서론
복제 지연 : 원본 MySQL 인스턴스에서 쓰여진 내용이 복제 MySQL 인스턴스로 적용되기까지의 시간
단순 복제는 MySQL이 세계에서 가장 인기 있는 오픈소스 관계형 데이터베이스 서버가 된 이유 중 하나!
MySQL의 초기 버전은 단일 스레드의 명령문 기반 복제(Statement-Based Replication)를 사용했다.
원본에서 실행한 SQL을 복제본에서 한 번 실행하는 방식이다.
매우 간단하고 잘 작동됐지만 문제가 존재하기는 한다.
그래도 가장 간단한 솔루션이라는 메리트가 있어서 20년이 지난 지금도 명령문 기반 복제를 지원한다.
사실 복제가 성능을 떨어뜨리는 것은 맞지만 비즈니스 실패를 방지한다는 이점 때문에 필수이다.
MySQL의 복제 유형
원본에서 복제본으로 (source to replica)
20년 이상 사용해온 기본 복제 유형. 빠르고 안정적이며 여전히 널리 사용 중
그룹 복제 (group replication)
5.7.17부터 지원. 그룹 합의 프로토콜(group consensus protocol)을 사용하여 데이터 변경 사항을 동기화하고, 그룹 구성원을 관리하는 MySQL 클러스터를 생성.
그룹 복제란 MySQL 클러스터링 이며, 복제와 고가용성의 미래이다. 근데 이 책에서는 다루지 않음
그룹 합의 프로토콜
분산 시스템에서 데이터 일관성을 보장하기 위해 여러 노드가 하나의 합의된 상태를 결정하도록 하는 알고리즘
Paxos: 합의 알고리즘의 전형적인 예로, 주로 내결함성을 가진 분산 시스템에서 사용됩니다.
Raft: Paxos의 복잡성을 줄이고 이해하기 쉽게 만든 알고리즘으로, 리더를 선출하고 로그 복제를 통해 일관성을 유지합니다.
Two-Phase Commit (2PC) 및 Three-Phase Commit (3PC): 트랜잭션 일관성을 보장하기 위해 데이터베이스에서 자주 사용하는 합의 프로토콜입니다.
MySQL 그룹 복제(Group Replication): 비잔틴 장애(BFT)를 견디는 복제 방식을 사용하여 노드 간 합의를 통해 데이터를 동기화합니다.
MySQL 그룹 복제의 경우, 데이터가 업데이트될 때 모든 노드가 이 변경 사항을 수신하고 이를 검증하여 과반수 이상의 노드가 승인해야 최종적으로 업데이트가 적용됩니다.
만약 일부 노드가 비정상 상태이거나 실패해도, 과반수가 합의하면 시스템은 계속 운영될 수 있습니다.
책을 쓰던 중 그룹 복제가 미래인 줄 알았더니 더 뛰어난 혁신인 InnoDB 클러스터가 업계 표준이 되고 있다.
Percona Xtra DB 클러스터, MariaDB Galera 클러스터 등도 그룹 복제와 목적은 비슷하지만 다른 클러스터 솔루션이다. 그리고 적용을 염두에 두는 것이 좋다.
각 복제의 내부 작동 원리는 이 책의 범위를 벗어나지만, 기초를 이해하면 복제 지연의 원인과 위험을 다스릴 수 있다.
source to replica를 통해 기본을 알아보자
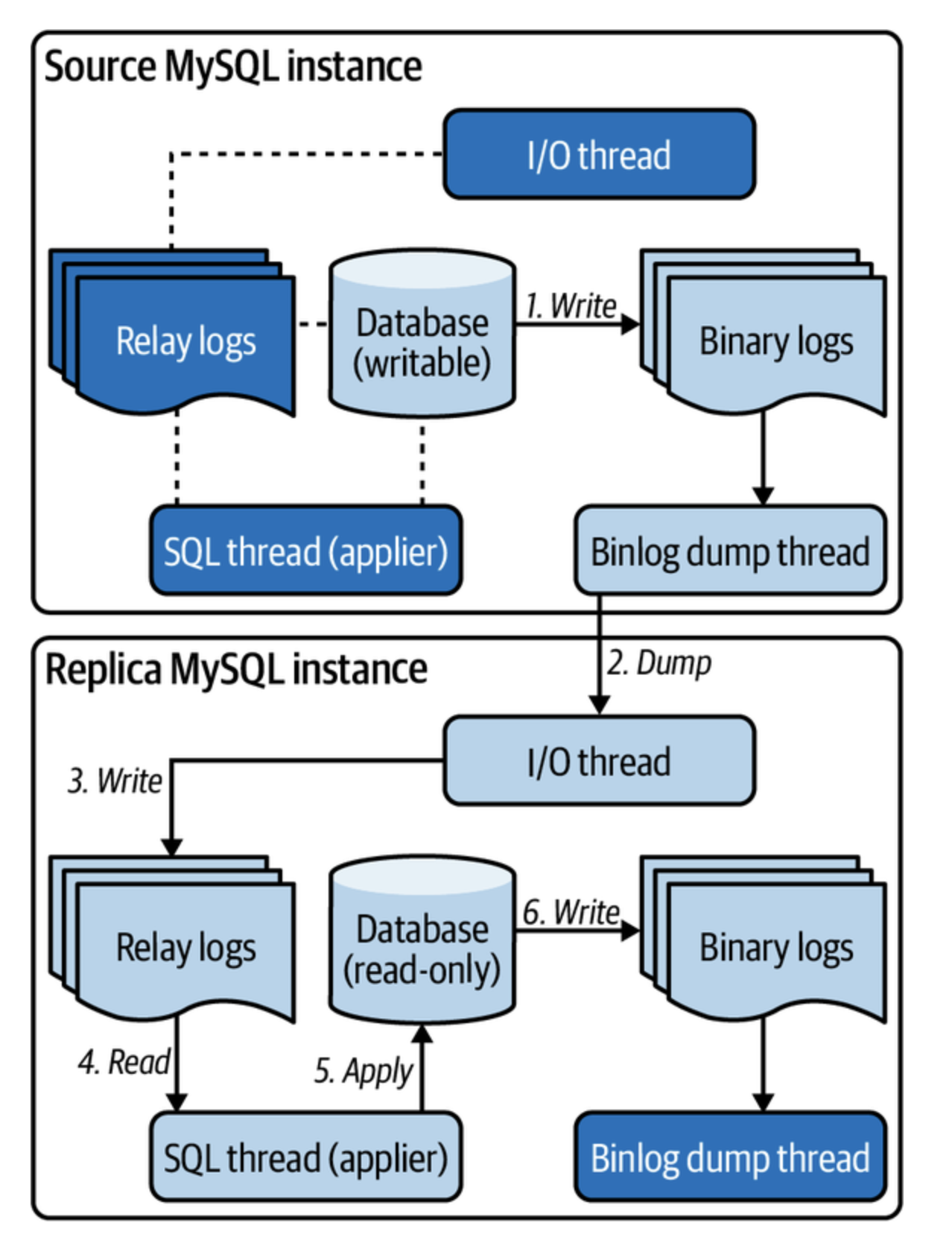
참고로 MySQL은 멀티 rw 구성을 지원하지만 쓰기 충돌 처리 어려움 때문에 잘 사용되지 않음.
