1. Toy
- 출발지부터 목적지까지 최단 이동 거리찾기
2. 관계형 데이터베이스
- SQL (Structured Query Language) =>> 구조화된 Query 언어
- 저장되어 있는 정보를 필터하기 위한 질문
- SQL >> 데이터베이스 용 프로그래밍 언어!
- 데이터 베이스가 필요한 이유..
데이터 베이스 <> in-memory, File I/O
In-memory는 끄면 사라짐
File I/O는 원하는 데이터만 가져올 수 없고, 항상 모든 데이터를 가져와 서버에서 필터링 해야함.. 서버에 부담
Database는 필터링 외에도 File I/O로 구현이 힘든 관리를 위한 여러 기능을 가지고 있음. 데이터에 특화된 서버
엑셀과 비슷
SELECT * => 모든 Row(열)을 선택해라
FROM A => A table에서
WHERE gender = 'M; => gender가 'M'인 것을
클라이언트 - 서버 - 데이터베이스 3 Tier
클라이언트 => 요청 => 서버 => 쿼리문 => 데이터베이스
기본 명령어 10개 정도만 익히면 좋음~
Select
Where
And, Or, Not
Order By
Insert Into
Null Values
Update
Delete
Count
Like
Wildcards
Aliases
Joins
- Inner join
- Left join
- Right join
Group By
데이터 베이스 생성
CREATE DATABASE 데이터베이스_이름
데이터 베이스 사용
USE 데이터베이스_이름
테이블 생성, 필드와 함께 만들어야 한다
CREATE TABLE user (
id int PRIMARY KEY AUTO_INCREMENT, // Primary key, 자동 증가 설정
name varchar(255), // 필드 이름 name, 최대 255개 문자
email varchar(255) // 필드 이름 email, 최대 255개 문자
);테이블 정보 확인
DESCRIBE user;
mysql> describe user;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(255) | YES | | NULL | |
| email | varchar(255) | YES | | NULL | |
+-------+--------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
Select 선택할 특성, *(와일드 카드)는 전체 선택
From 테이블 이름
WHERE 특성 = 조건, 필터링 역할
부등호 사용 가능
LIKE, \%, * 등을 사용해 특정 값과 비슷한 값들을 필터할 수 있음
WHERE 특성 LIKE "%문자열%"
값이 일치하는 데이터를 찾을 때는 IN
WHERE 특성 IN ("값1","값2")
값이 없는 경우를 찾을 때는 IS와 NULL을 같이 사용
IS NULL
반대로 값이 없는 경우를 제외, NOT사용
IS NOT NULL
정렬
ORDER BY 특성 기본 오름차순
ORDER BY 특성 DESC 내림차순
돌려받을 데이터의 개수 제한
LIMIT 200 데이터 결과 개수를 200개로 제한
유니크한 값들을 받고 싶을 때, SELECT 뒤에 붙여 사용
SELECT DISTINCT
INNER JOIN 서로 공통된 부분으로만 연결 INNER JOIN이나 JOIN으로 사용
JOIN 테이블1 ON 테이블1.특성A = 테이블2.특성B
OUTTER JOIN
LEFT INCLUSIVE LEFT OUTER JOIN, RIGHT OUTER JOIN
INSERT TABLE (Column1, Column2...) VALUES(VALUE1, VALUE2);
UPDATE Table_name SET Column = "value";
DELETE FROM TABLE_NAME WHERE ~
min() 최소값
max() 최댓값
count() 개수
avg() 평균값
sum() 합계
LIKE "a%" a로 시작하는 것
LIKE "%a" a로 끝나는 것
LIKE "%a%" a를 포함하는 것
LIKE "_a%" 두번째 글자가 a인것
LIKE "[acs]%" a 또는 c 또는 s로 시작하는 것
LIKE "[a-f]%"a~f로 시작하는 것
LIKE "[!acf]"% a 또는 c 또는 f로 시작하지 않는 것
WHERE Columns IN ('Value1','Value2'); Column에 value1이나 value2를 포함하는 것
