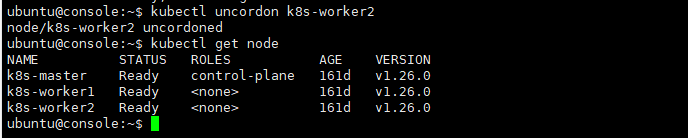
Storage
Storage 참고: https://kubernetes.io/docs/concepts/storage/volumes/
- Volume Mount - emptyDir -> 연결된 대상이 모두 삭제되면 같이 삭제됨.
- Volume Mount - hostPath -> 연결 대상이 삭제되어도 지워지지 않음. 경로는 다를 수 있지만, 이름은 같아야 함.
- Storage Class
- Persistent Volume -> pv라고 부름
- Persistent Volume Claim -> pvc라고 부름
emptyDir volume
- emptyDir 볼륨은 빈 디렉토리로 시작.
- Pod 내부에서 실행중인 애플리케이션은 필요한 모든 파일을 작성.
- 컨테이너 간 데이터 공유, Pod를 삭제하면 볼륨 내용이 손실됨.
- 동일한 pod에서 실행되는 컨테이너 간에 파일을 공유할 때 유용.
hostPath
- 노드의 파일 시스템의 디렉토리나 파일을 컨테이너에 마운트
- 노드에 디렉토리나 .......
pvc
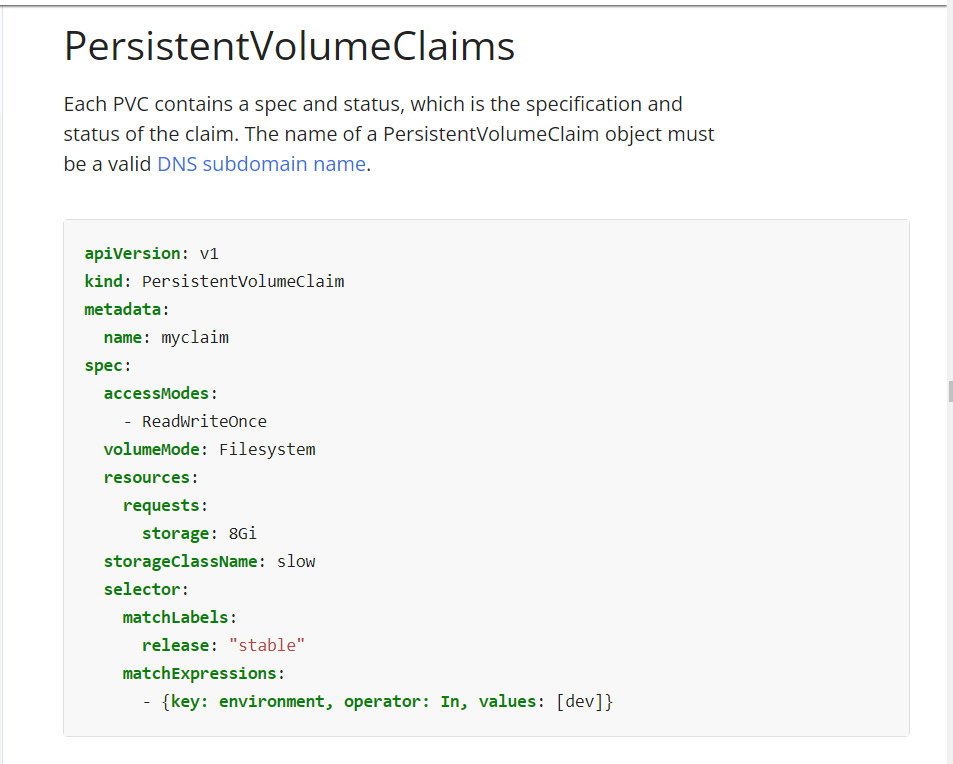
emptyDir Volume을 공유하는 multi-pod 운영
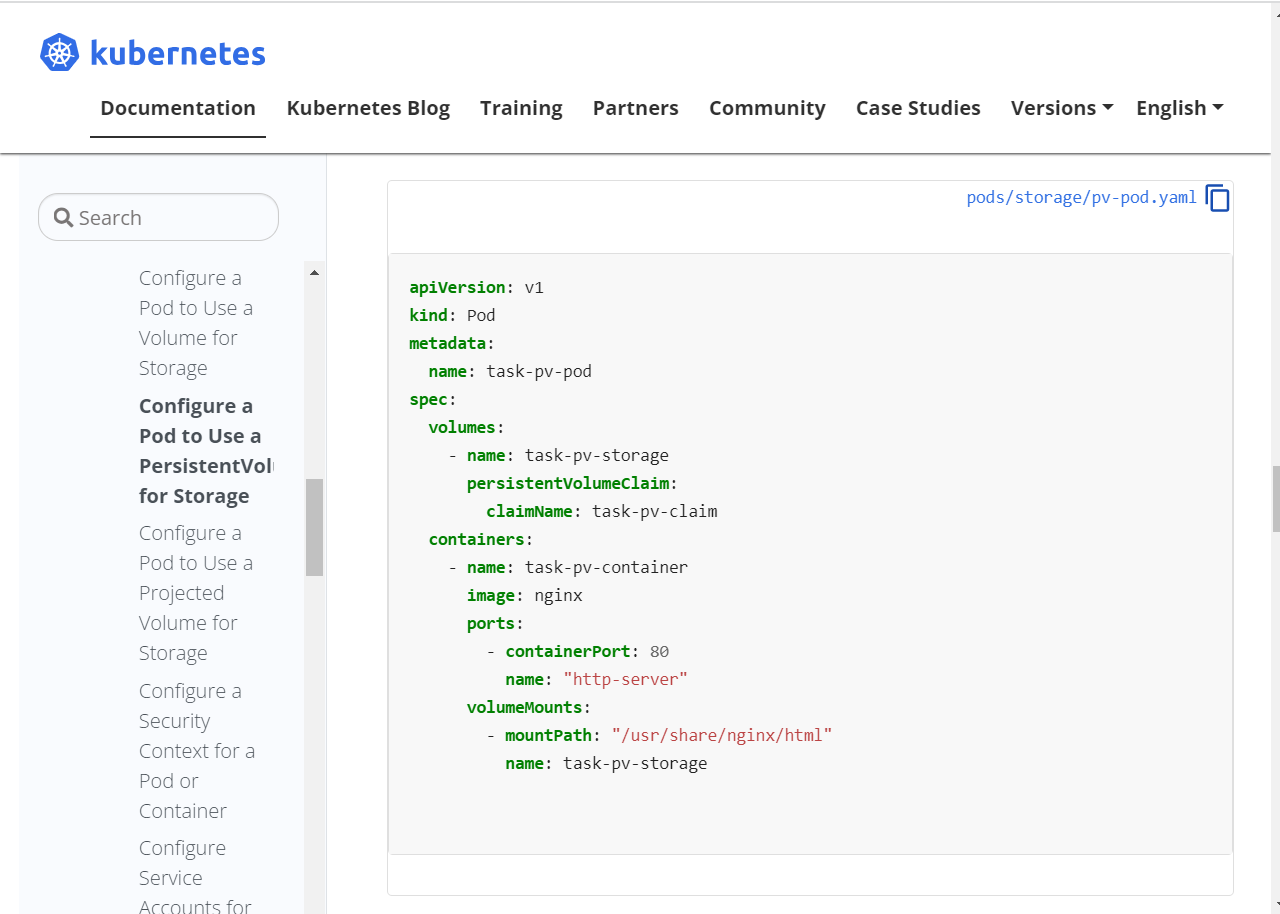
작업 클러스터 : k8s
다음 조건에 맞춰서 nginx 웹서버 pod가 생성한 로그파일을 받아서 STDOUT으로 출력하는 busybox 컨테이너를 운영하시오.
