PY4E Ch.6 Strings
chapter 6 에서는 문자열에 대해 더 자세히 배워볼 예정이다.
Looking Inside Strings
Indexing

문자는 기본적으로 좌표? 인덱스?를 가진다.
이 인덱스는 0부터 시작한다.
인덱스 연산자는 대괄호 [] 이다.
인덱스 연산자를 이용하여 문자열 안의 문자를 인덱싱할 수 있다.
대괄호 안에 들어갈 수 있는 인덱스 값은 정수이다.
정수가 다 들어갈 수 있고 0에서 시작한다.
인덱스는 연산자이다.
문자열 변수의 마지막에 대괄호를 적는
인덱스로 계산 가능한 표현식을 사용할 수 있다.
(예 : x = 2, x = x - 1)
A Character Too Far

하지만, 문자열의 길이보다 긴 인덱스로 코드를 작성할 수는 없다.
위 슬라이드에서 zot는 세 문자를 포함하는 문자열이다. 이때, 세 문자의 인덱스는 각각 0, 1, 2로 인덱스 5는 찾을 수 없을 것이다.
따라서, indexerror를 출력하게 된다.
문자열에서 어떤 것을 꺼내려면
시작 전에 조심해야 한다.
대부분 허용되지만,
이처럼 인덱스 오류가 발생하는 것은 허용하지 않는다.
String Have Length
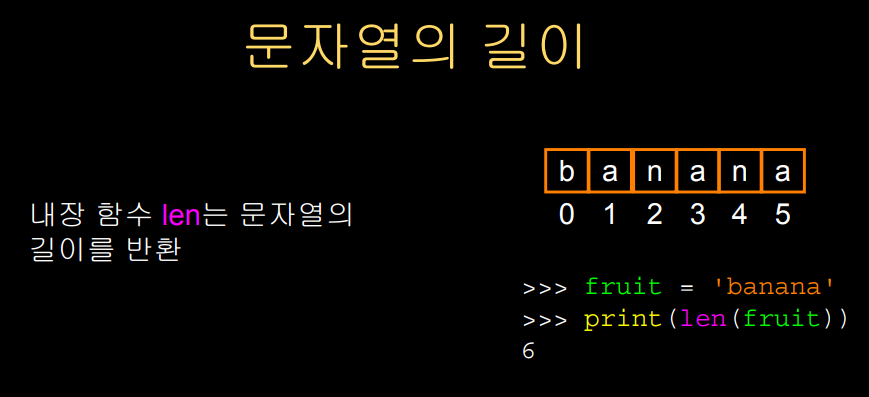
인덱스 오류를 범하지 않기 위해 우리는
문자열이 얼마나 긴지 알아야 하는 경우가 있다.
이 때, 문자열의 길이를 len 함수를 통해 알 수 있다.
문자열 변수를 전달해서 len 함수 안의 매개변수를 전달하면 문자열의 길이를 반환한다.
Looping Through Strings
그럼 이제 문자열을 가지고도
간단한 루프를 만들 수 있다.
while loop

while 루프를 적으면 반복변수가 fruit의 길이보다 작은 동안 실행된다.
길이가 6인 것을 상기하면,
반복변수는 0~5번 까지 값을 갖게 된다.
기본적으로 불확정 indefinite 루프이지만,
반복값을 신중히 설계하여
루프를 실행하는 데 성공했다.
for loop

유한루프 definite loop를 이용할 수 도 있다.
일반적으로 while 루프와 for 루프 모두 사용할 수 있고
그 외 조건이 같다면 for 루프를 사용하는 것을 더 선호하는 편이다.
두 루프를 비교해보면 for 루프가 훨씬 깔끔하다는 것을 알 수 있다.
루프를 실행하면서 index에 해당하는 숫자를 실제로 알아야하는 것이 아니라,
문자열의 각 문자를 순서대로 확인만 하고 싶은 것이라면 그냥 for 루프를 이용하는 것을 권장한다.
for 루프에서는 관리해줘야하는 반복변수 iteration variable을 굳이 만들지 않아도 된다.
Indexing & Loop
인덱싱과 반복과 루프 챕터에서 배웠던 방법을
같이 활용하면 문자열에서 할 수 있는 대부분의 것들을 할 수 있게 된다.
가장 큰 문자를 찾거나,
가장 작은 문자를 찾거나,
문자가 존재하는지 탐색하거나,
banana 라는 단어에서 a 가 몇개인지를 찾거나 등 을 셀 수 있다.
Looking Deeper into 'in'(반복문에서 in과 문자열)