WHERE Column BETWEEN A AND B; A와 B 사이의 값을 가진 것
KOREA AS KR KOREA를 KR로 사용할 것임
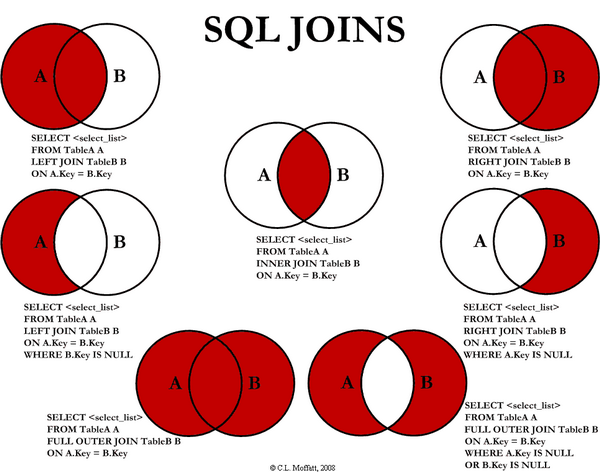
SELECT *
FROM Orders
LEFT JOIN Customers // Table Orders + Table Orders와 일치하는 Table Customers
ON Orders.CustomerID = Customers.CustomerID; // ON 사용FROM TableA
INNER JOIN TableB // 교집합FROM TableA
RIGHT JOIN TableB // TableB와 일치하는 A + 모든 BSELECT COUNT(*), Columns
FROM Columns2
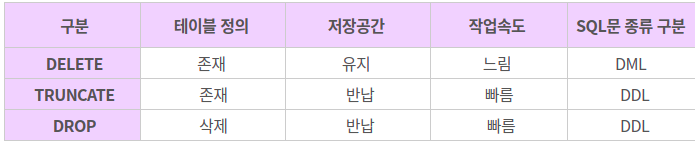
GROUP BY count(*) >> count가 같은 것끼리 그룹화DROP DATABASE testDB 데이터베이스 testDB를 삭제
DROP TABLE A 테이블 A를 삭제
TRUNCATE TABLE A 테이블 A 내부의 모든 것을 삭제
ALTER TABLE-A
ADD Column-NAME TYPE //컬럼 추가
MODIFY COLUMN Column-NAME TYPE //컬럼 type 변경
CHANGE COLUMN1 COLUMN2 TYPE // 컬럼 이름, type 변경
DROP COLUMN Column-NAME // 컬럼 삭제
RENAME TABLE-B // TABLE 이름 변경- ACID(Atomicity, Consistency, Isolation, Durability)
트랜잭션
여러 개의 작업들을 하나의 실행 유닛으로 묶어준 것
트랜잭션은 실패 혹은 성공 두가지 결과만 존재, 중간 과정이 하나라도 실패한다면 트랜잭션 자체가 실패
Atomicity
하나의 트랜잭션 내에서 모든 연산은 모두 성공하거나 모두 실패해야 한다
Consistency
하나의 트랜잭션 전후에 데이터베이스의 일관된 상태가 유지되어야 한다
Isolation
각각의 트랜잭션은 독립적. 서로 연산을 확인하거나 서로 영향을 줄 수 없다
Durability
하나의 성공된 트랜잭션에 대한 로그가 기록되고 영구적으로 남는다. 오류가 발생해도 해당 기록은 영구적이어야 한다
금융계에서는 필수적인 개념
-
SQL(구조화 쿼리 언어) vs NoSQL(비구조화 쿼리 언어)
NoSQL
데이터가 고정되어 있지 않은 데이터베이스 형태
관계형 데이터베이스에서는 테이블 구조(스키마)를 통해 관계들이 어떻게 되어있는지 알 수 있다.
ex) 대표적인 관계형 데이터베이스 MySQL, Oracle, PostgresSQL, MariaDB
NoSQL은 스키마가 없는 것이 아니라, 데이터를 읽어올 때 스키마에 따라 읽어옴(schema on read)
ex) 대표적인 NoSQL MongoDB(문서형 데이터베이스) 등.. -
ACID 성질을 준수해야 하는 경우 >> SQL
-
사용되는 데이터가 구조적이고 일관적이다 >> SQL
-
데이터 구조가 거의 또는 전혀 없는 대용량 데이터를 저장하는 경우 >> NoSQL
-
클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우 >> NoSQL
-
빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 하는 경우 >> NoSQL
3. Schema & Query Design
-
Schema(스키마)는 데이터가 구성되는 방식과 서로 다른 엔티티 간의 관계, 데이터베이스의 청사진
-
Entity 고유한 정보의 단위
-
Field 엔티티의 특성을 설명하는 것, Column, 열
-
Record 테이블에 저장된 항목, Row, 행
-
1:N의 관계
ex) 한명의 강사가 여러 수업을 들어간다
ID(기본 키, Primary Key)를 활용하는 것이 효율적..
다른 테이블에서 테이블의 기본 키를 참조할 때, 해당 키를 외래 키(foreign key)라 함
문제는 이 외래키를 담을 공간이 부족해질 수 있다
한 열에 여러 값을 저장하면, 상수 시간에 대한 검색 손실이 발생 >> 검색이 오래걸린다!
1:N의 경우 N에서 1을 참조하는 것이 좋다 -
N:N의 관계
JOIN table 활용( N:1, 1:N 구조 활용 )






