
https://arxiv.org/pdf/2212.06817
전체적 흐름은, Transfomer 모델을 활용한다. 즉, 입력으로 Lagunage Instruction랑 이미지를 주는데 이때, 이미지 Features를 Lagunage Instruction으로 필터링하여 압축된 Features로 출력 Action을 선택한다.
[ Abstract ]
대규모, 다양한, 특정 Task에 얽매이지 않은 데이터셋으로부터 Transferring Knowledge을 함으로써, 모델은 특정 Task를 추가 데이터 없이 바로 수행하거나 소량의 과제별 데이터셋만으로도 높은 성능을 발휘할 수 있다. 이러한 능력은 컴퓨터 비전, 자연어 처리, 음성 인식 등 다른 분야에서 입증되었으나, 현실 로봇 데이터 수집이 어려워 로봇 분야에서는 아직 검증되지 않았다. 본 연구는 로봇 분야에서 이러한 일반화 가능한 모델의 성공 열쇠 중 하나가 Task-Agnostic 기반의 Train과, 다양한 로봇 데이터를 받을 수 있는 high-capacity architectures에 있다고 주장한다. 이 논문에서는 Robotics Transformer라 불리는 모델을 제안하며, 이는 확장 가능한 모델 특성을 보인다. 또한, 데이터 크기, 모델 크기, 데이터 다양성에 따른 일반화 능력을 평가하여 다양한 모델 클래스를 연구하고, 실제 로봇이 현실 과제를 수행하는 대규모 데이터를 통해 결론을 검증한다.
[ INTRODUCTION ]
Imitation or Reinforcement으로 이루어지는 End-to-end robotic learning은 컴퓨터 비전 및 자연어 처리와 같은 다른 분야에서 Single 과제를 해결하기 위해 Task별 데이터셋을 수집, 라벨링하고 적용하는 Supervised Learning 접근 방식을 반영하지만, 과제들 간의 상호작용은 거의 없다. 반면 최근 몇 년 동안, 비전과 자연어 처리 등 분야에서는 소규모 데이터셋과 모델의 분리된 사용에서 벗어나, 대규모 데이터셋을 사용하여 널리 일반화 가능한 모델을 사전 학습하는 방향으로 전환되었다.이러한 일반화 모델은 기존 소규모 데이터셋으로 특정 분야를 학습한 모델보다 Single Task에 더 효율적으로 적용할 수 있다.
특정 Task별로 데이터를 많이 수집하지 않고도 일반화된 모델이 학습을 잘 할 수 있는 상황을 만드는 것은 중요하지만, 특히 로봇 분야에서는 데이터셋이 고도로 엔지니어링된 자율적 운영이나 비용이 많이 드는 인간의 Test가 필요할 수 있어 더 중요한 문제이다.
이에 따라 본 연구는 다양한 로봇 Task를 포함한 데이터로 Single, 고성능의 Multi Task 백본 모델을 학습할 수 있을까? 이러한 모델이 새로운 과제, 환경 및 객체에 대해 제로샷 일반화를 보여줄 수 있을까?에 대해 연구하였다.
- RT-1(Robotics Transformer 1)의 개요도
본 연구는 13대의 로봇을 사용하여 17개월 동안 수집한 약 130,000 에피소드와 700개 이상의 과제를 포함하는 데이터셋을 사용하여 다양한 데이터셋 측면을 평가한다. 또한 위 그림의 RT-1(Robotics Transformer 1)이라는 새로운 아키텍처를 제안하며, 고차원 입력과 출력(예: 카메라 이미지, 지시문, 모터 명령)을 Transformer에서 사용할 수 있도록 압축된 토큰 표현으로 인코딩하여 실시간 제어를 가능하게 한다.
- RT-1의 능력에 대한 간략한 개요
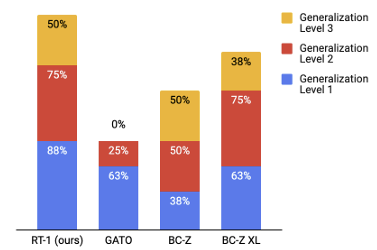
본 연구의 실험은 RT-1이 이전 기술보다 크게 향상된 일반화 및 강건성을 보여줄 뿐만 아니라 모델과 Train 세트의 구성에서 많은 설계 선택을 평가하고 검증한다. RT-1은 700개 이상의 훈련 지침을 97% 성공률로 수행할 수 있으며, 새로운 Task, 방해 요소 및 배경에 대해 각각 25%, 36%, 18% 더 나은 성능을 보인다. 또한, RT-1은 시뮬레이션 또는 다른 유형의 로봇에서 데이터를 통합하여 원래 과제에서의 성능을 유지하면서 새로운 상황에 대한 일반화를 개선할 수 있음을 보여준다. RT-1의 능력에 대한 간략한 개요는 위 그림에서 확인할 수 있다.
