API의 레이턴시를 측정하다가, stream()을 사용하는 구간에서parallel()로 비동기를 적용해 성능을 높일 수 있겠다는 생각이 들었다. 그런데 이전에 CompletableFuture을 적용했다가 오히려 쓰레드간 경합 때문인지 속도가 더 느려진 경험이 있었다.
따라서 이번에는 java에서 비동기를 사용할 수 있는 방법들에 대해 공부하고, 프로젝트에 어떤 것이 가장 적합할지 결정해보고자 한다.
Reactive Stream
https://www.reactive-streams.org/
"Reactive Stream의 목적은 non-blocking backpressure을 통해 비동기 스트림 처리의 표준을 제공하는 것이다."
Reactive Stream을 이해하기 위해서는 먼저 non-blocking과 backpressure에 대한 이해가 필요하다.
Non-blocking이란?
Blocking과 Non-Blocking의 차이는, 다른 요청의 작업을 처리하기 위해 현재 작업을 block하는지의 여부에 달려있다.
Blocking의 예시는 다음과 같다. shell에서 vi 명령어를 입력해 부모로부터 자식 프로세스가 fork()되면, 문서 편집이 종료될때까지 부모 프로세스가 wait() 상태로 기다렸다가 자식 프로세스의 exit()을 받아 처리한다.
반대로, 부모 프로세스가 Non-Blocking 상태로 자식의 종료를 기다리지 않고 할 일을 계속 처리한다면, 자식 프로세스는 종료되었으나 부모 프로세스가 해당 프로세스의 상태를 확인하지 않는 Zombie 상태가 될 수 있다.
BackPressure(배압)이란?
https://reactivemanifesto.org/ko/glossary#Back-Pressure
BackPressure에 대한 용어 설명은 다음과 같다.
한 컴포넌트가 부하를 이겨내기 힘들 때, 시스템 전체가 합리적인 방법으로 대응해야 한다. 과부하 상태의 컴포넌트에서 치명적인 장애가 발생하거나 제어 없이 메시지를 유실해서는 안 된다.
"컴포넌트가 대처할 수 없고 장애가 발생해선 안 되기 때문에 컴포넌트는 상류 컴포넌트들에 자신이 과부하 상태라는 것을 알려 부하를 줄이도록 해야 한다."
이러한 배압은 시스템이 부하로 인해 무너지지 않고 정상적으로 응답할 수 있게 하는 중요한 피드백 방법이다. 배압은 사용자에게까지 전달되어 응답성이 떨어질 수 있지만, 이 메커니즘은 부하에 대한 시스템의 복원력을 보장하고 시스템 자체가 부하를 분산할 다른 자원을 제공할 수 있는지 정보를 제공할 것이다.
Reactive Stream의 목적
그렇다면, non-blocking과 backpressure을 이용해서 어떤 목적을 달성하고자 하는 것일까.
The most prominent issue is that resource consumption needs to be controlled such that a fast data source does not overwhelm the stream destination.
비동기 처리에서의 가장 중요한 문제는 수신측에서 소비할 수 있는 데이터 스트림(특히 "live" 데이터와 같이 빠르고 양이 미리 결정되지 않은 데이터) 범위를 넘지 않도록 리소스 소비의 제어가 필요하다는 것이다.
따라서 Reactive Stream의 주된 목적은, 비동기로 데이터를 처리하는 시스템에 얼마만큼의 data가 들어올지 예측 가능하도록 하는 것이며 이를 위해 BackPressure 을 사용한다.
이 때, Non-Blocking 통신은 수신자가 활성화되어 있을 때만 자원을 소비할 수 있기 때문에 시스템 부하를 억제할 수 있으므로 Reactive Streams의 모든 측면에서 완전히 Non-Blocking & Asynchronous 하도록 주의를 기울여야 한다.
명세서
https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.3/README.md
Publisher
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}Publisher는 무한한 양의 data를 제공하며, Publisher.subscribe(Subscriber) 형식으로 Subscriber와 연결을 맞는다.
Subscriber
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}Subscriber는 Subscription을 등록하고, Subscription에서 오는 신호 onNext, onError, onComplete에 따라 동작한다.
onSubscribe onNext* (onError | onComplete)?- onSubscribe: Subscriber가 항상 신호를 받을 준비가 되어 있다는 의미
- onNext: Publisher가 전송하는 데이터 수신
- onError: 실패가 발생한 경우
- onComplete: 더이상 사용할 수 있는 신호가 없는 경우
위의 동작은 구독이 취소될 때까지 계속된다.
Subscription
public interface Subscription {
public void request(long n);
public void cancel();
}Publisher와 Subscriber를 중계한다.