- 트랜잭션 커밋 중에 데이터 변경 사항은 바이너리 로그에 기록
- 복제본의 I/O 스레드가 원본 바이너리 로그를 덤프
- 복제본의 릴레이 로그에 바이너리 로그 이벤트를 기록
- SQL 스레드가 릴레이 로그를 읽어서 복제본에 적용
- 복제본의 바이너리 로그에 기록
기본적으로 비동기 방식으로 동작 : 원본의 트랜잭션은 1단계가 끝나고 완료되고 그 후는 모두 비동기
반동기식으로 동작 : 원본의 트랜잭션은 3단계가 끝나고 완료되고 그 후는 모두 비동기
5번은 필요 없지 않은가?? 하지만 ro가 rw가 되면 그게 원본이 되기 때문에, 그리고 장애 조치를 위해
바이너리 로그 이벤트
DBA 조차도 함부로 건드리지 않고, 우리는 더더욱 접할 일이 없을 낮은 수준의 세부 사항이지만 애플리케이션이 실행한 트랜잭션의 직접적인 결과이다.
따라서 복제 프라이프라인을 통해 무엇을 플러시하려고 하는지 이해하는 것이 중요!!
높은 수준에서는 애플리케이션의 동작에 중요한 트랜잭션에 초점을 맞춘다면, 낮은 수준에서는 복제에 의미가 있는 바이너리 로그 이벤트에 초점
BEGIN;
UPDATE t1 SET c='val' WHERE id=1 LIMIT 1;
DELETE FROM t2 LIMIT 3;
COMMIT;변경 사항에 초점을 맞춰보자.
- 테이블 t1에서 1개 행을 변경하고
- 테이블 t2에서 최대 4개 행을 삭제
로우 레벨에서는 SQL 문이 사라지고 이벤트와 행 이미지의 스트림으로 존재한다. (행 이미지: 수정 전/후 행의 바이너리 스냅샷)
단일 SQL 문은 수많은 행 이미지를 생성할 수 있으며, 복제하는 동안 지연을 일으키는 큰 트랜잭션을 생성할 수 있다.
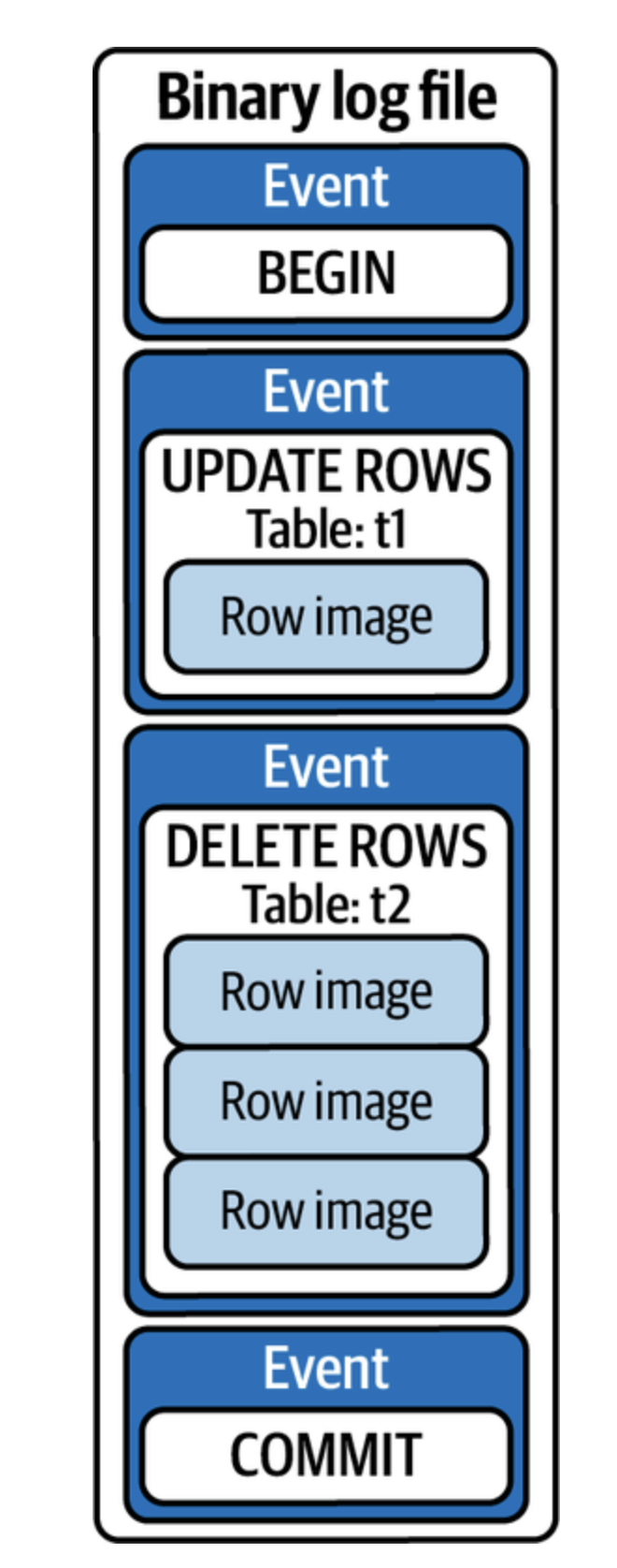
(4개의 바이너리 로그 이벤트로 바뀐 모습)
복제 지연
다시 이전의 그림을 살펴보자.