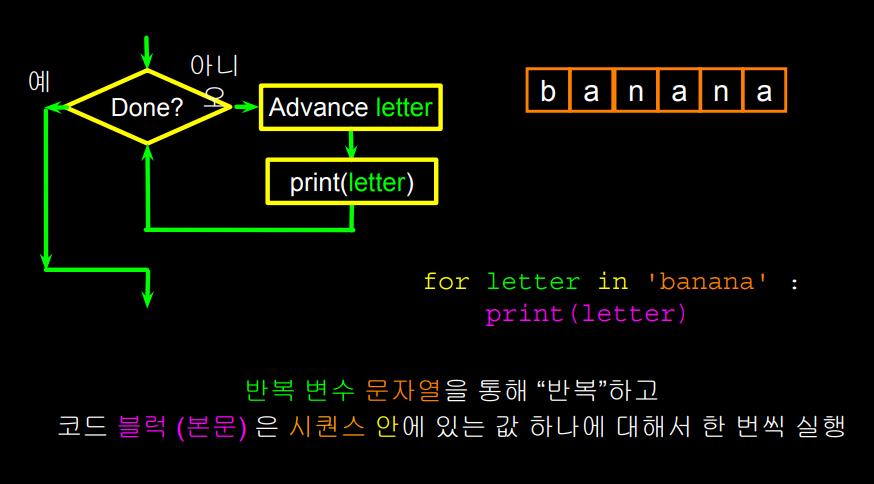
위 슬라이드에서 볼 수 있듯이,
반복변수 letter은 banana 문자열에 대해
변수 letter의 값을 각 특정 문자로 바꾸면서 루프를 실행한다.
for 구문이 많은 것을 해결해준다.
루프를 몇번 반복해서 실행할지,
루프가 끝났는지 여부를 결정하고,
루프 안의 문자를 자동적으로, 또 연속적으로 이동시킨다.
More String Operation
Slicing Strings
슬라이싱은 문자열의 조각을 슬라이스해서 가져오는 것이라고 생각하자.
슬라이싱을 할 때에도 대괄호 연산자를 사용한다.
s sub through 4 는
s[0:4] 를 읽는 방식이다.
콜론을 through로 보고 대괄호를 sub로 읽었다.
주의해야할 점이 있는데,
바로 마지막 인덱스를 포함하지 않는 것이다!!
0으로 시작하는 것도 직관적이지 않은 것과 마찬가지이다.

