cf. Deadlock and starvation
Deadlock

앞서서는 Deadlock에 관하여 간단히 교착상태라고 요약해 왔다. Deadlock이란 자원을 요청한 대기 중인 process가 요청한 자원이 다른 process에 의해 점유되어 있고, 이 process들 또한 대기 상태에 빠져 대기 상태를 변경시킬 수 없는 상태를 말한다.
Coffman condition
deadlock은 다음 네 가지 조건이 동시에 성립할 때 발생할 수 있다. (necessary conditions)
1. Mutual exclusion
최소 하나의 자원이 nonsharable mode로 점유되어야 한다.
2. Hold-and-Wait
process가 최소 하나의 자원을 점유한 채 다른 process가 점유한 자원을 추가로 얻기 위해 반드시 대기해야 한다.
3. No preemption
자원들은 선점이 불가능하고, process의 task 종료 이후 자발적인 방출에 의해서만 점유할 수 있어야 한다.
4. Circular wait
waiting process set [p0, p1, p2 ... pn] 에 관해, 임의의 pi 는 p(i+1)이 점유한 자원을 대기하고, pn은 p0의 점유 자원을 대기한다.
cf. Resource-Allocation Graph
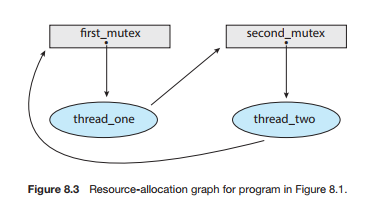
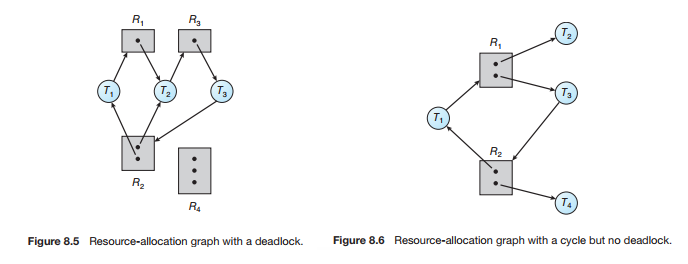
thread T와 resource R을 각각 vertex와 edge로 가지는 그래프 형태로 표현한다.
간단히 정리하면 다음과 같이 생각할 수 있다.
resource-allocation graph 내에 cycle이 존재하지 않다면, deadlock은 발생하지 않는다.
cycle이 존재한다면,
다중 instance에서 thread가 resource를 사용하고 release 가능할 경우 deadlock이 발생하지 않지만,
one instance 상황이나, circular하게 참조 중이라면 deadlock이 발생한다.
Deadlock의 해결: Prevention과 Avoidance
예방과 회피 두 가지 관점에서 교착상태에 대한 해결을 이야기한다.
Deadlock Prevention은 Coffman Condition 중 어느 하나의 필요조건을 성립하지 않도록 보장하는 방식의 예방 기법이다.
Deadlock Avoidance는 process가 사용할 자원에 대한 부가적인 정보의 제공을 요구한다.
Deadlock Prevention
1. Mutual exclusion
최소 하나의 자원이 nonsharable mode로 점유되어야 한다.
자원을 공유 가능하도록 sharable resource를 이용한다.
ex. Readonly file
2. Hold-and-Wait
process가 최소 하나의 자원을 점유한 채 다른 process가 점유한 자원을 추가로 얻기 위해 반드시 대기해야 한다.
모든 자원에 대해 한 번에 요청하도록 강제시키도록 보장한다.
이로써 요청 동안 다른 자원을 점유하고 대기하지 않도록 한다.
(다만 이러한 방법은 자원 사용률을 낮추기 때문에 이론적인 policy에 그친다.)
3. No preemption
자원들은 선점이 불가능하고, process의 task 종료 이후 자발적인 방출에 의해서만 점유할 수 있어야 한다.
대기 중인 process들 중 일부에게는 relinquish를 강요하도록 한다. 일부 process는 점유 중인 자원을 기부하여 rollback되어 다른 process가 자원을 점유하여 수행하도록 하는 방식으로, 선점형 스케줄링과 같은 방식으로 적용할 수 있다.
4. Circular wait
waiting process set [p0, p1, p2 ... pn] 에 관해, 임의의 pi 는 p(i+1)이 점유한 자원을 대기하고, pn은 p0의 점유 자원을 대기한다.
자원을 오직 순서대로 할당하도록 policy를 수립하여 적용하는 방식이다.
ex. 모든 자원에 고유한 번호를 부여하고, 항상 번호가 낮은 순서대로 요청하게 한다.
Deadlock Avoidance
Deadlock Avoidance 는 시스템이 Deadlock이 발생할 가능성이 있는 상태를 사전에 감지하고 피하는 기법으로, Safe State(안전 상태)를 유지하는 방식으로 자원을 할당하여 Deadlock을 회피하는 형태로 수행된다.
cf.
Safe state모든 프로세스가 Deadlock 없이 실행을 마칠 수 있는 상태
Banker's Algorithm
Banker's Algorithm은 process가 자원을 요청 시 바로 할당해 주는 것이 아니라,
요청 승인 시 시스템의 Safe State 에 대한 검사를 통해 승인하는 방식으로 처리한다.
원리
현재 할당된 자원(Allocation)과 프로세스의 최대 요구량(Max)을 추적한다.
이 Allocation과 Max 를 통해 자원에 관련하여 앞으로 필요한 요청 Need를 계산할 수 있다.