Pod Name: weblog
Web container:
- Image: nginx:1.17
- Volume mount : /var/log/nginx
- Readwrite
Log container:
- Image: busybox
- args: /bin/sh, -c, "tail -n+1 -f /data/access.log"
- Volume mount : /data
- readonly
emptyDir 볼륨을 통한 데이터 공유
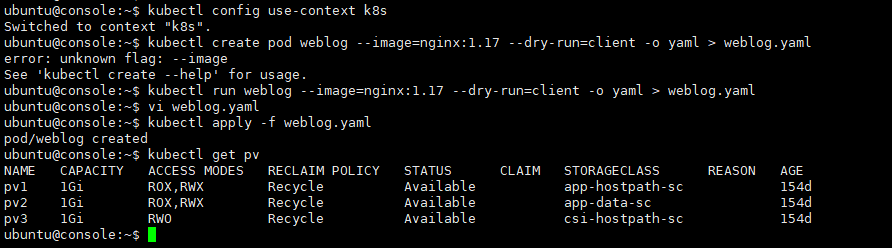
kubectl config use-context k8s
kubectl run weblog --image=nginx:1.17 --dry-run=client -o yaml > weblog.yaml
vi weblog.yaml
kubectl apply -f weblog.yaml
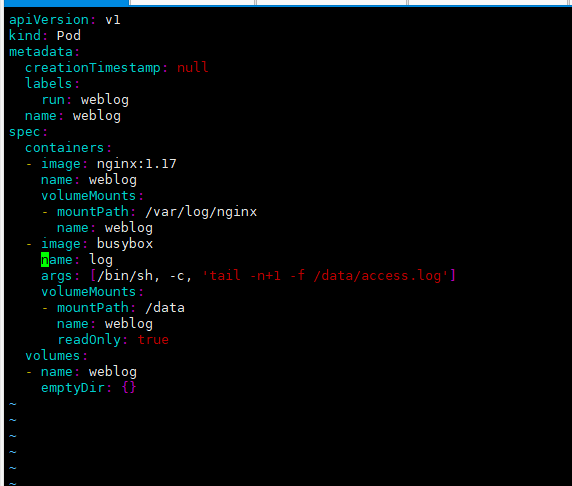
kubectl get pvapiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: weblog
name: weblog
spec:
containers:
- image: nginx:1.17
name: weblog
volumeMounts:
- mountPath: /var/log/nginx
name: weblog
- image: busybox
name: log
args: [/bin/sh, -c, 'tail -n+1 -f /data/access.log']
volumeMounts:
- mountPath: /data
name: weblog
readOnly: true
volumes:
- name: weblog
emptyDir: {}HostPath Volume 구성
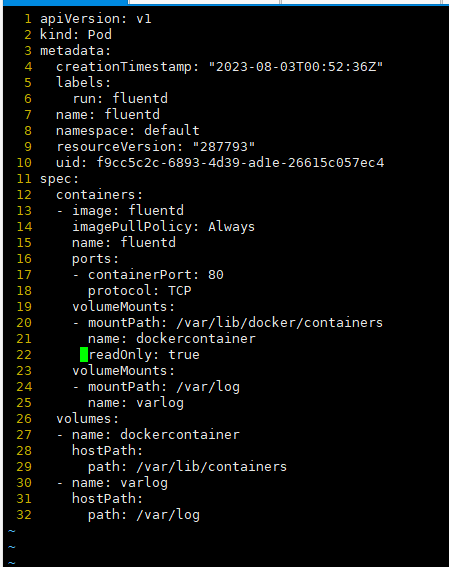
1./data/cka/fluentd.yaml 파일을 만들어 새로은 Pod 생성하세요. (신규생성 Pod Name : fluentd, image : fluentd, namespace : default)
2. 위 조건을 참고하여 다음 조건에 맞게 볼륨마운트를 설정하시오.
1) Worker node의 도커 컨테이너 디렉토리 /var/lib/docker/containers 동일 디렉토리로 pod에 마운트 하시오.
