진행상황
- UI 코드에서 데이터 어떻게 가져오는지 확인
- f1_server 개발 환경 세팅
- __init__.py에서 flask 인스턴스 생성
- url.py에 블루프린트 생성하여 라우팅 함수 관리
- 웹 애플리케이션 실행할 f1_server.py 생성
- f1.fasoo.com 의 db(FPMS)를 로컬 서버에 덤프
- models.py에서 db와 flask 연동 -ThreadedConnectionPool
- db_query.py에 쿼리문 저장
- makes.dict.py에 데이터를 딕셔너리로 변환해주는 함수 정의
파일 구조
F1-SERVER
| |__f1_server_cargo
| |__ __init__.py : flask 인스턴스 생성
| |__ url.py : blueprint로 라우팅 함수 관리
| |__models.py : DB 처리
| |__makes_dict.py : 데이터 딕셔너리로 변환
| |__db_query.py : 쿼리 데이터
|__f1_server.py : app 실행 파일커넥션 풀(connection pool)
DB에 직접 연결하는 경우 드라이버를 로드하고 커넥션 객체를 받아와야 하는데 매번 사용자가 요청할 때 마다 드라이버를 로드하고 커넥션 객체를 생성하여 연결하고 종료하는 것은 비효율적
-> 커넥션풀을 사용하자
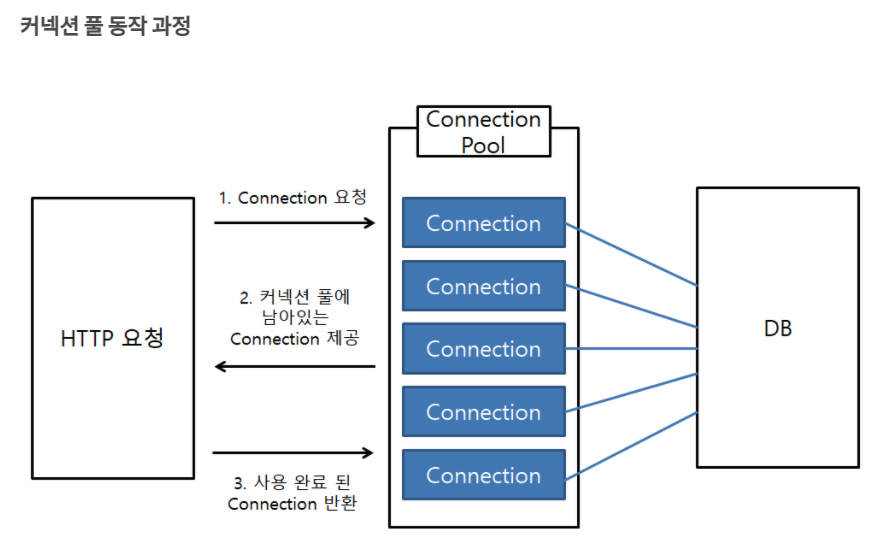
커넥션 풀은 웹 컨테이너(WAS)가 실행되면서 일정량의 Connection 객체를 미리 만들어서 pool에 저장했다가, 클라이언트 요청이 오면 Connection 객체를 빌려주고 해당 객체의 임무가 완료되면 다시 Connection 객체를 반납 받아서 pool에 저장하는 프로그래밍 기법
1. Container 구동 시 일정 수의 Connection 객체를 생성
2. 클라이언트의 요청에 의해 애플리케이션이 Connection Pool에서 Connection 객체를 받아와 DBMS 작업을 수행
3. 작업이 끝나면 Connetion Pool에 Connection 객체를 반납
장점
- DB 접속 설정 객체를 미리 만들어 연결하여 메모리 상에 등록해 놓기 때문에 불필요한 작업(커넥션 생성, 삭제)이 사라지므로 클라이언트가 빠르게 DB에 접속이 가능
- DB Connection 수를 제한할 수 있어서 과도한 접속으로 인한 서버 자원 고갈 방지가 가능
- DB 접속 모듈을 공통화하여 DB 서버의 환경이 바뀔 경우 쉬운 유지 보수가 가능
- 연결이 끝난 Connection을 재사용함으로써 새로 객체를 만드는 비용을 줄일 수 있음
Connection Pool 기본 동작 프로세스
- pool.ThreadedConnectionPool() 생성자를 통해서 Pool에서 사용할 변수를 선언
- 실제 사용은 getconn() 함수를 사용합니다.
- cursor()를 선언하여, connection 및 cursor 변수를 활용하여 SQL을 수행
- 다 썼으면 cursor.close()로 닫아주고, putconn() 함수를 사용하여 사용 해제

Rustacean🦀