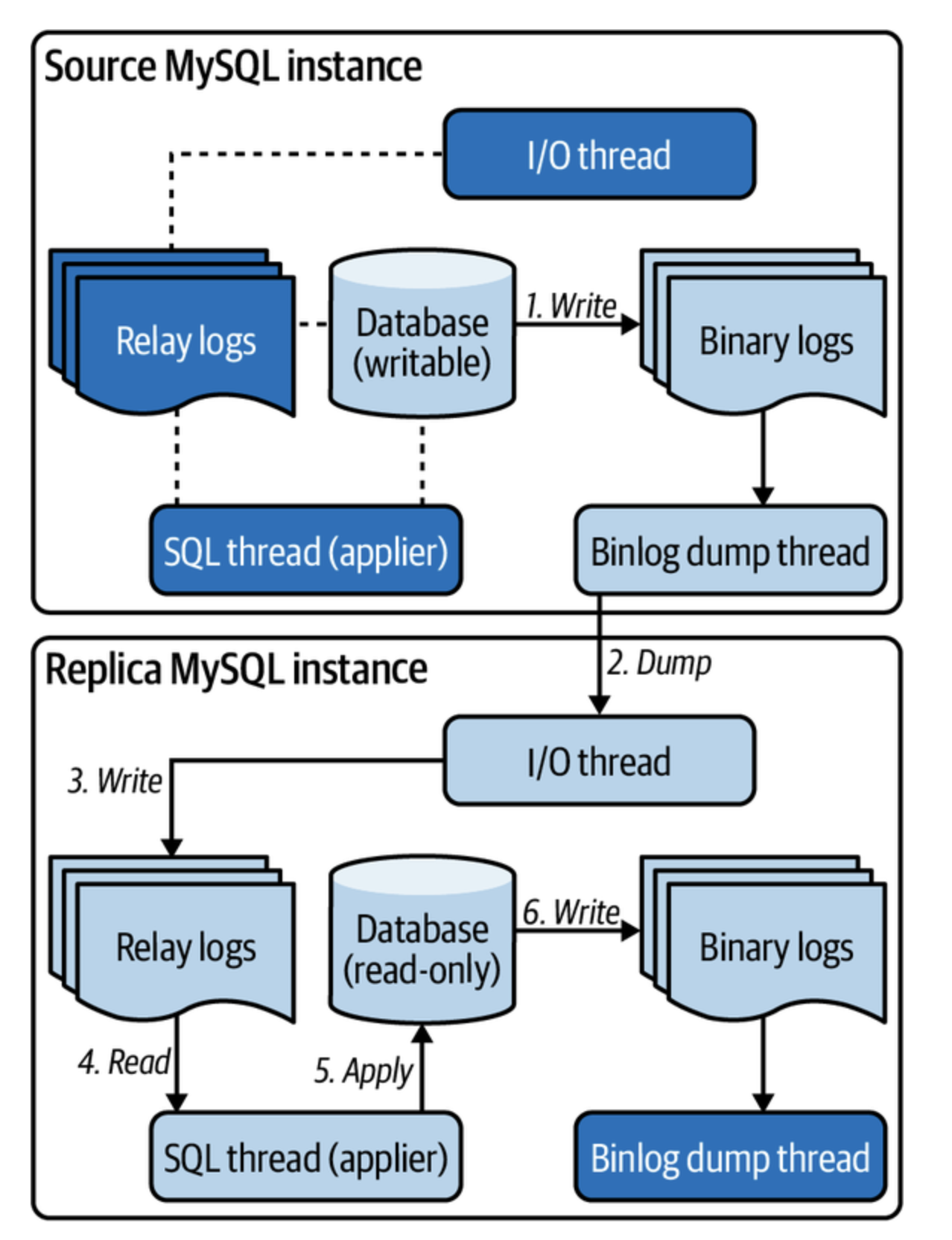
비동기식 처리 방식일 때
1번 과정(원본에서 바이너리 로그에 쓰기)까지만 동기이므로, 5번 과정(복제본에 적용)이 1번 과정보다 느릴 때 복제 지연이 발생한다.
복제본의 I/O 스레드가 네트워크에서 바이너리 로그를 읽고 릴레이 로그에 쓰는 것은 쉬운 과정이라서 빠르다.
하지만 SQL 스레드가 변경 사항을 적용하는 것은 훨씬 어렵고 시간이 많이 걸린다.
결과적으로 I/O 스레드는 SQL 스레드를 능가하고 복제지연은 아래와 같다.