2) Worker node의 /var/log 디렉토리를 fluentd Pod에 동일이름의 디렉토리 마운트하시오.
Persistent Volume 만들기
참고: https://kubernetes.io/docs/concepts/storage/persistent-volumes/
작업 클러스터 : hk8s
pv001라는 이름으로 size 1Gi, access mode ReadWriteMany를 사용하여 persistent volume을
생성합니다.
volume type은 hostPath이고 위치는 /tmp/app-config입니다.
history
kubectl config use-context hk8s
vi pv001.yaml
kubectl apply -f pv001.yaml
kubectl get pv
kubectl describe pv pv001 PVC를 사용하는 애플리케이션 Pod 운영하기
사전 조건
- kubectl config use-context k8s
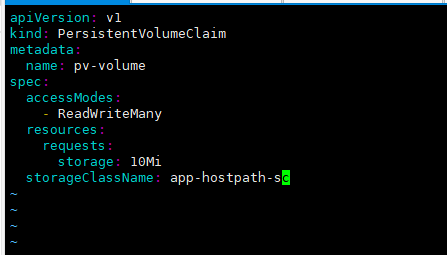
- 다음의 조건에 맞는 새로운 PersistentVolumeClaim 생성하시오.
Name: pv-volume
Class: app-hostpath-sc
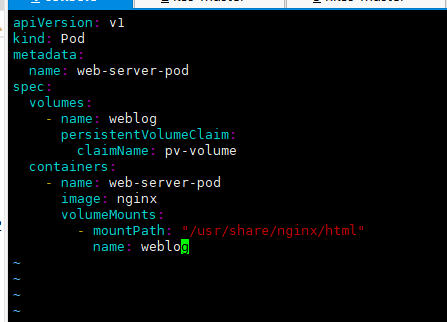
Capacity: 10Mi- 앞서 생성한 pv-volume PersistentVolumeClaim을 mount하는 Pod를 생성하시오.
Name: web-server-pod
Image: nginx
Mount path: /usr/share/nginx/html
Volume에서 ReadWriteMany 액세스 권한을 가지도록 구성합니다.
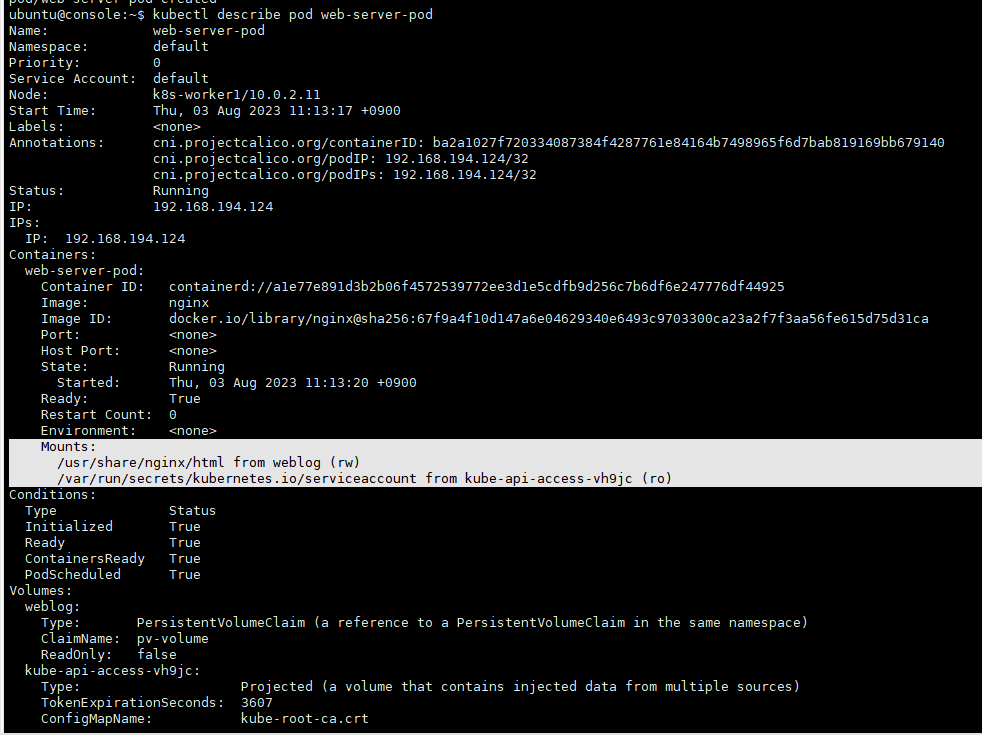
kubectl describe pod 명령어로 확인
history
kubectl config use-context k8s
vi pvc.yaml
kubectl get node
kubectl apply -f pvc.yaml
kubectl get pvc,pv
vi pvc-pod.yaml
kubectl apply -f pvc-pod.yaml
