MapReduce란?
MapReduce는 실제 대규모 데이터 셋을 처리하고 생성하는 프로그래밍 모델이나 관련 구현을 말합니다. 방대한 input 데이터를 여러개의 분산 처리 시스템에 저장하여 mapper에서 처리한 다음, 중간 결과를 reducer에서 하나로 합치자는 것이 핵심 아이디어입니다.
MapReduce 라이브러리는 연산을 map과 reduce 두가지 함수로 표현합니다.
map은 input 쌍을 사용하여 중간 키/값 쌍을 생성합니다. MapReduce 라이브러리는 동일한 중간 키 I와 관련된 모든 중간 값을 그룹화하여 reduce 함수로 전달합니다. reduce 함수는 중간 키 I 및 해당 키에 대한 값 집합을 accepts하고 이 값들을 병합하여 더 작은 집합을 형성합니다. 일반적으로 reduce 호출당 output 값이 0개 또는 1개만 생성됩니다. 중간 값은 iterator를 통해 사용자의 reduce 함수에 공급됩니다. 이를 통해 메모리에 fit in하기에 너무 큰 값 목록들을 처리할 수 있습니다.
MapReduce는 크게 split -> map -> reduce 순서로 진행됩니다.
아래 그림은 MapReduce 작업의 전반적인 흐름을 보여줍니다. 사용자 프로그램이 MapReduce 함수를 호출하면 다음과 같은 일련의 동작이 발생합니다.
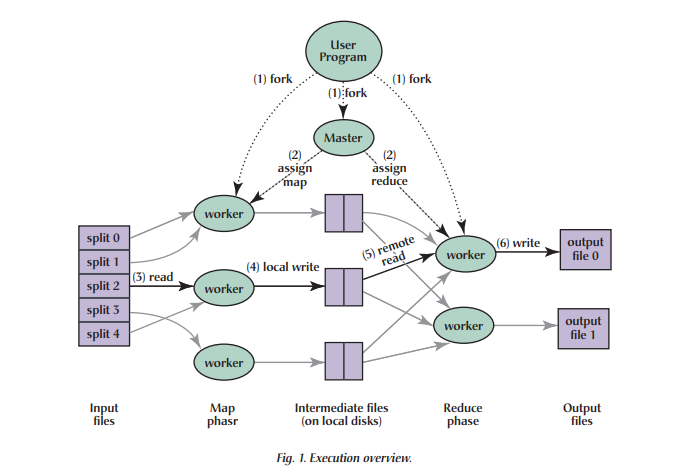
(1) fork
- 사용자가 user program을 실행시켜 프로세스가 실행되면 MapReduce 라이브러리는 먼저 input files를 (일반적으로) 한 개당 16-64MB의 M 조각으로 분할(split)하여 분산 파일 시스템에 저장합니다(optional한 매개 변수를 통해 사용자가 제어할 수 있음). 그런 다음, 머신의 클러스터에서 master노드와 worker노드들로 프로그램 복사를 시작합니다.
(2) assign map
- 프로그램의 복사본 중 하나인 master는 workers에게 작업을 할당(assign)합니다. master는 유휴상태(idle)의 workers를 선택하고 각 workers에게 map 혹은 reduce를 할당합니다. 이 때, 노드의 개수는 사용자가 지정할 수 있습니다.
(3) read
- map이 할당된 workers(이하 mapper)는 분산 파일 시스템으로부터 input split의 내용을 읽습니다. mapper는 input 데이터에서 키/값 쌍을 파싱하여 사용자정의 map 함수로 전달하고 map 함수는 생성된 중간 키/값 쌍을 메모리에 버퍼링합니다.
mapper는 출력(중간 키/값)을 HDFS 에 저장하지 않습니다 . 이것은 임시 데이터이며 HDFS에 쓰면 불필요한 여러 복사본이 생성되기 때문에 매퍼는 출력을 메모리 버퍼(RAM)에 기록합니다. 버퍼의 크기는 기본적으로 100MB이고 변경 가능합니다.
(4) local write
- 버퍼링된 쌍은 파티셔닝 함수(eg. key mod R(num of reducers))에 의해 R 영역으로 파티션되고 (이렇게 해주면 각각의 키 값들이 어느 reduce worker(이하 reducer)에서 처리되어야 하는 지를 구분할 수 있습니다.) 각각의 파티션은 Mapper의 로컬 디스크에 저장(spill)됩니다. 로컬 디스크에 버퍼된 쌍의 위치는 master에게 다시 전달됩니다.
spill
spill은 메모리 버퍼에서 디스크로 데이터를 복사하는 과정입니다. 버퍼의 내용이 특정 임계값 크기에 도달할 때 발생합니다. 기본적으로 백그라운드 스레드는 버퍼 크기의 80%가 채워지면 spill을 시작합니다. 100MB 크기의 버퍼의 경우 버퍼 내용물이 80MB 크기에 도달하면 spill을 시작합니다. reducer 작업을 재시작할 수 있는 체크포인트가 필요하므로 spill을 해야 합니다. 체크포인트는 reduce 작업 실패 시 spilled된 레코드를 사용합니다.