위 슬라이드를 보면서 조금 이상한 점이 없었나?
세번째 예제인
print(s[6:20]) 을 가만 보면
문자열의 length가 12임에도 불구하고
인덱스 6에서 20까지를 요구하면
20개의 문자가 없어서 오류를 일으키고 말 것 같지만,
그렇지 않고 알아서 끝에서 멈추어 문자열의 마지막까지만을 반환해준다.
Slicing Strings2
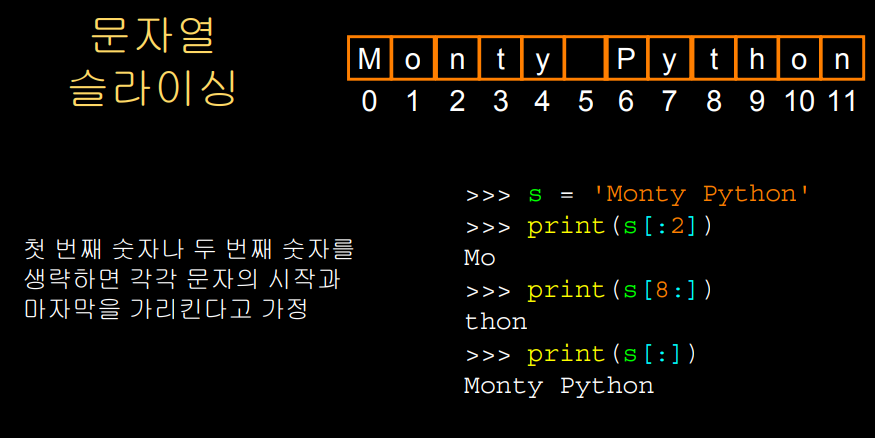
또, 대괄호 콜론의 앞이나 뒤 인덱스를 생략해도 무방하다.
다만 생략하게 되면 첫번째나 마지막 인덱스라고 가정하게 된다.
자주 쓰일까 싶지만, s[ : ]는 s의 처음부터 끝까지 문자열 전체를 반환할 것이다.
Using 'in' as a Logical Operator
in 을 논리연산자로 다르게 사용해볼 수 있다.
for 루프에서는 반복문의 구조의 일부로 사용했지만, if 문에서 in 을 사용하면 논리연산자로 사용할 수 있다. 논리연산자이기 때문에 참 또는 거짓을 반환한다.
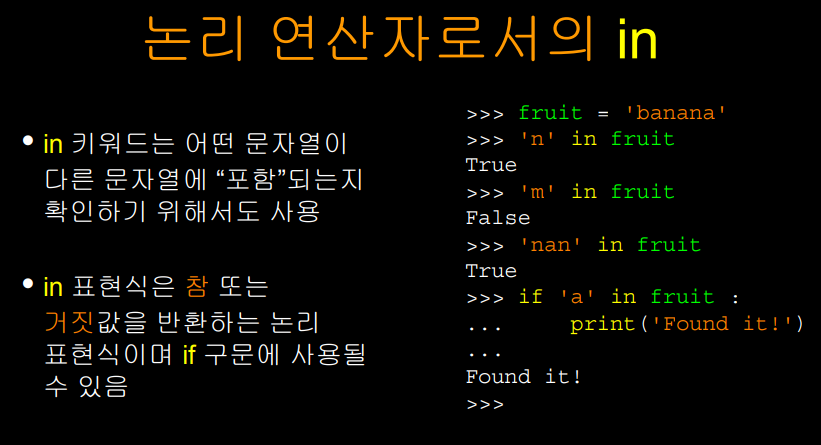
특정 문자가 문자열에 포함되는지,
또 심지어 문자 하나가 아닌 문자열 조각이
해당 문자열에 포함되는지 여부도 확인할 수 있다.
in 은 이처럼 특별한 상황에서 연산자로 사용될 수 있다.
String Comparison
문자열을 비교할 수 있다.
여기서 말하는 비교는 일반적으로
사전순서상 앞인지 뒤인지를 의미하는 것이다.

자주 사용될까 싶긴하지만,
주어진 문자열을 특정 문자열과
사전순서상 비교를 통해 조건문을
설정할 수 도 있다.
(여태 이런식의 조건문을 접해본적이 없는 거 같아 신기하다. 이런식으로도 할 수 있구나 하고 넘어간다.)
String Library
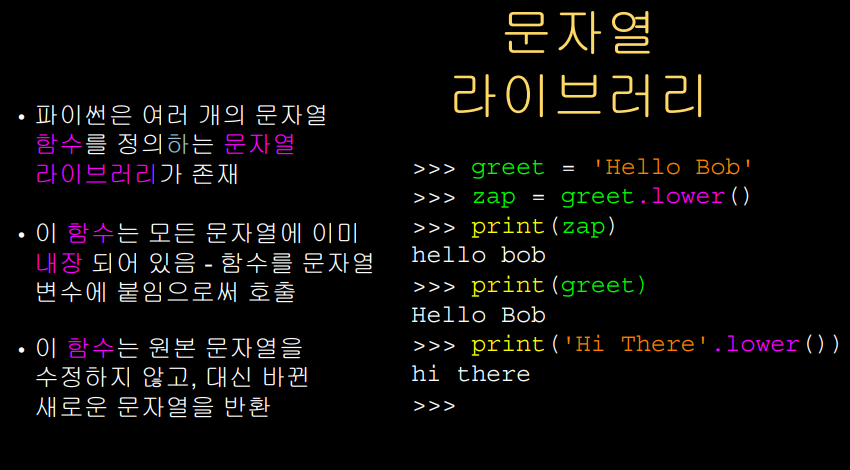
파이썬에서 문자열은 객체이고,
문자열 객체는 메소드(클래스 내 내장함수)를 포함하고 있으며,
이런 문자열 메소드들은 문자열 클래스(str)에서 정의되어 있고,
문자열 메소드나 클래스들은 문자열 라이브러리의 형태로 모여있다.