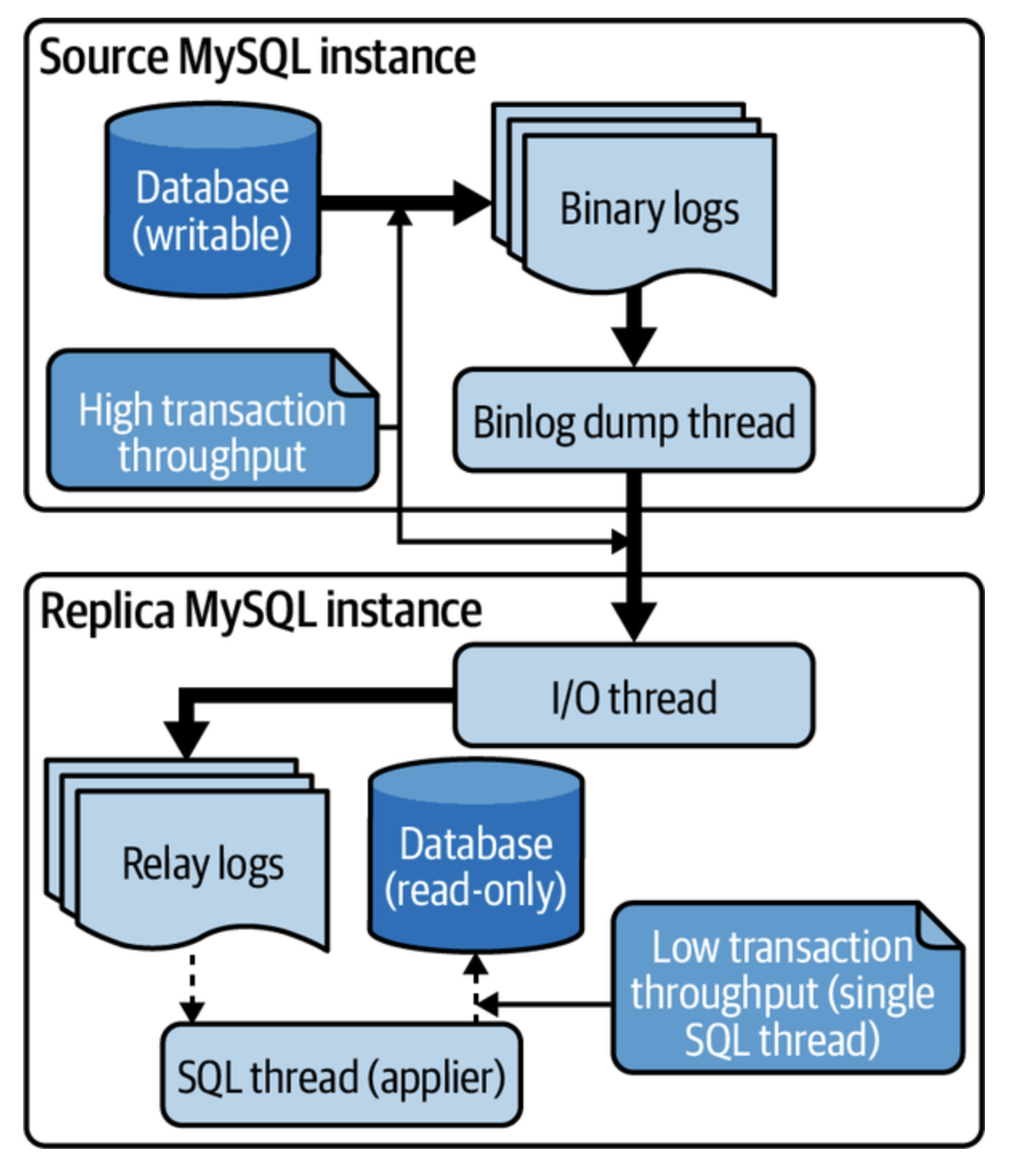
여기서 단일 SQL 스레드가 복제 지연을 유발하지 않을까?? 하는 생각이 들 수 있는데
사실 원인은 원본의 트랜잭션 처리량이 높은 것이다.
애플리케이션 입장에서는 좋지만, 지연이 발생하므로 문제이긴 하다.
그렇다고 MySQL 복제가 느린 것은 아니다. 매우 빠르다.
단일 SQL 스레드도 초당 수천 건의 트랜잭션을 쉽게 처리할 수 있다.
원본 SQL을 실행하는 것이 아니라 바이너리 로그 이벤트를 기반으로 적용하기 때문!!
만약 바이너리 로그가 아니라 원본 SQL을 실행하게 된다면??
조회 쿼리를 통해 업데이트할 위치를 찾고, 또 업데이트를 수행하는 방식이기 때문에 바이너리 로그를 적용하는 것보다 훨씬 느리다.
이렇게 빠른 복제 속도라서 원본이 열심히 트랜잭션을 처리하는 동안 복제본이 노는 경우가 많다. (하지만 이때도 지연이 발생한다)
복제 지연의 3가지 원인
- 트랜잭션 처리량
- 장애 후 재구축
- 네트워크 문제
트랜잭션 처리량
복제본의 SQL 스레드가 변경 사항을 적용하는 속도보다 원본이 빠를 때 복제 지연을 유발한다.
근데 그렇다고 애플리케이션이 정상적으로 빠르게 움직이는 것을 제한할 수는 없다.
과도하게 많은 행을 수정하는 대규모 트랜잭션은 원본보다 복제본에 더 큰 영향을 준다.
왜냐하면 원본은 병렬로 실행하지만,
복제본은 기본적으로 단일 SQL 스레드로 적용하기 때문에 큰 트랜잭션을 실행하는 동안 다른 트랜잭션을 차단하기 때문이다.
해결책은 복제본의 SQL 스레드를 다중으로 실행하는 것.
하지만 병렬로 실행해서 throughput이 늘어날 뿐, 2초가 걸리는 하나의 큰 트랜잭션이 있다면 여전히 그 트랜잭션은 2초 동안 하나의 스레드를 사용하게 된다.
해결책은 더 작은 트랜잭션
항상 애플리케이션이 트랜잭션 처리량을 결정하는 것은 아니다.
데이터 백필링, 삭제, 보관 등은 배치 크기에 따라 달라질 수 있다.
복제가 지연되기 시작하면 이러한 작업은 속도를 줄여야 한다.
복제본 반영을 1초 지연시키는 것보다 작업에 하루가 걸리는 것이 더 낫다.
추가 정보: 어느 시점에서 트랜잭션 처리량은 1개 MySQL 인스턴스의 용량을 초과하므로 처리량을 늘리려면 샤딩 고려
장애 후 재구축
고장난 인스턴스가 다시 수리되고 복제본 토폴로지로 돌아가게 되면,
오프라인 상태에서 놓친 모든 바이너리 로그 이벤트를 따라 잡는데 몇 분, 몇 시간 또는 며칠이 걸린다.
이것도 복제 지연이지만 어쩔 수 없다.
네트워크 문제
네트워크를 고치세요!
복제 지연의 위험
복제 지연 == 데이터 손실
결론부터 말하자면 반동기식 복제를 사용하면 커밋된 트랜잭션을 잃지 않고, 데이터 손실을 완화할 수 있다.
우선 기본 방식인 비동기에서 어떻게 발생하는지 보자.