kubectl describe pod web-server-podpvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-volume
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Mi
storageClassName: app-hostpath-scpvc-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: web-server-pod
spec:
volumes:
- name: weblog
persistentVolumeClaim:
claimName: pv-volume
containers:
- name: web-server-pod
image: nginx
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: weblog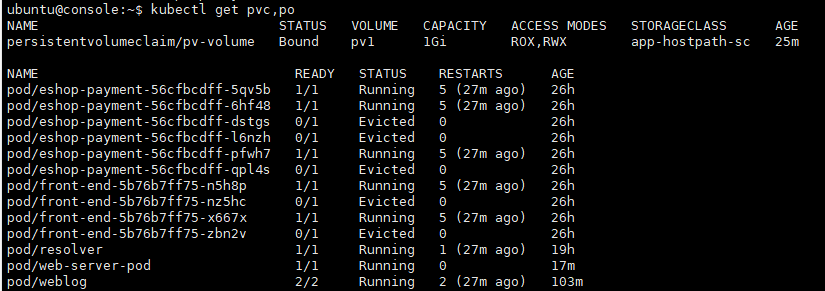
Troubleshooting
Node 동작 문제 해결
kube-proxy 정상적인지
Docker 데몬이 정상적인지
Kubelet 데몬이 정상적인지
coreDNS 정상적인지
참고 사항: https://kubernetes.io/docs/reference/kubectl/cheatsheet/

app Log 모니터링
kubectl logs PODNAME -c CONTAINER_NAME
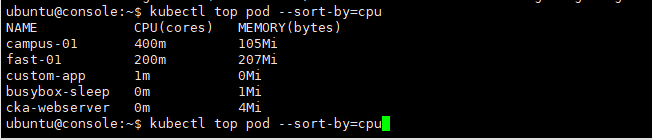
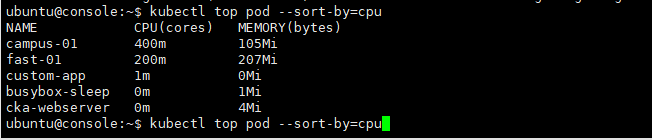
Pod가 사용하는 CPU나 Memory 리소스 정보 보기
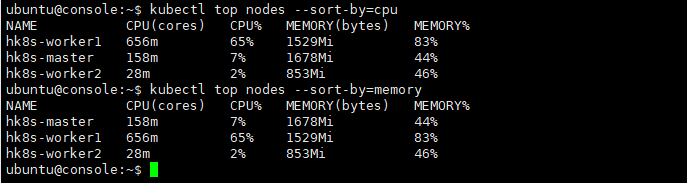
Node가 사용하는 CPU나 Memory 리소스 정보 보기
Application Log 추출하기
kubectl config use-context hk8s
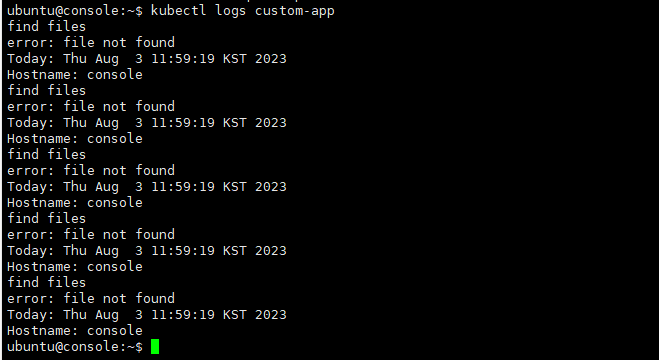
Pod custom-app의 로그 모니터링 후 'file not found' 오류가 있는 로그 라인 추출(Extract)해서
/var/CKA2022/custom-app-log 파일에 저장하시오.