라이브러리 > 클래스 > 메소드 > 객체
포함관계로 보면, 요런 느낌으로 나는 이해했다.
Method
메소드는 특수한 형태의 함수 호출이다.
함수에 매개변수를 전달하는 대신
" 객체.메소드이름()"
이렇게 적는 것으로 일어나는 함수 호출이다.
예를 들어, len 함수는 객체지향함수가 아니다.
len(X)는 객체지향이 아니다.
객체지향함수 메소드라면,
X.len() 가 될 것이다.
위 슬라이드에서 마지막 대화를 살펴보면 알 수 있듯이,
상수 constant 역시 개체이다!..
따라서 .lower()를 받아들여서 'hi there'를 출력한다.
문자열 변수와 문자열 상수에 내장되어 있는 메소드이다.
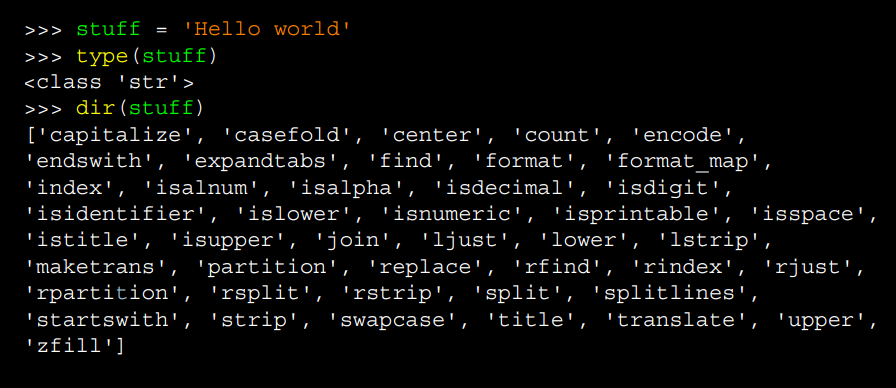
문자열에 type 함수를 사용하면
<class 'str'> 이 출력될 것이다.
클래스 str은 객체지향과 관련이 있는데,
클래스는 객체지향 개념이다.
문자열이므로 dir 함수를 사용할 수 있는데,
dir 함수는 문자열로 할 수 있는 모든 method들을 보여준다.
X.메소드()로 적어서 말이다.
자, 이제 무엇을 할 수 있는가
여기에 있는 모든 것이 X에 대해 실행할 수 있는 것이다.
이것들은 내장되어 있고 문자열을 생성할 때
함께 따라오는 것들이다.
물론 파이썬은 온라인 문서에 이 모~든 문자열 메소드와 각 메소드가 무엇을 하는지와
어떻게 작동하는지, 왜 그렇게 작동하는지를
공식문서에 기록해 두었다.
String Library(Common Use)
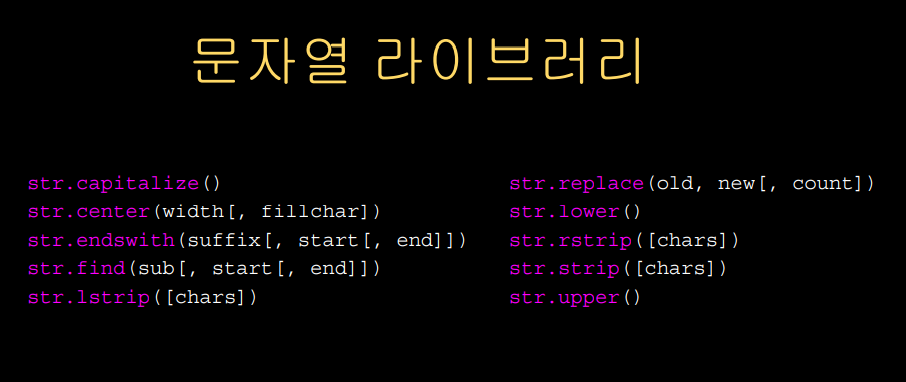
Searching a String

find operation은 sub string을 in a string 에서 찾을 수 있다.
문자열 탐색은 자주 사용되는 기능이다.
Make Everything Upper, Lower Case

대문자 또는 소문자로 바꾸는
upper, lower method 도 있다.
find()를 이용해서 문자열을 탐색할 때,
문자열을 먼저 대문자나 소문자로 변환한 뒤 탐색하면
대소문자 관계없이 문자열 탐색하기 때문에 훨씬 수월하다.
method는 기본적으로 기존 문자열을 바꾸지 않는다.
원본 문자열의 대문자 버전 복사본과 소문자 버전 복사본을 주는 것으로 이해하자.
Search and Replace

replace() 함수를 이용해서 찾아 바꾸기를 실행할 수 있다.
함수 안에 ( a , b ) 를 넣어 문자열 안에
a(탐색 문자열)를 b(대체 문자열)로 바꾸어 줄 수 있다.
Stripping Whitespace

