공부용 collections framework 정리
Java Collections Framework는 유용한 자료구조를 제공하는 것으로 여기에서 Collections Framework를 구성하는 인터페이스 및 클래스를 확인할 수 있다. 대략적인 구조는 다음과 같다.
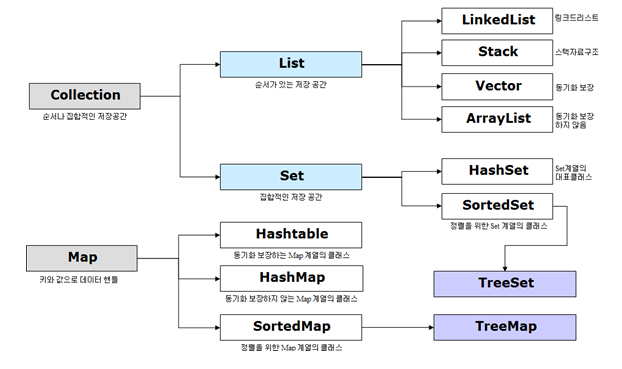
상위 인터페이스 특징과 구현체
- List
중복이 가능, 순서를 유지한다.ArrayList: 순차적인 삽입/삭제에 유리하다.Vector: 동기화를 보장하지만 성능 문제로 인해 사용하지 않는 것을 권장한다.LinkedList: stack, queue 등을 구현할 수 있으며, 삽입/삭제가 중간에서 이루어질 때 유리하다.Stack
- Set
중복이 불가능, 순서를 유지하지 않음.HashSet: 순서가 필요없는 데이터를 HashTable에 저장. Set 중에 가장 성능이 좋다.TreeSet: 값에 따라 정렬이 된다. (red-black tree 타입으로 저장)LinkedHashSet: 연결된 목록 타입으로 구현된 hash table에 데이터 저장. 셋 중 가장 느리다.
- Map
key, value 쌍의 형태, key 중복 불가능HashTable: Thread-safe함HashMap: 제일 기본적인 mapTreeMap: 정렬이 되어 있고, 순서가 존재한다.
상위 인터페이스 주요 메소드
모든 구현체에 공통적으로 사용할 수 있는 인터페이스 메소드를 숙지하고 각 구현체 사용에 필요한 메소드는 상황에 맞게 찾으면서 사용한다.
- Collection 인터페이스 주요 메소드
boolean add(E e): Collection에 객체를 추가void cleear(): Collection의 모든 객체를 제거Iterator<E> iterator: Collection을 순환할 반복자(iterator)를 반환boolean remove(Object o): Collecion에 매개변수에 해당하는 인스턴스가 존재하면 제거int size(): Collection에 있는 요소의 개수를 반환
- Map 인터페이스 주요 메소드
void put(K key, V value): key에 해당하는 value값을 map에 삽입한다.void get(K key): key에 해당하는 value값을 반환한다.boolean isEmpty(): Map이 비어있는지 여부를 반환boolean containsKey(Object key): Map에 해당 value의 존재 여부를 반환boolean containsValue(Object value): Map에 해당 value의 존재 여부를 반환Collection values(): value를 Collection으로 반환(중복 무관)void remove(key): key가 있는 경우 삭제 한다boolean remove(Object key, Object value): key가 있는 경우 key에 해당하는 value가 매개변수와 일치할 때 삭제
ArrayList
List<T> list = new Arraylist<T>(n); // 꽉 찰 경우 n씩 크기를 증가시키는 ArrayListArrayList의 경우 생성시 기본적으로 크기 10의 ArrayList를 생성하고, 따로 크기를 지정하지 않으면 ArrayList과 꽉 찰 경우 내부적으로 2배씩 크기를 증가시킨다.
- 단점
ArrayList의 크기를 늘리는 과정에서 많은 시간이 소요된다. 저장공간이 부족할 경우 아래와 같은 과정을 거쳐 ArrayList의 크기를 증가시킨다.- 확장된 크기의 ArrayList를 생성한다.
- 기존에 ArrayList를 새로 생성한 ArrayList에 복사한다.
- 기존에 ArrayList는 가비지 컬렉션에 의해 메모리에서 제거된다.
LinkedList
LinkedList는 중간 삽입/삭제가 빈번할 수록 사용하는 것이 효율적이다. 순차적인 삽입/삭제가 빈번하다면 ArrayList를 사용하는 것이 효율적이다. LinkedList를 이용해 Stack, Queue등을 구현할 수 있다.