- request: Subscriber가 Publisher에게 데이터를 요청하는 개수
- cancel: 구독 취소
Processor
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {}Processor는 Publisher에서 생성된 데이터를 받아 변환, 필터링, 가공하고 Subscriber에게 전달하는 중간 단계이다.
CompletableFuture
Reactive Stream이 다수의 이벤트를 다루는데 중점을 둔다면, CompletableFuture은 단일 값의 비동기 처리에 적합하다. 즉, 일회성의 무거운 작업을 여러개의 CPU로 나누어 처리하는 것으로 우리가 일반적으로 생각하는 thread를 생성해 작업을 위임하는 비동기 방식이다.
CompletableFuture의 목적
1. 단일 값의 비동기 처리
주로 특정 계산 및 작업을 비동기적으로 수행하고 결과를 단일 값으로 반환할 때 사용
2. Callback 기반의 연결
콜백 함수를 사용하여 성공 또는 실패에 대한 처리를 구현할 때 사용
3. Future 기반의 비동기 작업 처리
Java5에서부터 제안된 Future 인터페이스를 확장하여 비동기 작업을 처리할 때 사용
명세서
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {}Future와 CompletionStage 인터페이스를 구현한다.
CompletionStage
비동기 연산 Step을 제공해, 체이닝 형태로 조합이 가능하며 완료 후 콜백이 가능하다.
따라서 계산의 완료는 단일 단계의 완료 + 다른 여러 단계 중 하나로 이어질 수 있음을 의미하며, 각 단계에서 발생한 에러를 관리하고 전달할 수 있다.
CompletableFuture에서 사용하는 메서드는 아래의 게시글을 참고하자.
https://dev-coco.tistory.com/185
ThreadPool 설정(선택)
ThreadPoolTaskExecutor로 Thread pool 크기를 직접 설정할 수도 있다.
private int CORE_POOL_SIZE = 3;
private int MAX_POOL_SIZE = 10;
private int QUEUE_CAPACITY = 10000;
@Override
public Executor getAsyncExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(CORE_POOL_SIZE); //Thread pool 기본 크기
executor.setMaxPoolSize(MAX_POOL_SIZE); //Thread pool 최대 크기
executor.setQueueCapacity(QUEUE_CAPACITY); //대기열 크기
executor.initalize(); //Thread pool 초기화
return executor;
}기본적으로 CORE_POOL_SIZE로 세팅된 3개의 thread로 동작한다. 그 이상의 요청이 들어왔을 때에는 QUEUE_CAPACITY에서 대기하게 되며, 위의 예시에서 QUEUE_CAPACITY에 10,000개 이상의 대기열이 발생하면 쓰레드 풀은 MAX_POOL_SIZE인 10개로 동작하게 된다.
⭐main thread return에 관한 두 가지 방법
두개 작업의 합을 요청자에게 전달해야 하는 상황을 가정하자. 각 작업은 계산을 완료하는데 각각 1초, 2초가 소요된다. 동기적으로 작업이 수행된다면 1개의 Thread로 총 3초가 소요될 것이다.
private Integer work_1() {
TimeUnit.SECONDS.sleep(1);
return 1;
}
private Integer work_2() {
TimeUnit.SECONDS.sleep(2);
return 2;
}비동기적으로 수행하는 방법 1
첫 번째 방법은 작업1과 작업2를 동시에 진행하고, main thread가 그 결과를 기다리는 방법이다. 3개의 Thread가 필요하며 작업 시간은 더 오래 걸리는 시간에 수렴해 총 2초가 소요된다.
public void async_1() throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
CompletableFuture<Integer> value_1 = new CompletableFuture<>();
CompletableFuture<Integer> value_2 = new CompletableFuture<>();
executorService.submit(() -> value_1.complete(work_1()));
executorService.submit(() -> value_2.complete(work_2()));
System.out.println("sum = " + (value_1.get() + value_2.get()));
}그렇다면 시간을 단축했으니 해당 방법이 무조건 더 좋은 것일까?
그렇지 않다. 이 방법은 thread들이 아무 일도 하지 않고 thread를 점유만 하고 있는 시간이 길다.
- main thread: 2초간 block
- work_1: 1초간 아무 일도 하지 않고 thread 점유
이 때, 아무 일도 하지 않는 threads가 thread pool에 반환되지 않아 다른 요청이 사용할 수 있는 thread의 수가 부족하다는 문제가 발생한다.