[ PRELIMINARIES ]
- 로봇 학습 목표
Language Instruction와 시각 정보(이미지)를 통해 로봇이 Task를 해결하도록 정책 를 학습하려 한다. 이 환경은 Sequential Decision-Making 환경으로, 각 시점에서 로봇은 상태를 보고, Instruction에 따라 Action을 선택한다.
(1) 초기 시점과 정책(policies)
초기 시점에 에서 정책 는 Language Instruction()와 초기 이미지()를 받는다. 이를 통해 는 행동()를 선택하기 위한 Action 분포()를 생성한다.
(2) 반복적 의사 결정 과정
의사 결정은 시점 마다 반복된다. 정책 는 부터 현재 시점 까지의 모든 이미지 관측 을 사용하여 다음 Action 를 선택한다.
(3) 에피소드
특정 종료 조건이 충족될 때까지 계속되며, 이러한 반복 과정을 에피소드 로 정의된다. 즉, Instruction 동안 시간 부터 종료 시점 까지의 모든 관측과 Action 쌍이다.
(4) 보상과 정책 학습 목표
에피소드가 끝나면 에이전트는 Binary Reward()를 받는다. 이때 이면 로봇이 Instruction 를 성공적으로 수행한 것이다. 이때, 목표는 평균 Reward를 극대화하는 정책
를 학습하는 것이다.
- Transformer 사용:
RT-1은 Transformer 모델을 사용하여 정책 를 파라미터화한다. 본 연구에서는 Language Instruction과 Vision 정보를 입력 시퀀스로, Action을 출력 시퀀스로 매핑하여 학습한다.
- Imitation learning:
RT-1은 모방 학습을 통해 정책 를 학습한다. 여기서 는 데이터셋 에 기반하여 학습되며, 행동 복제(behavioral cloning) 방식을 사용한다. 이 방식은 주어진 이미지와 Language Instruction에서 Action의 Negative log-likelihood(loss)를 최소화하여 정책을 최적화한다.
[ SYSTEM OVERVIEW ]
대규모 데이터를 학습하고 일반화할 수 있는 로봇 학습 시스템 구축하는 것이 본 연구의 목표이다.
- 사용되는 이동형 조작 로봇. 이 로봇은 7 Degree-of-freedom arm, A two-fingered gripper, and A mobile base를 갖추고 있으며, 작업 전 준비 자세와 300x300 크기의 RGB 이미지를 제공한다.
로봇 및 환경은 위 사진의 로봇을 사용하여 주방 기반의 세 가지 환경에서 데이터 수집 및 평가한다.
데이터 구성은 인간의 Demonstrations을 통해 수집하며, 각 에피소드에는 로봇이 수행한 Instruction 의 텍스트 설명을 추가한다. 예를 들어, 한 에피소드에서 "콜라 캔을 집기"라는 지시가 주어진 경우, "집기(pick)", "콜라 캔(coke can)"과 같은 텍스트 설명이 포함되어, 로봇이 어떤 작업을 수행해야 하는지를 명확히 나타낸다.
RT-1 아키텍처은 앞서 말했듯이, 입력은 이미지와 Language Instruction이고 이미지와 텍스트는 사전 학습된 네트워크와 Token Learner를 통해 압축된 토큰으로 변환 후 Transformer로 Action을 생성한다. Action 출력은 팔과 베이스 제어를 포함한 총 11차원의 행동과 모드 전환 명령한다. 실행 속도는 RT-1은 3Hz로 실시간 제어를 수행하며 에피소드 종료까지 동작을 반복한다.
[ RT-1: ROBOTICS TRANSFORMER ]
(1) 모델
RT-1은 Transformer 아키텍처를 기반으로 하며, Instruction and image tokenization을 입력으로 받아 토큰화된 Action을 출력한다.
