1. Toy - 31일차
- 구간트리
2. NoSQL
-
MongoDB
대표적인 NoSQL 도큐먼트 DB
도큐먼트 DB는 테이블이 아닌, 문서처럼 저장하는 DB
일반적으로 도큐먼트 DB는 JSON 유사 형식으로 데이터를 문서화
필드-값 형태로, 컬렉션이라는 그룹으로 묶어 관리
NoSQL은 개념이 넓고 다양하다. MongoDB는 NoSQL 중에서도 NoSQL 도큐먼트 DB -
NoSQL 기반의 비관계형 데이터베이스의 사용
1) 비구조적인 대용량의 데이터 저장
=> 정형화되지 않은 많은 양의 데이터가 필요한 경우
2) 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
SQL => 수직적 확장 (ex. 컴퓨터의 성능을 올린다, 16GB 램 사용) => 확장된 데이터베이스의 관리가 어려워질 수 있다
NoSQL => 수평적 확장 (ex. 컴퓨터 대수를 늘린다, 4GB 램 4개 사용)
3) 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 하는 경우
=> 스키마를 미리 준비할 필요가 없어서, 개발을 빠르게 진행할 수 있음
- Atlas Cloud
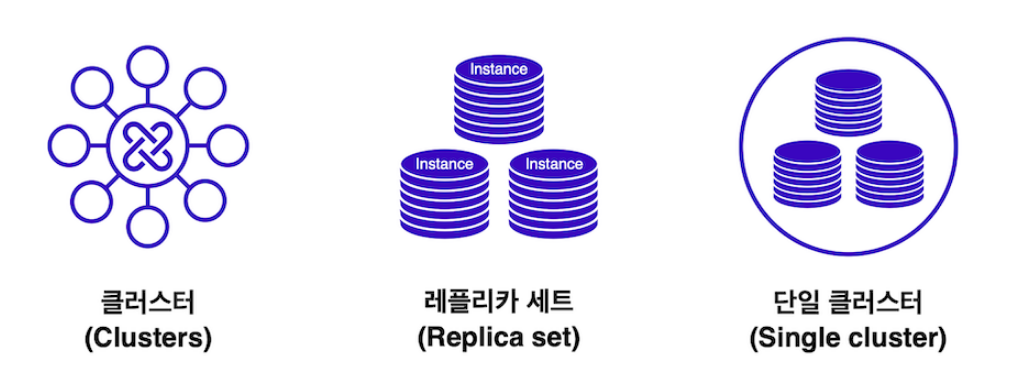
MongoDB는 아틀라스(Atlas)로 클라우드에 데이터베이스를 설정
GUI, CLI로 데이터를 시각화, 분석, 내보내기, 빌드에 사용 가능
클러스트를 배포할 수 있으며, 그룹화된 서버에 데이터를 저장
서버는 레플리카 세트(Replica set)로 구성되며, 레플리카 세트는 동일한 데이터를 저장하는 몇 개의 연결된 MongDB 인스턴스의 모음
변경사항이 있을 경우 데이터의 중복 사본이 레플리카 세트에 저장
레플리카 세트는 데이터의 사본을 저장하는 인스턴스의 모음
=> 인스턴스 중 하나에 문제가 생겨도, 나머지 인스턴스로 작업이 가능
인스턴스란? 로컬 또는 클라우드에서 특정 소프트웨어를 실행하는 단일 머신, MongoDB에서는 데이터베이스
클러스트란? 데이터를 저장하는 서버 그룹
- MongoDB Document
필드-값 쌍
{
name: "kim"
age: 10
}name이란 필드의 값 kim
age란 필드의 값 10
이러한 도큐먼트의 모음을 컬렉션이라 함
-
JSON
{} 중괄호로 시작하고, 끝나야함
필드와 값은 콜론(:)으로 분리, 필드-값 쌍은 쉼표(,)로 분리
필드와 값은 쌍따옴표("") 감싸야 함
읽기 쉽고 편리한 장점
텍스트 형식이기에 파싱이 느리고 메모리 사용이 비효율적
데이터 타입에 제약 -
위 같은 문제점을 해결하기 위헤 BSON(Binary JSON) 도입
이진법을 기반으로 해, 메모리 사용이 효율적이고 빠름, 많은 데이터 타입 사용가능
MongoDB는 JSON형식으로 작성된 것은 모두 추가, 조회 할 수 있고, 내부에서는 BSON으로 데이터를 저장, 사용된다
백업 저장 >> BSON >> 데이터의 관리 효율성이 좋다
데이터 조회, 출력 >> JSON >> 읽고 보기 쉽다 -
명령어 (가져오기, 내보내기)
JSON >> mongoimport, mongoexport
mongoimport --uri"<Atlas Cluster URI>" --drop=<filename>.json"
mongoexport --uri"<Atlas Cluster URI>" --collection=<collection name> --out=<filename>.json
해당 데이터베이스의 컬렉션 이름, 파일이름까지 정확히 작성해야함
BSON >> mongorestore, mongodump
mongorestore --uri"<Atlas Cluster URI>" --drop dump // drop 쿼리문 선택적 사용
mongodump --uri <"Atlas Cluster URI"> -
MongoDB CRUD
Create - 컬렉션에 도큐먼트를 삽입
도큐먼트는 고유한_id값을 가져야함
보통 ObjectId 타입(12byte, 24char)의 값으로 사용
_id필드와 값을 특정하지 않았다면, 자동적으로 생성되며, ObjectId타입이 할당
여러 도큐먼트 삽입db.컬렉션.insert([{test:1},{test:2},{test:3}])
배열에 도큐먼트들을 담아준다, id를 따로 설정안했기에 자동으로 설정되며, 중복되지 않는다.