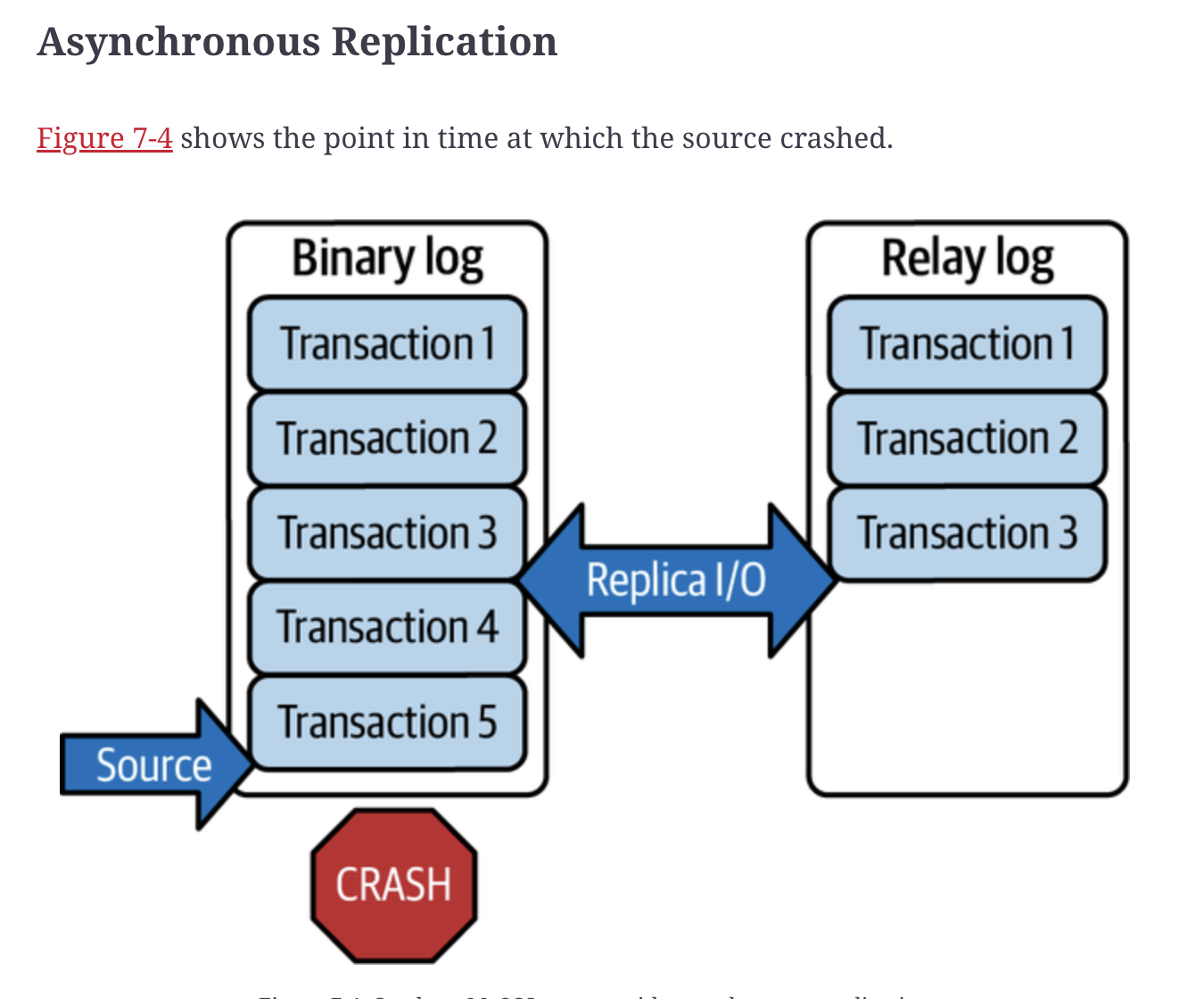
원본은 5개의 트랜잭션을 커밋했는데 충돌이 발생하여 복제 I/O 스레드가 3개의 트랜잭션만 가져왔다.
마지막 2개의 트랜잭션이 손실 났을까??
충돌 원인과 DBA의 장애 조치 여부라는 2가지 요인에 따라 달라진다.
- 충돌 원인이 MySQL 때문이라면 자동으로 다시 시작하고 충돌 복구 수행 후 정상 작동 재개. (수 분 또는 수 시간 걸릴 수 있음)
- 충돌 원인이 MySQL이 아닌 하드웨어나 운영체제 때문이라면, DBA가 fail over하고 트랜잭션 2개는 잃게 된다.
따라서 기다릴 수 있다면 커밋된 트랜잭션이 손실되지 않으므로 충돌 복구가 이상적인 솔루션!
참고로 유지보수를 위해 Fail Over로 ro → rw 승격시키는 것은 데이터 손실이 일어나지 않는다 (일부 DBA는 이것을 Success Over라고 부름)
근데 사실 모든 하드웨어와 소프트웨어는 장애가 발생하므로 비동기식 복제를 사용할 때 데이터 손실은 불가피하다.
유일한 완화 방법은 복제 지연 최소화를 엄격히 준수 하는 것.
10초의 복제 지연이 있을 때, 최근 10초 동안 고객 데이터가 손실될 위험이 있다고 생각해야 한다.
복제본이 지연되는 최악의 순간에도 MySQL이나 하드웨어에 장애가 발생하지 않을 확률이 높지만,
작성자가 푸는 한 경험담...
내가 온콜 근무 중이었을 때, 오전 9시쯤 경고 알림이 왔습니다.
그리고나서 하나의 알림이 빠르게 수천 개로 번졌습니다.
여러 지역에 분산된 데이터 센터의 데이터베이스 서버들이 모두 실패하고 있었죠.
그 정도면 문제의 원인이 하드웨어나 MySQL일 리는 없다는 것을 즉시 알 수 있었습니다.
그렇게 많은 서버가 동시에, 그리고 무관하게 실패하는 것은 확률적으로 불가능에 가까우니까요.
결론은 회사에서 가장 경험이 많은 엔지니어 중 한 명이 작성해 실행한 스크립트가 문제였습니다.
그 스크립트는 서버를 임의로 재부팅한 것이 아니라, 서버를 꺼버린 것이었죠.장애는 사람의 실수로 인해 발생할 수 있다.
그리고 비동기식 복제는 전세계 수많은 회사가 쓰지만 모범 사례를 의미하지는 않는다.
데이터 손실을 최소화하지 못하는 것은 영구적인 데이터 스토리지의 목적과 상반되기 때문.
아래 3가지를 가지고 DBA와 전문가는 즉시 알맞은 조치를 취해야 한다.