공백은 단순히 띄어쓰기가 아닐 수 있다.
비록 단순 띄어쓰기인 경우가 많기도 하지만,
의도하지 않은 다른 것이 포함되는 경우도 있다.
(예를 들면 딸려오는 탭, 보이지 않는 공백, 새로운 한줄 등)
공백을 없애는 여러가지 방법이 있을 수 있는데,
시작 공백, 끝 공백, 양쪽 공백을 없애는 기능을 나누어 사용할 수 있다.
lstrip()은 문자열의 시작 공백을,
rstrip()은 문자열의 마지막 공백을,
strip()은 양쪽 모두의 공백을 없앤다.
Prefixes

line이 특정 문자열로 시작하는지 물어본다.
이 질문은 참 또는 거짓을 반환한다.
이 메소드로 하여금 if 구문의 조건문으로 활용할 수 있다.
Combine methods to utilize
다양한 메소드들을 결합하여 다양한 기능을 만들어 낼 수 있는데,
그 중 가장 많이 사용되는 기능 중 하나는
parsing and extracting 이다.
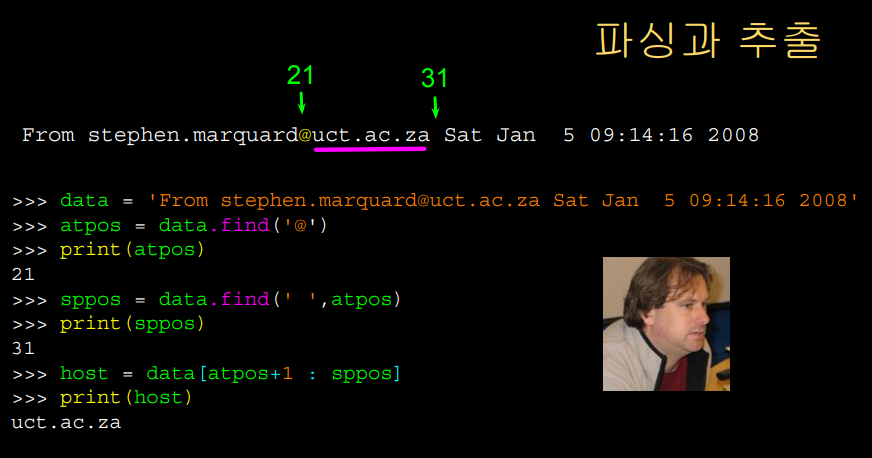
위 슬라이드에서, 우리가 만약 하고 싶은 것을
이메일 주소에서 그의 학교를 발췌하고 싶다고 가정해보자.
먼저 at sign(@)를 탐색해서 찾아야 한다.
sppos = data.find(' ', atpos)
를 실행하면 atpos 사인 이후 공백이 어디에 위치하고 있는지 위치 인덱스를 알 수 있다.
이제 두개의 변수로 @의 위치와 @기호 다음으로 나오는
공백의 위치를 알 수 있다.
인덱스를 활용해 슬라이싱을 이용해 비로소,
학교 주소를 발췌할 수 있다.
practice
parsing number after ":"
text = "X-DSPAM-Confidence: 0.8475"
a = text.find(':')
print(a)
new_text = text[a+1:]
print(new_text)
b = new_text.lstrip()
print(b)
c = float(b)
print(c)
print(type(c))
print(c+1)PS C:\Users\nthin\Desktop\py4e> & C:/Users/nthin/AppData/Local/Programs/Python/Python313/python.exe c:/Users/nthin/Desktop/py4e/ch6.py
18
0.8475
0.8475
0.8475
<class 'float'>
1.8475000000000001
quiz

고백하자면, 또 두번 틀렸고
세번째 정답 선택에서도 확신을 갖고 답을 내지 못했다.
words[7] = '&'이 부분에서 오류가 나타나는 것을 확인했다.
찾아보니, 한번 만들어지면 내부 문자들을 직접 바꿀 수 없는 불변객체이기 때문이라고 한다.
그러면 Connect&Foundation 처럼 출력 되게끔 하려면 어떻게 해야할까?
앞서, 배웠던 String Library를 떠올려보자.
words = words.replace(' ', '&')
print(words)이렇게 코드를 실행하면 replace 메소드를 사용해서
안전하게 변환한 값을 출력할 수 있다.
하지만, replace를 이용해도 원본 문자열을 바꾸지 않고 바뀐 새 문자열을 반환하는 것이기 때문에
반환한 새 결과 다시 words 변수에 넣어줘야 마침내 바뀐 값이 저장된다.