Need = Max - Allocation
현재 가용한 자원 Available에 대해 수행 가능한, 즉 Need를 충족할 수 있는 Ti에 대해 요청을 수행한다.
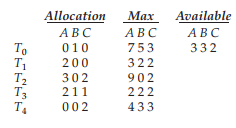
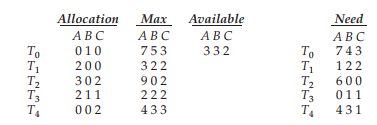
((A, B, C)에 대해 (3, 3, 2) 가용 상태에 대해,
-
T1 Need (1, 2, 2)
T1의 요청 (1, 2, 2)을 수행 => T1에 선점되어 할당되었던 (2, 0, 0) 회수되며 가용상태 (5, 2, 2) -
T3 Need (0, 1, 1)
T3의 요청 (0, 1, 1) 수행 = > 마찬가지의 과정으로 (2, 1, 1) 회수되어 가용상태 (7, 3, 3)
마찬가지의 과정을 거쳐,
safe state sequence: <T1, T3, T4, T2, T0> 를 가지게 된다.
Starvation
Starvation은 Deadlock 에 대한 이야기를 할 때 빠지지 않고 등장하는 개념으로 언뜻 동일한 개념처럼 보이나 분명히 다른 차이점이 존재한다.
양자 모두 unbounded waiting에 관한 내용이긴 하나,
앞서 설명해 온 Deadlock의 경우 두 process에 대해 서로가 점유한 자원에 대한 해제를 대기하는 상태를 가리키는 반면,
Starvation 은 공유 자원에 대한 경쟁으로 특정 process가 리소스를 계속 할당받지 못해 무한정 대기하는 상태를 말한다.
cf. 실제 process starvation의 예시: Mars Pathfinder
위 아티클에 대해 요약하여 번역하자면,
NASA의 화성 탐사 임무를 맡은 Pathfinder가 total system resets으로 데이터 손실이 발생했는데, 이를 “software glitches” 와 “the computer was trying to do too many things at once”로 보고했다. 사실, data losses는 발생하지 않았고, collection이 지연되었던 것인데,
.. (중략) ..
After debugging on the Pathfinder replica at JPL, engineers discovered that the cause of this malfunctioning was a
priority inversion problemwhere the higher priority bc_dist task was blocked by the much lower priority ASI/MET task whose solution was priority inheritance.The priority inheritance had been disabled — the flag for the mutex was set to “off” — in VxWorks RTOS pipe semaphores for performance reasons.
.. (중략) ..
Main Cause of Starvation: Priority Inversion
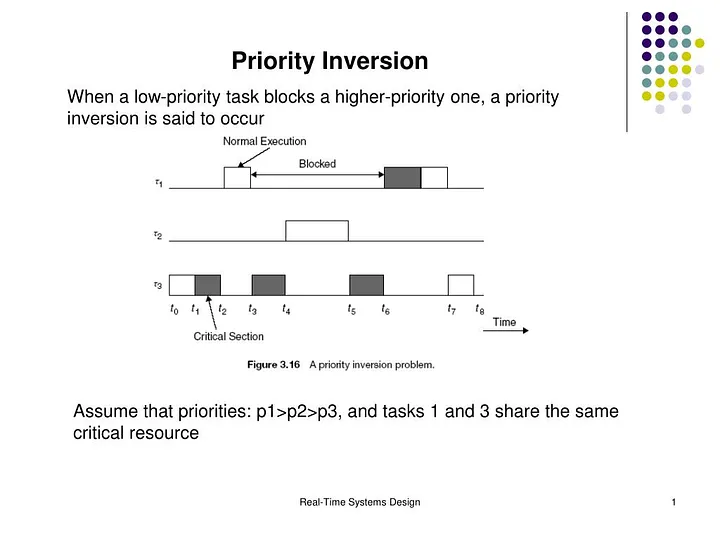
위의 사례에서 찾아볼 수 있듯이, Priority based CPU Scheduling 하에서, 높은 priority를 가진 task가 계속 실행되어 낮은 priority를 가진 process는 Priority Inversion 으로 인해 block 당하여 처리되지 못한 채 할당되지 못해 무한정 대기하게 된다.
Solutions
1. Aging
낮은 priority가 계속해서 우선순위가 밀려 할당을 못 받아 굶어죽지 않게 하기 위해, 이러한 대기 중인 process에 대해 aging을 적용하여 priority를 증가시켜 해당 process의 자원 할당을 보장하도록 하는 기법이다.
2. Fair Lock
Readers-Writers Problem에서,
Writer Priority Policy를 적용 시에 Reader들이 계속 대기하다 starve할 가능성이 있다.
그 역 또한 그러하듯, 많은 Reader 요구로 인해 Writer가 대기하는 상황도 마찬가지이다..
이 때, 이를테면 FIFO 기반의 Fair Lock을 적용하여 배분에 있어서 공정성을 주는 식으로 해결할 수 있다.
3. Priority Inheritance
Pathfinder 예시에 관해, JPL 엔지니어들이 적용한 해법이다.
낮은 priority의 process가 높은 priority의 process가 필요로 하는 리소스를 점유하고 있을 때,
낮은 priority의 process가 일시적으로 높은 priority를 상속받아 먼저 실행되도록 하는 방식으로 작용한다.
이 방법으로, 일시적으로 높은 priority를 부여하여 mutex 를 반환할 수 있도록 한다.