에러가 발생하기 전까지 동작은 수행, 그 후로는 수행되지 않음
추가할 때 insert의 두번째 인자에 ordered 옵션을 추가해 삽입 순서를 바꿀 수 있다
db.컬렉션.insert({필드 : 값}, {ordered: false})
위와 같이 false가 입력되면 순서에 상관없이 고유한 id를 가진 도큐먼트들은 모두 추가됨
존재하지 않는 컬렉션에 도큐먼트를 삽입하면 생성된다
find - 조건에 따라 데이터 조회
db.컬렉션.find({"필드":"값"})
조건이 없으면 전체 조회
.findOne(), .count()을 활용할 수도 있음
update
updateOne 주어진 기준에 맞는 것중 첫번째 도큐먼트 하나만 업데이트
updateMany 쿼리문과 일치하는 모든 도큐먼트 업데이트
db.zips.updateMany({"필드":"값"},{"$MQL":{"필드":"값"}})
MQL => $inc, $set 등등...
없는 값을 update하면 생성되버린다
배열 데이터에 값을 추가할 때는 $push
delete
deleteOne >> _id값을 사용하는 것이 좋은 방법
deleteMany
db.컬렉션.deleteMany({'필드':'값'})
나머지는 기존과 동일
drop() >> 컬렉션 삭제
review
- 데이터베이스를 쓰는 이유
=> 영속성, 프로그램이 꺼져도 남아있길 바람
=> 변수나 기타방법보다는 파일 시스템이나 데이터베이스를 써야함
=> 파일 시스템의 단점
데이터의 백업이 필요하다
데이터가 항상 같아야 하는데 그것이 어렵다
데이터에 접근하기 어렵다
보안 문제
데이터에 동시에 접근하는 것이 불가능하다
데이터베이스란!
관련된 데이터들의 집합이고, 공유되어 진다
다양한 사용나 프로그램에서 접근된다
DBMS란 DB를 관리하는 프로그램
보통 mongoDB가 직관적!
SQL은 1970년대에 생겨난 개념, SEQUEL(Structured Engilsh Query Language)가 생겨남
NoSQL(Not only SQL)
SQL의 대표주자들
DB2 and Informix Dynamic Server -IBM
RDBMS - Oracle
SQL server and Access - MS
MySQL, PostgreSQL - Open source
NO-SQL의 대표주자들
Key-Value store : Redis, Dynamo DB
Document Stores: Mongo DB
데이터베이스
- Normalization / Denormalization (Modeling)
- indexing (색인) : handle slow queies 쿼리가 느려지는 것을 대비
- Distributed Systems: Replicas, Sharding
Replicas
목적 1) 가용성(availability)
req => res => 가 되느냐?
레플리카의 목적이기도 함, 복제본을 둬서 하나가 고장나더라도 사용가능한 상태를 유지하는 것?
목적 2) 확장성(scalability)
데이터의 수용량을 넘어서, 확장을 할 때.. 확장하는 방법
vertical scaling (scale up) 수직적 확장 add more power
=> 비용문제, 확장의 한계
horizontal scaling (scale out) 수평적 확장 buy more << 레플리카
=> 비용이 수직보다는 덜 든다, 한계가 없다, 복잡하다
Sharding
=> 데이터를 조각내서 관리하겠다! 확장성에 속하는 특징