비동기적으로 수행하는 방법 2
이를 해결하기 위해서는 main thread를 바로 리턴시키는 방법을 선택할 수 있다. 즉, 응답을 받을 thread를 별도로 생성 및 지정하여 결과를 처리하면 된다.
public void async_3() throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(3);
CompletableFuture<Integer> value_1 = new CompletableFuture<>();
CompletableFuture<Integer> value_2 = new CompletableFuture<>();
CompletableFuture<Integer> value_3 = value_1.thenCombine(value_2, (a, b) -> a + b);
executorService.submit(() -> value_1.complete(work_1()));
executorService.submit(() -> value_2.complete(work_2()));
executorService.submit(() -> {
try {
System.out.println("sum = " + (value_3.get()));
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
}위의 방법을 적용하면, I/O 대기가 있는 상황에서 thread를 조금 더 효율적으로 사용할 수 있다.
위의 예시는 아래의 글을 참고하였다.
https://sabarada.tistory.com/99
ParallelStream
Java8에서 등장한 stream은 병렬 처리를 쉽게 사용할 수 있도록 메서드를 제공한다. 기존의 stream()에 parallel()을 추가하거나, parallelStream()을 사용하면 알아서 ForkJoinFramework 방식을 이용해 작업을 분할하고, 병렬적으로 처리한다.
Fork/Join Framework
분할 정복과 비슷하게 작업들을 분할 가능할 만큼 쪼개고, Work Thread로 작업 후 합쳐서 결과를 만들어낸다.
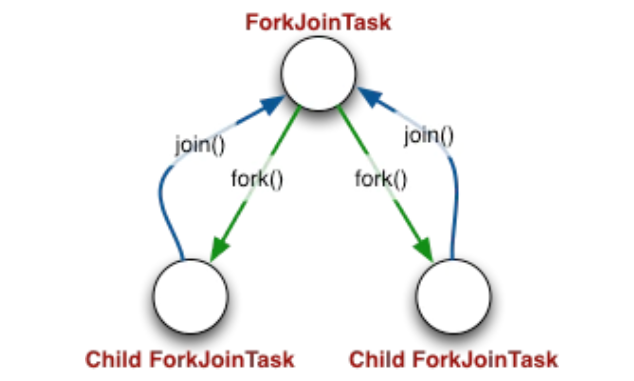
Fork/Join Framework은 AbstractExecutorService 클래스를 확장한 ForkJoinPool에 따라 동작한다.
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ForkJoinPool.html
ForkJoinPool은 다른 ExecutorService와는 달리 Work-Stealing 메커니즘을 사용하기 때문에, 대부분의 Task가 하위 Task를 생성하는 경우나 외부 클라이언트에 의한 Small Task가 많을 때 효과적이다. 간단히 이해하자면, stream()을 사용하는 상황들을 생각보면 될 듯 하다.
Work-Stealing 메커니즘이란
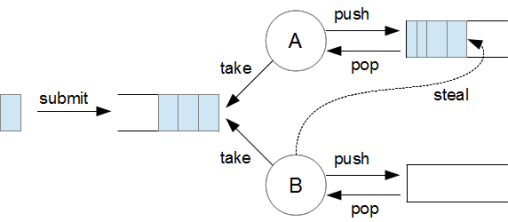
- task가 submit되면 inbound queue에 task가 들어간다.
- A, B 각 thread는 각자 큐(deque)가 있어 inbound queue에서 task를 가져다가 처리한다.
- 그림의 B처럼 큐에 task가 없으면 A의 task를 steal해 처리한다. 때문에 CPU 자원이 놀지 않고 최적의 성능을 낼 수 있다.
그럼, N개의 task가 발생하는 상황(ex. stream() 하려는 Array에 원소 N개)에서는 thread가 항상 N개만큼 생성되는 것일까?
그렇지는 않다. Fork/Join Framework의 thread수는 CPU Core 개수만큼 생성된다. 따라서 Core가 N개일 때, thread 하나는 메인 스레드가 되며 나머지 N-1개가 ForkJoinPool 스레드이다.
예제 코드
(로컬 PC의 CPU Core는 6개이다.)
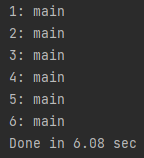
1. 순차적으로 thread를 실행했을 때
public static void main(String[] arg) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
long start = System.currentTimeMillis();
numbers.forEach(number -> {
try {
Thread.sleep(1000);
System.out.println(number + ": " +Thread.currentThread().getName());
} catch (InterruptedException e) {}
});
long duration = (System.currentTimeMillis() - start);
double seconds = duration / 1000.0;
System.out.printf("Done in %.2f sec\n", seconds);
}
2. 병렬 스트림을 이용해 thread를 실행했을 때
public static void main(String[] arg) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
long start = System.currentTimeMillis();
numbers.parallelStream().forEach(number -> {
try {
Thread.sleep(1000);
System.out.println(number + ": " +Thread.currentThread().getName());
} catch (InterruptedException e) {}
});
long duration = (System.currentTimeMillis() - start);
double seconds = duration / 1000.0;
System.out.printf("Done in %.2f sec\n", seconds);
}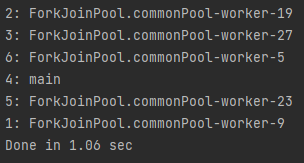
parallelStream()을 추가하면서 6.08초가 소요된 시간이 1.06초로 줄었다.