Persistent Volume 정보 보기
kubectl config use-context k8s
클러스터에 구성된 모든 PV를 capacity별로 sort하여 /var/CKA2022/my-pv-list 파일에 저장하시오.
PV 출력 결과를 sort하기 위해 kubectl 명령만 사용하고, 그 외 리눅스 명령은 적용하지 마시오.
history
kubectl config use-context hk8s
kubeclt top pods -l name=overloaded-cpu --sort-by=cpu
echo '`가장 높은 점유율을 가진 pod의 이름`' > /var/CKA2023/custom-app-log 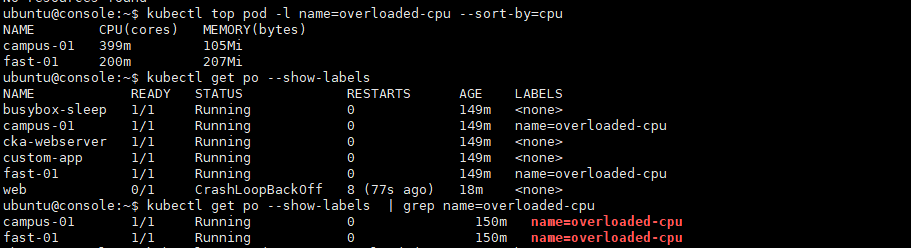
Worker Node 동작 문제 해결
kubectl config use-context hk8s
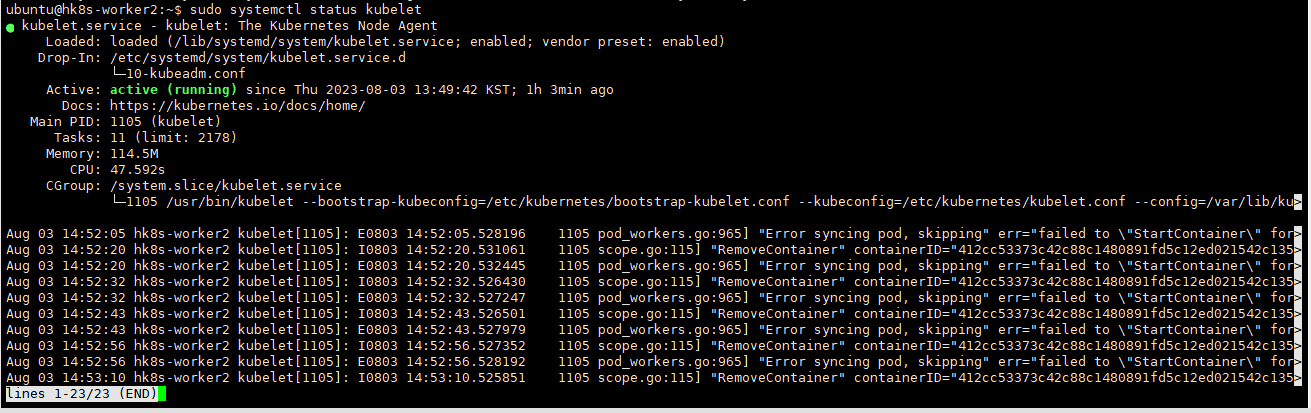
hk8s-worker2 라는 이름의 worker node가 현재 NotReady 상태에 있습니다. 이 상태의 원인을 조사하고 hk8s-worker2 노드를 Ready
상태로 전환하여 영구적으로 유지되도록 운영하시오.