(5) remote read
- reducer가 master로부터 해당 위치에 대해 통지를 받으면 원격 프로시저 호출을 통해 mapper의 로컬 디스크에서 버퍼링된 데이터를 읽습니다. reducer는 자신에게 할당된 파티션에 대한 모든 중간 데이터를 읽고 네트워크를 통해 자신의 로컬 메모리 버퍼로 복사합니다. 버퍼에 데이터가 지정된 비율만큼 사용되면 mapper에서 처럼 로컬 디스크의 파일로 저장합니다. 중간 키를 기준으로 정렬하여 동일한 키의 모든 항목이 그룹화되도록 합니다. 일반적으로 여러 다른 키가 동일한 reduce 태스크에 매핑되기 때문에 정렬이 필요합니다. 중간 데이터의 양이 너무 많아서 메모리에 맞지 않으면 외부 정렬이 사용됩니다. mapping 이후 지금까지 일련의 과정을 셔플링(shuffling)이라고 합니다.
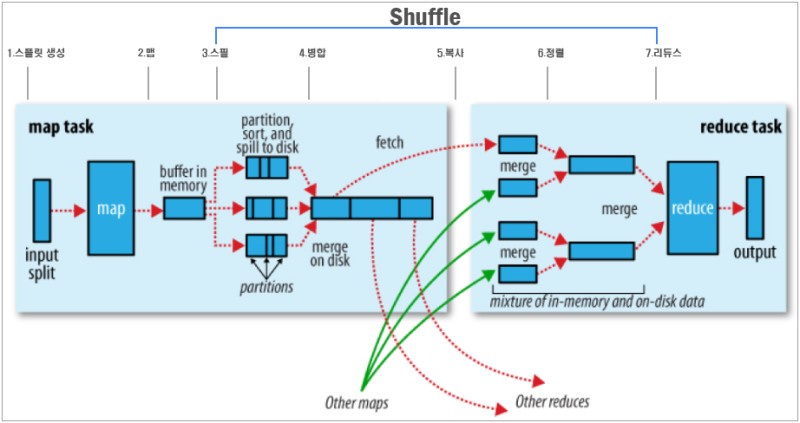
셔플링(shuffling)
map 에서 reduce까지 중간 키/값을 전달하는 일련의 과정을 셔플링이라고합니다. 즉, 시스템이 정렬을 수행하고 mapper의 output을 reducer의 input으로 전송하는 과정입니다. 셔플링은 하둡의 MapReduce 프레임워크가 알아서 시행하며, mapping이 완료되기 전에 시작될 수 있습니다. 셔플링은 지역성을 유지하여 성능을 향상시키려는 노력이라고 볼 수 있습니다.
1. Partitioning: 각각의 키 값을 기준으로 어느 reducer에서 처리되어야 하는지 파티션을 결정함
2. Sorting: 같은 파티션 내의 값들을 키 기준으로 정렬
3. Combining: 파티션 내의 값들을 키 기준으로 미리 reduce해 데이터의 양을 줄임
4. Spilling: 처리된 값들을 Mapper의 로컬 디스크에 저장
5. Remote Read: reducer들은 자신에게 할당된 파티션들만 mapper들로부터 읽어와 reduce 작업 준비
(6) write
- reducers는 정렬된 중간 데이터에 대해 반복적으로 작동하고, 각각의 고유한 중간 키를 만날때 마다, 키와 해당 중간 값 집합을 사용자가 정의한 reduce function으로 전달합니다. reduce function의 output은 글로벌 파일 시스템의 최종 output 파일에 추가됩니다.
최종 파일은 보통 reduce 작업당 하나이고 사용자가 지정한 이름을 갖습니다. 값들을 별도로 취합하지 않고 input file을 쪼개어 저장했을 때 처럼 분산 파일 시스템에 저장됩니다. 이렇게되면 사용자는 R 출력 파일을 하나의 파일로 취합할 필요 없이 다른 MapReduce 호출에 input으로 전달하거나 여러 파일로 분할된 input을 처리할 수 있는 다른 분산 파일 시스템에서 사용할 수 있는 장점이 있습니다.