- 하트비트를 통해 복제 지연 모니터링한다 (뒤에서 설명 예정)
- 복제 지연 시간이 너무 길면 언제든지 경고 알람을 받는다
- 복제 지연을 데이터 손실로 간주하고 즉시 수정한다
반동기식 복제
많은 기업이 비동기식을 사용하지만 더 높은 표준인 반동기식을 사용할 수 있도록 노력해야 한다.
반동기식은 최소 하나의 복제본이 해당 트랜잭션을 릴레이 로그에 기록할 때까지 기다린다. (복제본의 로컬에 안전하게 존재하지만 반영되지는 않은 상태)
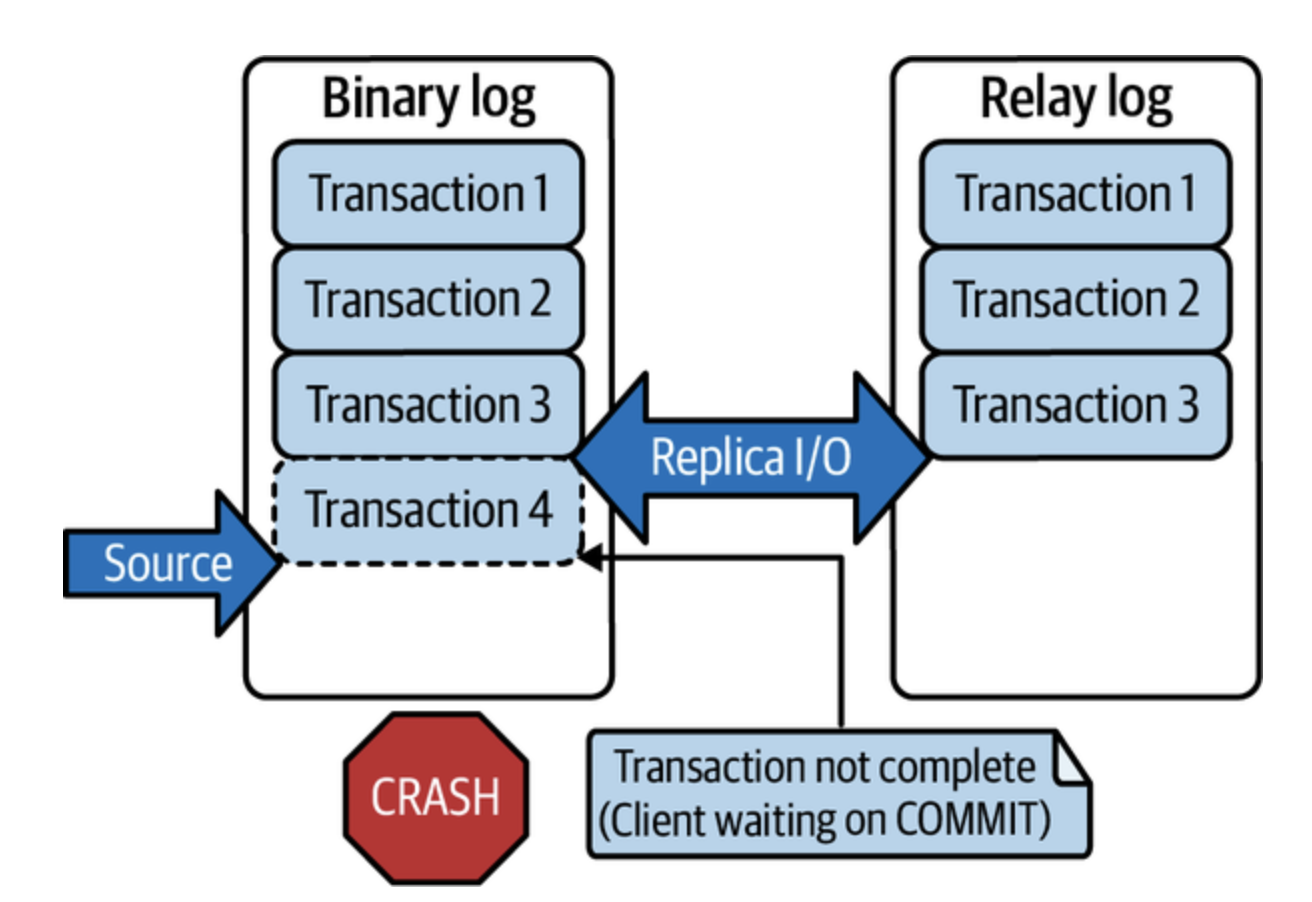
앞서 비동기식에서 발생한 충돌이 반동기에서 발생한다면??
- 1, 2, 3은 릴레이 로그에 기록이 완료됐고 4번 트랜잭션의 릴레이 로그 기록이 실패된 상태
데이터 손실은 발생한다...그러나 원본-복제 연결 1개당 최대 1개의 트랜잭션만 손실될 수 있으므로 덜하다.
근데 반동기식이 MySQL의 기본값이 아닌 이유는 무엇일까??
- 반동기식 복제는 가용성을 떨어뜨린다.
- 현재 트랜잭션이 복제 단계에서 지연되어 시간초과, 또는 commit에서 실패할 수 있음.
- 반면, 비동기식에서는 commit이 즉시 수행되며 원본 스토리지만 작동하면 보장됨.
- 반동기식 복제는 복제본이 충분하지 않거나 원본이 응답 대기 시간을 초과하면 비동기식으로 되돌아간다.
- 이 기능을 사용하지 않도록 끌 수 있지만 허용하는게 좋음. (애플리케이션이 원본에 쓰지 못하는 상황이 더 나쁨)
- 네트워크 지연 시간이 원본 트랜잭션 처리량을 제한할 수 있으므로 원본과 복제본이 빠른 로컬 네트워크에 존재해야 한다.
- 1ms 미만이 아닐 경우 어려움을 겪게 됨.
비동기식은 특별한 구성 없이 동작하지만, 반동기식은 특정 구성과 튜닝이 필요하다.
이러한 어려움에도 불구하고 성공적으로 반동기식을 사용하는 성공적인 회사 → 깃허브
깃허브 MySQL 전문가 Shlomi Noach의 MySQL 고가용성 : Consul, orchestrator, HAProxy 등을 사용해서 mysql 클러스터 운영하는 이야기
저자 생각
데이터 손실은 절대 허용되지 않으므로 반동기식 복제가 가장 좋은 방법이라고 생각합니다.