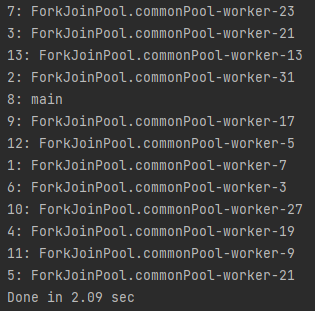
thread의 수를 계속 늘려나가다보니, 12개까지는 1.06초 내에 완료가 되었으나, 13개부터 2.09초가 소요되었다.
실질적으로는 코어*2배의 thread가 생성되는 듯 하다.
3. Custom ForkJoinPool 설정
ForkJoinPool customForkJoinPool = new ForkJoinPool(6);
customForkJoinPool.submit(() -> numbers.parallelStream()
.forEach(..)
customForkJoinPool.shutdown();직접 스레드 개수를 지정할 수도 있다.
ParallelStream의 주의 사항
1. Thread Pool 공유
별도로 Custom ForkJoinPool을 설정하지 않는다면, 하나의 Common ForkJoinPool을 모든 ParallelStream이 공유한다.
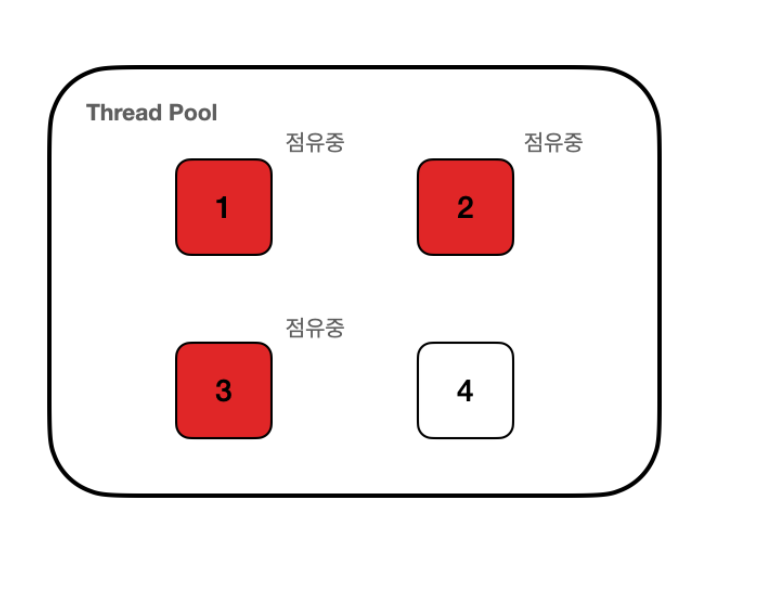
따라서, Thread를 사용중인 곳에서 thread를 반납하지 않고 계속 점유한다면 다른 곳에서는 사용하지 못하고 대기한다는 문제가 발생한다. 때문에 blocking I/O가 발생하는 작업은 ParallelStream을 사용하기에 적합하지 못하다.
만약 stream별로 pool을 생성하고 싶다면 위에서 작성한 Custom ForkJoinPool을 설정하면 된다.
2. Custom Thread Pool에서의 메모리 누수 주의
-
물리적인 코어 수보다 스레드를 더 생성할 경우: 스레드 관리 오버헤드와 빈번한 컨텍스트 스위칭으로 성능 저하 발생
-
사용한 thread pool은 명시적으로 종료: default로 사용되는 Common Pool은 정적이므로 메모리 누수가 발생하지 않지만, Custom Pool은 참조 해제되지 않거나 GC로 수집되지 않을 수 있다.
customForkJoinPool.shutdown(); //명시적으로 종료하는 코드 추가3. fork(), join() 시간 고려
- array, arrayList: 전체 사이즈를 알 수 있는 경우에는 분할 처리가 빠르고 비용이 적음
- linkedList와 유사한 구조: 사이즈를 정확히 알 수 없는 구조는 분할되지 않고 순차 처리되므로 성능 효과가 낮다.
- 컬렉션 요소 수가 적거나 요소 당 처리 시간이 짧을 때: 병렬처리는 fork(), join(), 컨텍스트 스위칭 비용이 포함되므로 해당 경우에는 순차 처리가 더 빠를 수 있다.