Master의 데이터 구조
master는 여러 데이터 구조를 갖습니다. 각 map이나 reduce 작업에 대한 상태나 worker의 식별자를(nonidle 작업의 경우)저장합니다. master는 중간 파일 영역의 위치가 map에서 reduce로 전파되는 통로라고 할 수 있습니다. master는 mapper에 의해 생성된 R 중간 파일의 위치와 크기를 저장하고 업데이트합니다. 이 정보는 reducer에게 전달됩니다.
Worker Failures 처리
master는 주기적으로 모든 작업자를 ping 하는데, 일정 시간 동안 worker로부터 응답이 없으면 worker를 실패로 표시합니다. worker가 끝낸 모든 map 작업은 초기 유휴 상태로 재설정되므로 다른 worker에서 예약할 수 있습니다. 마찬가지로, 실패한 worker에서 진행 중인 map이나 reduce작업도 유휴 상태로 재설정되어 다시 예약할 수 있습니다. 완료된 map작업은 output이 시스템의 로컬 디스크에 저장되는데, 장애가 발생하면 액세스할 수 없으므로, 실패 시 작업을 재실행시킵니다. 완료된 reduce 작업은 output이 글로벌 파일 시스템에 저장되므로 재실행할 필요가 없습니다. map 작업이 worker A에 의해 먼저 실행되고 나중에 worker B에 의해 실행될 때(A가 실패해서), reduce 작업을 실행하는 모든 workers에게 재실행이 통보됩니다. MapReduce는 대규모 worker 장애에 대해 탄력적입니다.
지역성(Locality)
네트워크 대역폭은 우리의 컴퓨팅 환경에서 상대적으로 부족한 자원입니다. MapReduce는 input을 여러 복사본으로 나누어 서로 다른 시스템의 로컬 디스크에 저장합니다. master는 input 파일의 위치 정보를 고려하여 해당 데이터의 복제본이 있는 곳에 map 작업 예약을 시도하는데, 이를 실패하면 복제본 근처에서 map 작업 예약을 시도합니다. 대규모의 MapReduce 작업을 시행할때 대부분의 input 데이터가 로컬 디스크에서 읽혀진다고 생각하면 네트워크 대역폭을 상당 부분 보존할 수 있습니다.
Task Granularity
앞서 설명한 것처럼 map 단계를 M 조각으로, reduce 단계를 R 조각으로 세분화합니다. 이상적으로, M과 R은 worker 머신의 수보다 많아야합니다. 각 workers가 다양한 많은 작업을 수행하도록(M과 R을 크게) 하는 것은 동적 로드 밸런싱을 향상시키고 작업을 실패하더라도 다른 머신에 넘기면 되므로 빠른 복구가 가능합니다. 하지만 master는 O(M + R) 스케줄링 결정을 내리고 O(M x R) 상태를 메모리에 유지해야 하기 때문에 M과 R의 크기에 대한 실질적인 한계가 있습니다 (메모리 사용량에 대한 상수 요인이 작긴합니다.). 일반적으로 각 개별 작업이 대략 16MB에서 64MB의 input 데이터가 되도록 M을 설정하며(앞에서 설명한 locality 최적화가 가장 효과적임), 사용할 것으로 예상되는 worker 시스템 수의 작은 배수로 R을 설정합니다. 2,000개의 worker 머신을 사용하면 M=200,000 및 R=5,000으로 MapReduce 계산을 수행하는 것이 일반적입니다.
Backup Tasks
straggler는 비정상적으로 오랜 시간이 걸리는 머신으로, MapReduce 작업 시간을 지연시킵니다. straggler는 디스크 불량, 클러스터 스케줄링 시스템에 의한 대역폭 경쟁, 머신초기화 등의 다양한 이유로 발생합니다. straggler의 문제를 완화하기 위해 MapReduce 작업이 거의 완료되면 master는 진행 중인 나머지 작업의 백업을 예약합니다. 초기 상태 또는 백업이 완료될 때마다 작업이 완료된 것으로 표시됩니다. 이 메커니즘은 일반적으로 작업에 사용되는 연산 자원을 몇 퍼센트 이하로 증가시키도록 조정되어 있습니다. 이를 통해 대규모 MapReduce 작업을 완료하는 데 걸리는 시간을 크게 단축할 수 있습니다.
참고자료
- MapReduce: Simplified Data Processing on Large Clusters
by Jeffrey Dean and Sanjay Ghemawat - https://yeomko.tistory.com/31
- https://dataonair.or.kr/db-tech-reference/d-guide/data-practical/?mod=document&uid=400
- https://data-flair.training/forums/topic/explain-the-process-of-spilling-in-mapreduce/
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=pdc222&logNo=220732616451