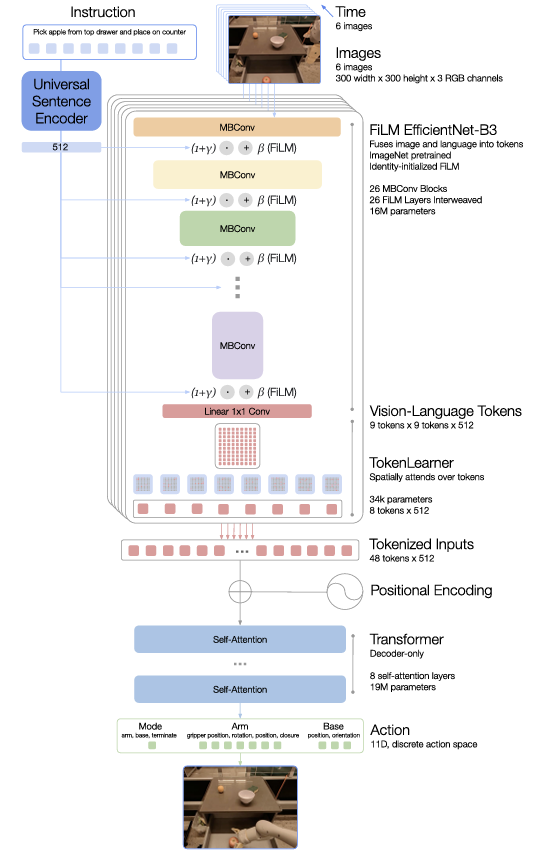
6개의 이미지를 ImageNet으로 사전 학습된 EfficientNet-B3를 사용해 300×300 해상도의 입력을 받아 9×9×512 Spatial Feature Map을 출력한다. 이 맵을 81개의 시각 토큰으로 압축해 Transformer로 전달한다.
Instruction은 Universal Sentence Encoder로 임베딩하여 이미지 토크나이저에 조건화하고, FiLM 레이어로 EfficientNet에 통합하여 Task 관련 이미지 Feature를 추출한다. 즉, FiLM 레이어는 Language Instruction의 정보를 이미지 Feature에 적용하는 일종의 필터 역할을 한다. 예를 들어, "상단 서랍에서 사과를 꺼내어 카운터에 놓으세요"라는 Instruction을 이미지에 반영하여, 사과와 서랍 같은 작업에 관련된 부분을 더 강조하게 만든다. 이로 인해 Instruction에 따라 이미지 특징이 조금씩 달라지고, 로봇이 그 지시를 수행하는 데 필요한 시각적 정보를 더 잘 파악할 수 있게 돕는다.
그 후, TokenLearner 모듈을 통해 81개의 시각 토큰을 8개의 최종 토큰으로 압축하여 Transformer로 전달한다. 압축은 모델의 Inference 속도를 높이기 위함이다.
최종 8개의 토큰은 이미지 히스토리와 결합되어 총 48개의 토큰으로 Transformer의 입력으로 사용된다. RT-1의 Transformer는 디코더 모델로, 이 토큰을 바탕으로 Action 토큰(팔 움직임 7개, 베이스 움직임 3개, 모드 전환 1개이고 각 차원에서 256개의 범위 중 하나를 선택)을 생성한다.
(2) 데이터
데이터 수집은 17개월 동안 13대 로봇으로 13만 개 이상의 시연 데이터를 사무실 주방에서 수집하였다.
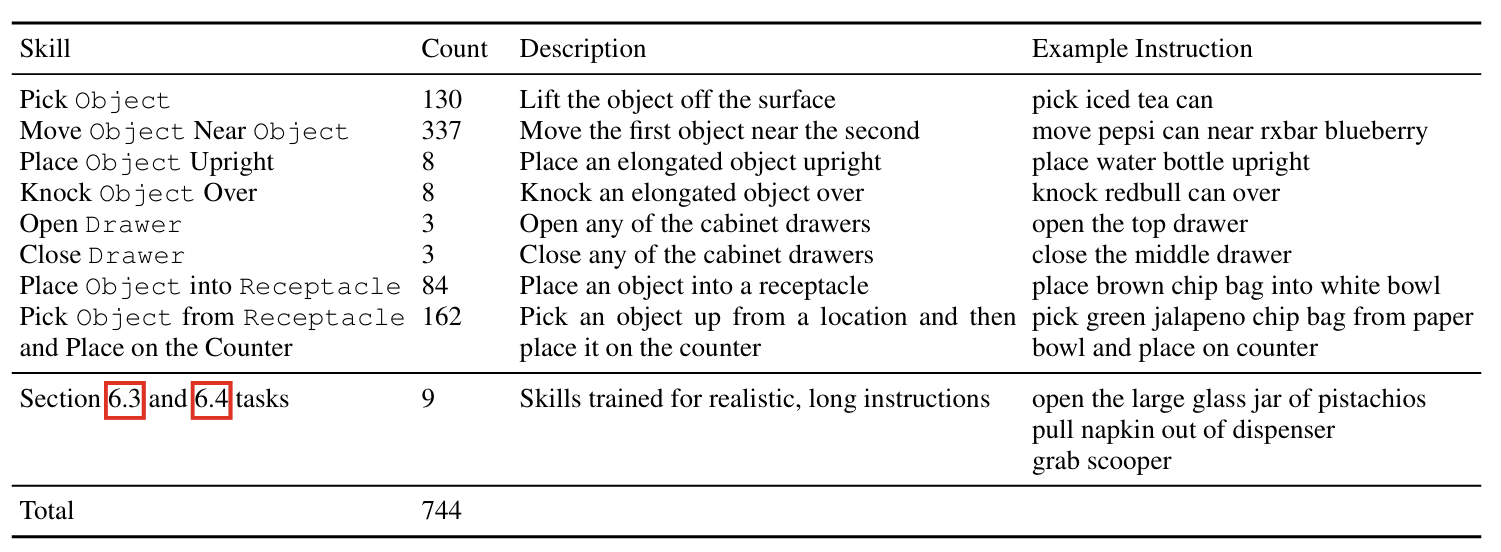
700개 이상의 Language Instruction 수행 가능, 동사(Skills)별로 Instruction를 그룹화해 성능 평가. 주요 스킬로는 집기, 놓기, 서랍 열기/닫기 등이 포함되며, 다양한 객체에 대해 일반화할 수 있도록 확장한다.