영구적으로 유지해야하므로 start가 아닌, enable --now를 사용해야 함.
history
kubectl config use-context hk8s
ssh hk8s-worker2
sudo systemctl status kubelet
sudo systemctl enalbe --now kubelet
exit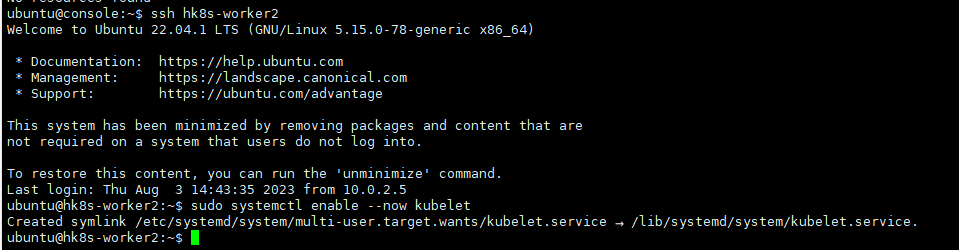
Worker Node 동작 문제 해결
kubectl config use-context hk8s
Worker Node 동작 문제 해결
hk8s-worker2 라는 이름의 worker node가 현재 NotReady 상태에 있습니다. 이 상태의 원인을 조사하고hk8s-worker2 노드를
Ready 상태로 전환하여 영구적으로 유지되도록 운영하시오.
UPgrade
주의 사항: upgrade는 반드시 Master Node에서 작업해야함.
cluster upgrade 참고: https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
순서:
1. 업그레이드 - kubeadm upgrade
2. 버전 확인 - kubeadm version
3. plan - kubeadm upgrade plan
4.
Cluster upgrade
작업 클러스터 : hk8s
마스터 노드의 모든 Kubernetes control plane및 node 구성 요소를 버전 1.27.1 버전으로 업그레이드합니다.
master 노드를 업그레이드하기 전에 drain 하고 업그레이드 후에 uncordon해야 합니다.
"주의사항" 반드시 Master Node에서 root권한을 가지고 작업을 실행해야 한다.
tip: upgrade 관련 명령어 실행시 vi 편집기로 파일을 생성하여 작업하는 것이 좋음.
# replace <node-to-drain> with the name of your node you are draining
kubectl drain <node-to-uncordon> --ignore-daemonsets
# replace x in 1.27.x-00 with the latest patch version
apt-mark unhold kubelet kubectl && apt-get update && apt-get install -y kubelet=1.27.x-00 kubectl=1.27.x-00 && apt-mark hold kubelet kubectl