사실 반동기식 복제와 그룹 복제는 MySQL 전문가 사이에서 논쟁을 일으키지만, 데이터 손실을 방지하는 것이 먼저라는 점은 모두가 동의합니다.
지연 감소: 다중 스레드 복제
비동기식이든 반동기식이든 복제본에 있는 SQL 스레드는 단일 스레드이다.
단일 SQL 스레드는 복제 지연을 일으키지는 않지만 제한 요소이다.
해결책으로 다중 SQL 스레드를 통해 트랜잭션을 병렬로 적용할 수 있다.
SQL 스레드를 적용자 스레드라고도 함.
트랜잭션 간에는 순서가 있는데 어떻게 병렬로 적용할 수 있을까??
핵심은 트랜잭션 종속성 추적!!
흥미롭고 인상적인 주제이지만 책의 범위가 아니므로 MySQL 전문가 장 프라수아 가녜의 LOGICAL_CLOCK을 이용한 MySQL Parallel Replication
(살짝 훑어봤는데 종속성 없는 명령들을 찾아서 최대한 병렬로 실행시키는 instruction pipelining 같은 내용인듯)
사실 여기서부터는 고성능, 고가용성 환경에서 MySQL을 구성한 경험이 있는 엔지니어만 수행해야 하는 중요한 설정이다.
하지만 다중 스레드 복제는 매우 중요하므로 그 설정의 출발점이라도 제공하고자 한다.
| MySQL 5.7.22 ~ 8.0.25 | MySQL 8.0.26 이상 | 값 | 설명 |
|---|---|---|---|
| slave_parallel_workers | replica_parallel_workers | 4 | 다중 스레드 수 |
| slave_parallel_type | replica_parallel_type | LOGICAL_CLOCK | LOGICAL_CLOCK (기본값): 트랜잭션의 논리적 시계를 기반으로 병렬 적용, 트랜잭션 순서를 유지하면서 병렬 실행. DATABASE: 데이터베이스 단위로 병렬 실행. TABLE: 테이블 단위로 병렬 실행. |
| slave_preserve_commit_order | replica_preserve_commit_order | 1 | 복제본에서 트랜잭션을 적용할 때, 마스터에서 커밋된 순서를 그대로 유지할지를 결정. |
주의할 점:
- 복제는 고가용성에 영향을 미친다.
- 전역 트랜잭션 식별자와 log-replica-updates를 활성화해야 한다. (개발 디비 기준 활성화돼있음)
- 높은 MySQL 권한 필요하다.
- 변수명이 버전 및 배포판에 따라 다르다.
- 철저히 메뉴얼을 읽고 해라!!!!!!!!!!!!!
더욱 딥한 내용
MySQL 트랜잭션 종속성 추적은 시스템 변수인 binlog_transaction_dependency_tracking 에 따라 결정된다.
기본값은 COMMIT_ORDER이지만 최신 값은 WRITESET이다.
WRITESET은 MySQL 8.0에서 소개됐는데 더 나은 성능을 달성하므로 사용해야 하지만, 프로덕션에서 사용할 수 있을 만큼 성숙된 시점은 여러분이 직접 결정하라.
참고로 MySQL 5.7에서 사용하려면 시스템 변수 transaction_write_set_extraction 을 사용해야 한다.
MySQL 8.0에서 저 변수는 기본적으로 활성화돼있지만, 8.0.26부터는 더 이상 사용하지 않는다.설정해야할 시스템 변수가 하나 더 있다. 바로 binlog_group_commit_sync_delay
일반적으로 그룹 커밋에 인위적인 지연을 추가하므로 기본적으로 비활성화이다.
지연을 추가하면 그룹 당 더 많은 트랜잭션을 커밋하게 되고, 따라서 트랜잭션 종속성 추적이 더 많은 병렬화 기회를 찾을 수 있다.
이 설정값을 실험하려면 10000(10ms)부터 시작한다.
이를 튜닝할 때 MySQL 메트릭이 부족하기 때문에 쉽지 않다.
장 프랑수아 가녜의 MySQL 5.7에서 병렬 복제 튜닝을 위한 메트릭을 읽어보도록...(대충 Transactions_behind_master 및 Relay_log_space를 살펴보며 튜닝하는 얘기)상당한 MySQL 설정과 튜닝이 필요하지만 잘 설정한다면 복제본의 트랜잭션 처리량을 2배 이상 늘릴 수 있다.
가장 중요한 점은 다중 스레드 복제가 비동기 복제를 사용할 때 복제 지연을 크게 줄인다.
모니터링
가장 좋은 방법인 전용 도구를 사용하기에 앞서, 악명 높은 복제 지연 메트릭인 Seconds_Behind_Source 를 살펴보자.
 (개발 배민페이에서 아무것도 안나온다)
(개발 배민페이에서 아무것도 안나온다)
Seconds Behind Source가 뭐냐면, 복제본의 현재 시각 - SQL 스레드가 실행 중인 바이너리 로그 이벤트의 타임스탬프
현재 복제본의 시각이 100이고 처리 중인 바이너리 로그의 타임스탬프가 80이라면 복제 지연이 20이라고 보면 된다.
근데 저 메트릭이 악명 높은 이유들이 있다.
- 실시간으로 보고한다. 현재 처리되고 있는 바이너리 로그 이벤트가 없다면 지연이 0이다.
- 엔지니어들이 정말로 알고 싶어하는 질문인 복제본이 언제 따라잡을 수 있나요?는 정확히 답하지 못한다.
- 원본에서 실행된지 얼마가 지났는지만 알려주지, 바이너리 로그 이벤트의 복제본 적용 속도는 다르기 때문에 알 수 없다.
- 예를 들어 각 1초씩 걸리는 10개의 트랜잭션이 원본에서 동시에 실행됐으면 속도는 10 TPS이다. 하지만 단일 SQL 스레드로 복제본에 적용하는 최악의 속도는 1TPS이다. 근데 바이너리 로그 기반이라서 10 TPS보다 더 빠를 수도 있다ㅋㅋㅋ
결국 가장 좋은 방법은 pt-heartbeat 라는 전용 도구를 사용하는 것이다.
