Control plane을 여러개로 하는 이유
Kubernetes에서 Control plane(이하 CP)은 노드들을 관리합니다. 시스템에 장애가 생기면 아무것도 관리 할 수 없기 때문에 Sigle Point of Failure 문제가 발생할 수 있게 됩니다. 따라서 고가용성을 위해 CP를 여러 개 두는데 이 때 짝수개로 생성하면 문제가 발생할 수 있습니다.
Control plane을 홀수개로 구성하는 이유
Control plane에는 etcd라는 스토리지가 있습니다. 멀티 클러스터링을 하게 되면 etcd는 분산 클러스터가 됩니다. 이때 etcd는 RAFT 합의 알고리즘을 통해 데이터의 일관성을 유지하게 됩니다. RAFT 합의 알고리즘이란 요청을 수행할 때 Yes/No로 투표를 하게 되고, 과반수 이상의 노드가 있는 쪽의 요청을 유효한 요청으로 수행하게 되는 알고리즘입니다. etcd는 RAFT 알고리즘을 통해 어떤 클러스터가 primary인지 결정하게 됩니다.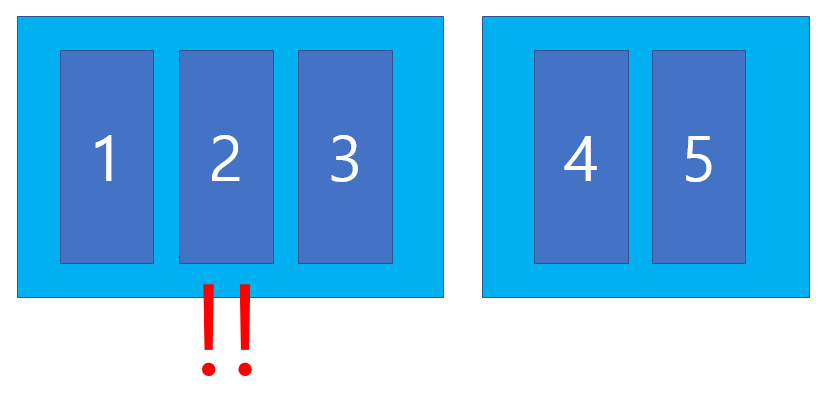
만약 전체 CP가 짝수개라면 양 쪽이 동일한 수가 나올 수 있게 되고(EX) 전체 4 yes 2:no 2) primary를 정하지 못해 문제가 발생할 수 있기 때문에 전체 개수를 홀수로 구성하게 됩니다.

active-standby
고가용성 스토리지에서 여러 개의 스토리지가 데이터에 접근하게 되면 무결성의 문제가 발생하기 때문에
읽기쓰기 권한이 있는active(primary)
읽기 권한만 있는standby(sub)로 나누어 동작하게 됩니다.
홀수였다가 하나가 장애가 나면 다시 짝수가 되는거 아닌가요❓
클러스터링 과정에서 클러스터마다 우선순위를 부여하게 됩니다.
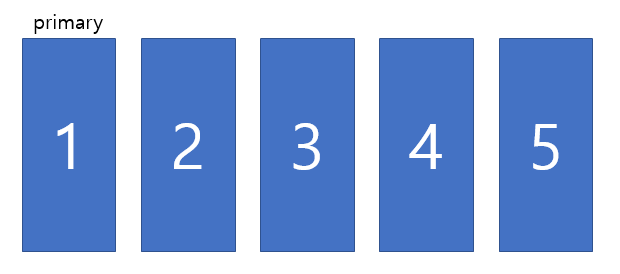
primary가 장애가 났을 때, 남은 클러스터끼리 투표를 하여 primary를 정하는 것이 아니라, 클러스터링 과정에서 1번 primary, 2번 primary.. 로 미리 정해두어 1번이 죽으면 2번이 사용되는 알고리즘이기 때문에 문제가 발생하지 않습니다.
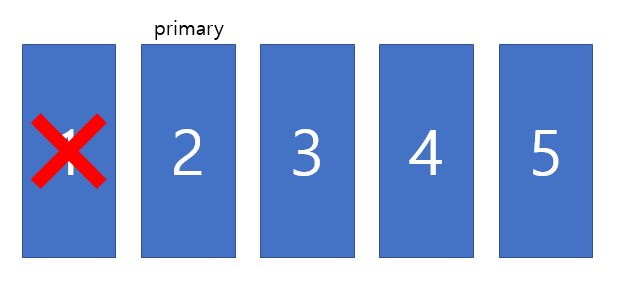
전체가 6개일 때 4:2로 나뉠수도 있는데 문제 없지 않을까요❓
3:3으로 나뉠 수도 있는 가능성이 존재하기 때문입니다. 고가용성을 보장하기 위해서는 장애가 발생할 가능성이 존재해서는 안 됩니다.