sudo systemctl daemon-reload
sudo systemctl restart kubelet
# replace <node-to-uncordon> with the name of your node
kubectl uncordon <node-to-uncordon>history
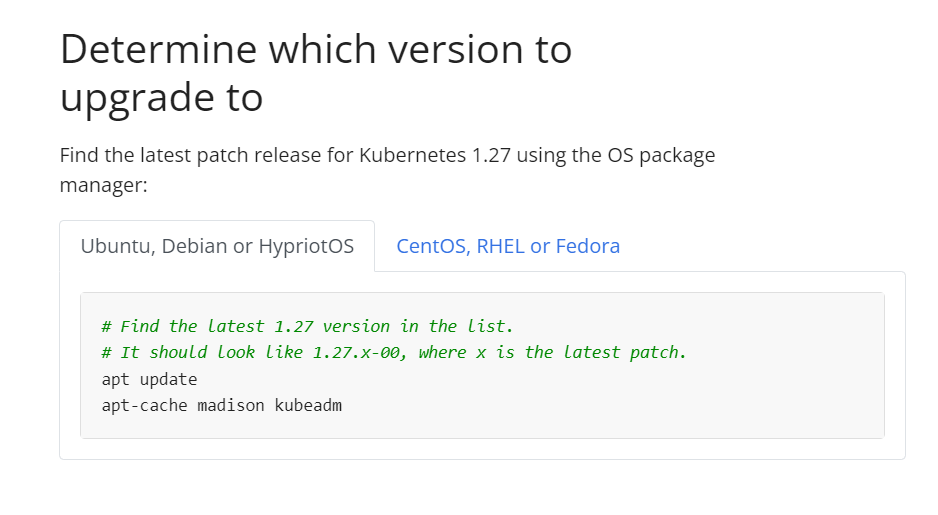
# Find the latest 1.27 version in the list.
# It should look like 1.27.x-00, where x is the latest patch.
apt update
apt-cache madison kubeadm
apt-mark unhold kubeadm && apt-get update && apt-get install -y kubeadm=1.27.1-00 && apt-mark hold kubeadm
kubeadm version
kubeadm upgrade plan
sudo kubeadm upgrade apply v1.27.1 -y
kubeadm upgrade node
kubeadm upgrade apply
# replace <node-to-drain> with the name of your node you are draining
kubectl drain hk8s-worker1 --ignore-daemonsets
# replace x in 1.27.x-00 with the latest patch version
apt-mark unhold kubelet kubectl && apt-get update && apt-get install -y kubelet=1.27.1-00 kubectl=1.27.1-00 && apt-mark hold kubelet kubectl
sudo systemctl daemon-reload
sudo systemctl restart kubelet
# replace <node-to-uncordon> with the name of your node
kubectl uncordon hk8s-worker1
kubectl get nodes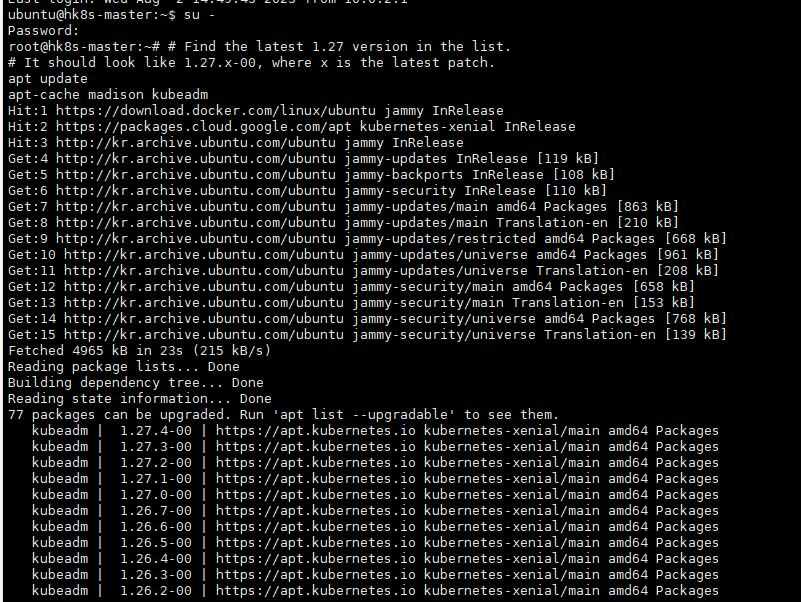

노드 비우기
-> drain, cordon
작업 클러스터 : k8s
k8s-worker2 노드를 스케줄링 불가능하게 설정하고, 해당 노드에서 실행 중인 모든 Pod을 다른
node로 reschedule 하세요.
drain: node를 schedule 불가능하게 만들고, 해당 node에 있는 pod들을 다른 node로 reschedule.
cordon: node를 schedule 불가능하게 만듦.
uncordon: drain 및 cordon로 인해 schedule 불가능하게 된 node를 다시 schedule 가능하도록 만듦.
history
kubectl config use-context k8s
kubectl drain k8s-worker2 --ignore-daemonsets --force --delete-emptydir-data
kubectl get nodes 
drain 후 스케줄링 가능하도록 바꾸기
-> uncordon 사용
kubectl uncordon k8s-worker2