일정한 간격으로 타임스탬프를 작성하므로 메트릭 변동 폭이 크지 않고 일관된 결과를 알려준다.
일정한 간격은 1초 미만으로 설정 가능한데, 1초가 최대인 이유는 애초에 모든 애플리케이션에서 너무 긴 시간이다. (동일 리전 내 RDS Aurora MySQL의 경우 1.5 ms 이내)
AWS Aurora MySQL을 쓰면 aws_rds_mysql_aurora_binlog_replica_lag_average라는 메트릭을 제공한다.
초 단위로 바이너리 로그의 복제 지연을 기록한 메트릭이다. (AWS 짱!)
복구 시간
복제본에 지연이 상당할 때 가장 시급한 질문은 언제 복구될 것인가? 이다.
정확한 답은 없는데 알아야할 것은 지연된 원인만 해결되면 항상 복구된다.
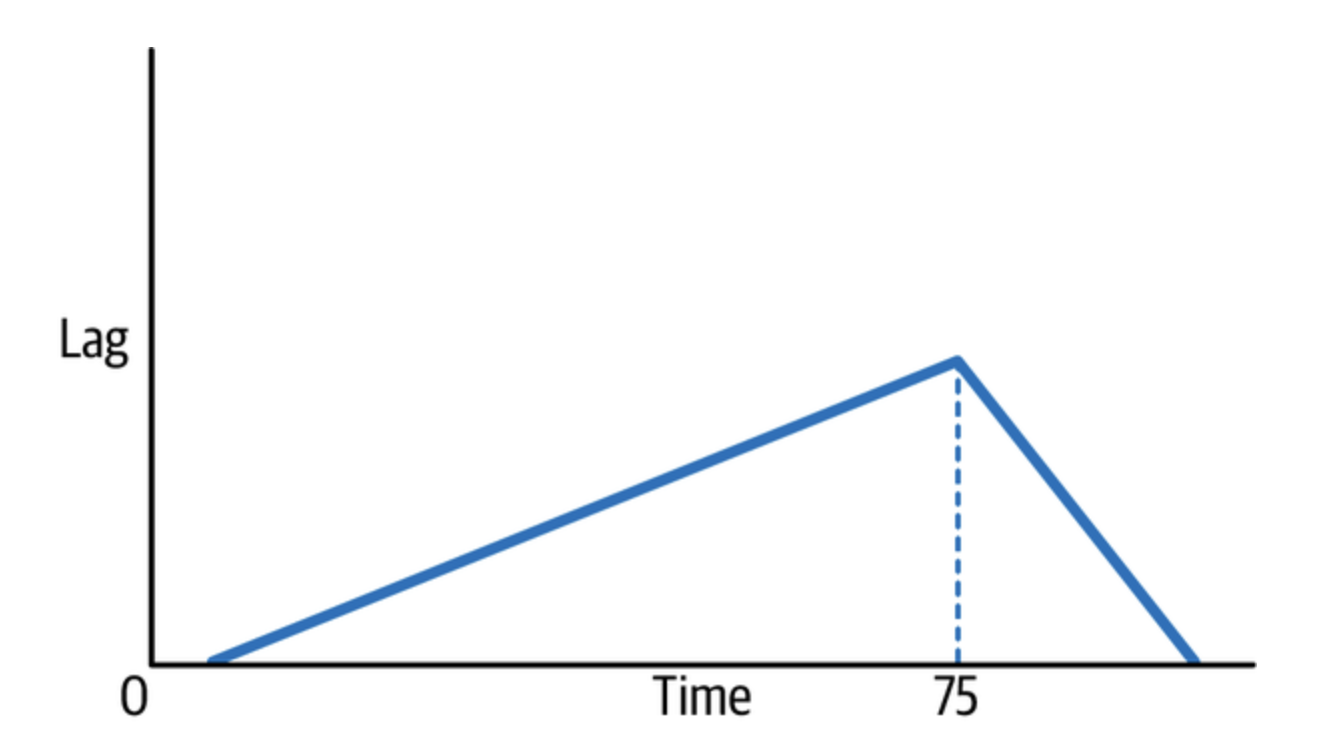
복제 지연 특성 상 원인이 해결될 때까지 바이너리 로그 이벤트가 쌓이다가, 원인만 해결되면 매우 빠르게 해결된다.
I/O 스레드가 릴레이 로그에 덤프하는 것보다 SQL 스레드가 적용하는 속도가 더 빠르다.
따라서 가장 중요한 것은 복제 지연의 원인을 해결하는 것이며, 어차피 해결되기 전까지는 증가할 것이기 때문에 값을 신경쓰지 마라.
저자 경험 상, 일 단위로 복제 지연이 발생한 경우는 변곡점 이후 몇 시간 내에 복구. 분 단위 지연은 커피 한 잔 다 마시기 전에 회복될 때가 많음.
다시 말하지만 정답은 없고, 항상 복구 된다는 것을 생각해보면 복구 시간은 별로 유용하거나 의미가 없다.
가능한 빨리 원인을 찾아 수정하도록!!!
연습으로 pt-heartbeat 도구를 써보는 적용해보는 것이 있는데 별로 무의미한 것 같아서 AWS Aurora MySQL 문서를 가져왔습니다.
원본: Replication with Amazon Aurora MySQL
최대 15개의 레플리카를 쉽게 추가하고 제거할 수 있고 자동 fail over, ro 디비로의 트래픽을 고루 분산시켜준다.
여러 가지 옵션으로 사용할 수 있다.
- Aurora global database를 사용해서 최대 5개의 리전으로 클러스터를 구성할 수 있다.
- 같은 리전이라면 바이너리 로그 기반으로 클러스터를 구성할 수 있다.
- RDS MySQL을 원본 DB로 하고 aurora로 read replica를 구성할 수도 있다.
- Aurora MySQL 클러스터와 다른 외부 DB를 GTID(전역 트랜잭션 식별자) 방식으로 replica 구성 가능하다.
Aurora MySQL도 바이너리 로그 이벤트 기반이지만 AWS 자체의 다중 AZ 동기화 복제를 통해 더 나은 가용성과 성능을 제공한다.
클러스터 볼륨을 공유하는 방식으로 고속 복제를 한다고 하는데 자세한 것은 비공개인듯...