List<E> list = new LinkedList<E>();일반적으로 위와 같이 선언하는 것을 권장했던 다른 자료구조와는 달리 Queue를 구현하기 위해서는
LinkedList<E> list = new LinkedList<E>();위와 같은 생성자를 사용해야한다. offer, poll, peek과 같은 메소드는 list 인터페이스에서 제공하지 않기 때문에 LinkedList 클래스 메소드를 사용해야한다.
import java.util.*;
class LinkedListTest{
public void test() {
LinkedList<Integer> queue = new LinkedList<Integer>();
queue.offer(5);
queue.poll(); // queue의 멘 앞요소 제거
queue.offer(6);
queue.offer(7);
queue.offer(2);
queue.add(123);
System.out.println(queue.peek());
System.out.println(queue);
}
}
public class main {
public static void main(String[] args) {
LinkedListTest li = new LinkedListTest();
li.test();
}
}HashSet
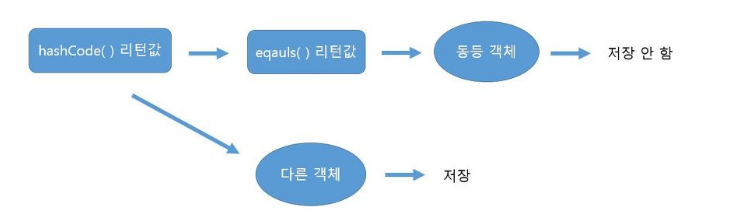
Java에서 해시 알고리즘을 이용한 자료구조는 다음과 같은 과정을 거친다.
- hashcode()를 이용해 val에 대한 해시값을 얻는다.
- hashcode()를 통해 얻은 값을 기존에 저장된 해시값들과 비교한다.
- 이미 존재할 경우 저장하지않고, 존재하지 않을 경우 저장한다.
문자열을 HashSet에 저장할 때도 위와 동일하게 동작한다. 그 이유는 String 클래스가 hashCode()와 equals() 메소드를 오버라이딩하여, 같은 문자열일 경우 hashCode()의 return 값을 같게, equals()의 리턴 값을 true가 되도록 구현했기 때문이다. 필요에 따라 hashCode()와 equals()를 재정의할 수 있다.
HashMap
- 추가/검색 속도가 빠르다.
- 순서를 보장하지 않음
- 해시함수를 통해 key값에 대한
index를 얻고 이를 이용해 해시테이블의 해당 인덱스에 value를 저장한다.
Map 순회
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Collections {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<Integer, String>();
map.put(1,"오픈소스");
map.put(2,"OCJP");
map.put(3,"자바심화");
map.put(3,"Bod"); // 키는 중복 불가, val가 update 된다.
map.put(4,"Bod");
Iterator i = map.entrySet().iterator();
while(i.hasNext()) {
System.out.println(i.next());
}
}
}
/*
1=오픈소스
2=OCJP
3=Bod
4=Bod
*/import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
class Dog {
private String name;
private int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return this.name.hashCode()+age; // 이름과 나이가 같은 경우 같은 해시값을 반환
}
@Override
public boolean equals(Object o) {
if (o instanceof Dog) {
Dog dog = (Dog)o;
return dog.name.equals(this.name) && (dog.age == this.age); // 이름과 나이가 같으면 같은 객체로 처리한다.
// return false;
}
return false;
}
}
public class Collections {
public static void main(String[] args) {
Map<Dog,String> dogMap = new HashMap<Dog,String>();
dogMap.put(new Dog("멍멍이",4),"멍멍");
dogMap.put(new Dog("멍멍이2",5),"왈왈");
dogMap.put(new Dog("멍멍이3",2),"캉캉");
dogMap.put(new Dog("멍멍이3",2),"멍"); // 멍멍이3 update
Iterator i = dogMap.entrySet().iterator();
while(i.hasNext())
System.out.println(i.next());
}
}
/*
Dog@578388e3=왈왈
Dog@578388e1=멍
Dog@2d2b1d8=멍멍
*/HashTable
Hashtable은 Collection Framework가 도입되면서 HashMap으로 대체되었으나 이전소스와의 호환성 문제로 남겨두고 있다.