[ EXPERIMENTS ]
RT-1의 지시 수행 능력 및 제로샷 일반화, 이질적 데이터 소스를 통한 성능 향상, 복잡한 작업 시나리오에서의 일반화, 데이터 양과 다양성의 영향, 모델 설계 결정의 중요성 등에 대해 평가하였다.
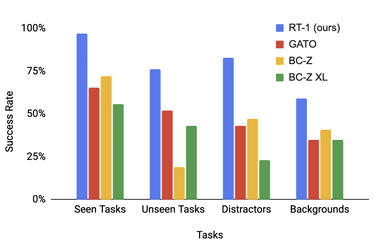
일반 성능은 RT-1은 학습된 작업에서 97%의 성공률을 보여, Gato 및 BC-Z보다 높은 성능을 기록하였다. 또한, RT-1은 새로운 지시에서 76%의 성공률을 보이며, 다른 모델보다 일반화 능력이 뛰어난 것을 보였다.
-방해 요소
강건성은 방해 요소와 배경 변동에 대해 RT-1은 각각 83%와 59%의 높은 성공률을 보였다.
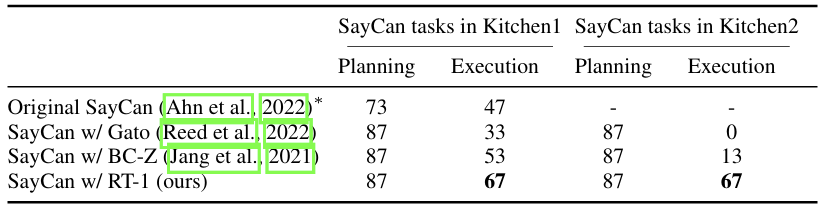
복잡한 작업 시나리오에서는 RT-1은 긴 작업에서도 뛰어난 성능을 발휘, 특히 SayCan 시스템(SayCan은 Language Instruction을 이해하고 이를 작은 작업 단위로 나누어, 로봇이 각 단계에서 수행할 행동을 쉽게 결정할 수 있도록 지원)과 결합하여 최대 50단계의 작업을 수행하였다. 이때 복잡한 시나리오는 예를 들어, "책상을 정리하고 모든 물건을 서랍에 넣기"라는 작업이다. 이 작업은 "물건 집기", "서랍 열기", "물건 넣기", "서랍 닫기" 등 여러 단계로 나뉜다.
- Various data ablations of RT-1
데이터 다양성이 데이터 양보다 더 중요한 역할을 함. 데이터를 다양하게 유지하는 것이 일반화 성능을 높이는 데 핵심적임.
[ CONCLUSIONS, LIMITATIONS AND FUTURE WORK ]
RT-1은 대규모 데이터를 학습하고, 새로운 작업과 환경에 잘 일반화할 수 있는 로봇 학습 모델이다. 13만 개 이상의 시연 데이터로 학습되어 97%의 성공률을 보이며, 시뮬레이션 및 다른 로봇 데이터도 통합하여 일반화 능력을 향상시켰다. SayCan과 결합하여 50단계의 긴 작업도 수행 가능하다.
다만, 시연자의 성능을 능가하지 못할 수 있다. 새로운 동작에는 일반화가 어렵다. 세밀한 조작 작업은 포함되지 않았다. 등의 단점이 존재한다.
향후 과제는 비전문가도 로봇을 훈련할 수 있는 방법 개발. 배경과 환경에 대한 강건성 강화. Attention 메커니즘과 메모리 개선. 등이 있다.
