or wds[0] != 'From' :
continue
#wrong guardian compound statement(order error)
#short circuit evaluation
#if wds[0] != 'From' or len(wds) < 3 :
# continue
print(wds[2])
case 1 에서는 wds가 빈칸으로 있을 때 나타나는 에러를 해결하기 위해 guardian pattern 을 적용해 3 이하일 땐 스킵하도록 했다.
case 2 에서는 이를 원래 조건과 guardian pattern 조건을 compound 해서 에러를 해결했는데 이렇게 하는 경우 두 조건을 따로 하는 것보다 compound 할 때, 훨씬 더 빠르게 작동할 수 있다고 한다.
이를 단축경로 평가라고 한다고 한다. 다만 이 단축경로 평가를 사용할 때는 and로 묶여 있는지 or로 묶여있는지 그리고 또 앞 조건과 뒷 조건의 순서도 중요하다.
case 2 에서 주석에 적어놓았듯이, 만약에 조건의 순서가 바뀐다면 똑같이 에러가 발생할 것이다.(or 연산자의 경우 앞이 참이면 뒤 조건은 무시하기 때문에)
Exercise 4
8.4 Open the file romeo.txt and read it line by line. For each line, split the line into a list of words using the split() method. The program should build a list of words. For each word on each line check to see if the word is already in the list and if not append it to the list. When the program completes, sort and print the resulting words in python sort() order as shown in the desired output.
You can download the sample data at http://www.py4e.com/code3/romeo.txt
case 1)
filename = input('Enter file : ')
fh = open(filename)
lst = list()
for line in fh :
line = line.rstrip()
line = line.split()
for word in line :
if word not in lst :
lst.append(word)
lst.sort()
print(lst)case 2)
filename = input('Enter File :')
filehand = open(filename)
lst1 = filehand.read()
lst1 = lst1.split()
lst2 = list()
for word in lst1 :
if word not in lst2 :
lst2.append(word)
#error occur
#print(lst2.sort())
lst2.sort()
print(lst2)제일 오래거렸고 왜 에러가 나는지 알 수가 없어 계속 답답했다.
결국엔 discussion을 보고 해답을 찾을 수 밖에 없었다.
두 가지 정도 내가 생각해내지 못한 문제점이 있었는데,
그 중 첫번째는, in/not in 연산자를 활용하는 것 이었다.
내가 맨 처음 시도한 방법은 이중 for 루프를 이용해 원소하나씩을 일일이 비교해 unique한 word를 찾아내려고 노력했다. 하지만 in/not in 연산자를 사용하면 그냥 통째로 비교할 수 있었다.
두번째는, sort 메서드에 대한 이해 부족이었다.
sort 메서드는 반환값이 None 이다!
sort 메서드는 정렬을 해주는 역할 뿐이지 정렬된 것을 반환하지 않는다. 때문에, 계속 print(lst2.sort()) 를 해서 None을 출력했다. 메서드에 대한 이해가 부족했다.
Exercise 5
8.5 Open the file mbox-short.txt and read it line by line. When you find a line that starts with 'From ' like the following line:
From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16 2008
You will parse the From line using split() and print out the second word in the line (i.e. the entire address of the person who sent the message). Then print out a count at the end.
Hint: make sure not to include the lines that start with 'From:'. Also look at the last line of the sample output to see how to print the count.
You can download the sample data at http://www.py4e.com/code3/mbox-short.txt
filename = input('Enter Filename : ')
fhand = open(filename)
count = 0
for i in fhand :
i = i.split()
if len(i) < 1 :
continue
if i[0] == 'From' :
print(i[1])
count = count + 1
print("there were", count, "lines in the file with From as the first word")시행착오가 없진 않았지만, 비교적 빠르게 그리고 온전히 나의 힘으로 문제를 풀어낼 수 있었다.
내가 겪은 시행착오를 회고해보자면, len(i) < 1 : guardian pattern을 뺴먹어서 에러가 났던 점이었는데, 만약 ex1 예제를 하지 않았다면 조금 해맸을수도 있었겠다.
또, count = count + 1 코드의 위치를 조건문 위에다가 놓아서 처음에 count가 2070개가 나왔다.. count 변수를 어떤 목적으로 생성했는지 다시 생각해보고 무사히 수정했다.
Quiz
이상 없음.
