parquet의 github 주소 : https://github.com/apache/parquet-format
parquet
아파치 파케(parquet)는 데이터 처리 프레임워크, 데이터 모델 또는 프로그래밍 언어에 관계없이 하둡 에코시스템에서 사용가능한 컬럼나 방식의 저장 포맷이다.
parquet의 구조
파일 포맷(File format)
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"파케 파일은 헤더, 하나이상의 block, footer로 구성된다. 헤더는 파케 포맷의 파일임을 알려주는 4바이트 매직 숫자인 PAR1만 포함하고 있다. 파일 메타 데이터는 footer에 저장된다.
footer데이터는 포맷 버전, 스키마, 추가 키-값 쌍, 파일의 모든 블록에 대한 메타데이터와 같은 정보를 포함한다.
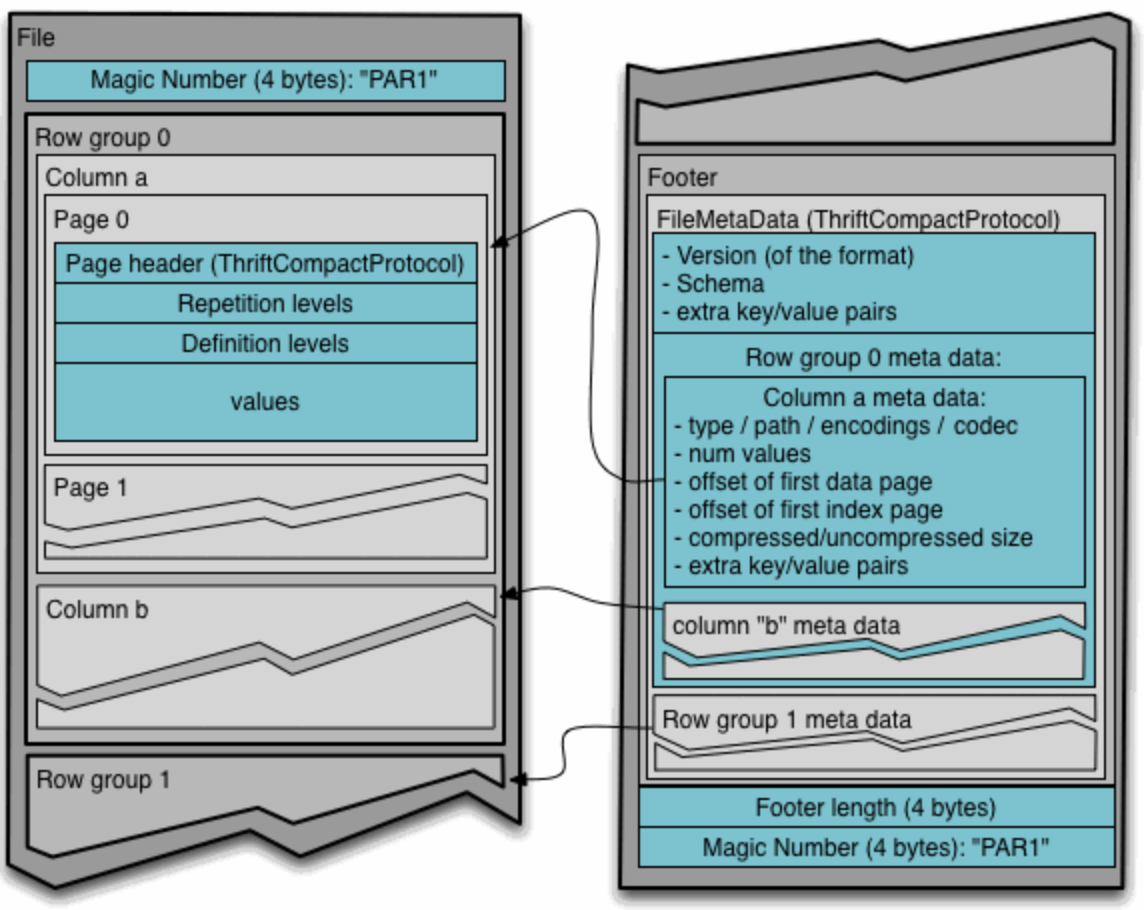
메타 데이터(meta data)
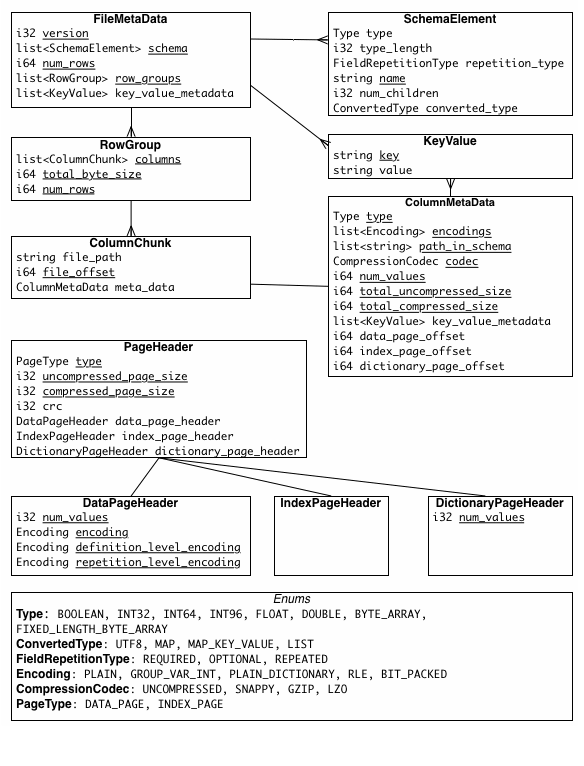
file metadata, column (chunk) metadata, page header metadata가 존재
모두 TCompactProtocol로 직렬화된 thrift 구조를 갖는다.
- file - hdfs파일로 반드시 메타데이터를 포함하고 실제 데이터는 필요x
- block(hdfs block) - 각 블록은 row group을 저장
- row group - column chunk로 구성
- column chunk - 특정 칼럼의 데이터 청크. row group에 속하며 파일 내에서 연속적. row group에 있는 하나의 칼럼당 하나의 칼럼 청크, 칼럼메타데이터
- page - 각 칼럼 청크의 데이터가 페이지에 기록됨. 각 페이지는 동일한 칼럼의 값만 포함하고 있어서 페이지 압축할때 유리함. 개념적으로 더이상 나눌수 없는 단위(압축이나 인코딩 관점에서)
Column chunks are composed of pages written back to back(연속적). The pages share a common header and readers can skip over page they are not interested in. The data for the page follows the header and can be compressed and/or encoded. The compression and encoding is specified in the page metadata.
메타데이터의 가능한 타입을 보면 String이 없다. 문자열은 UTF8 어노테이션을 가진 binary 기본 자료형으로 표현된다.
크기에 따른 포함 관계
file > row group > column chunk > pag
parquet파일 예제 코드
import pyarrow.parquet as pq
import pandas as pd
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'San Francisco', 'Los Angeles']
})
df.to_parquet('new_data.parquet')
new_file_path = "new_data.parquet"
new_parquet_file = pq.ParquetFile(new_file_path)
print("####################################################################")
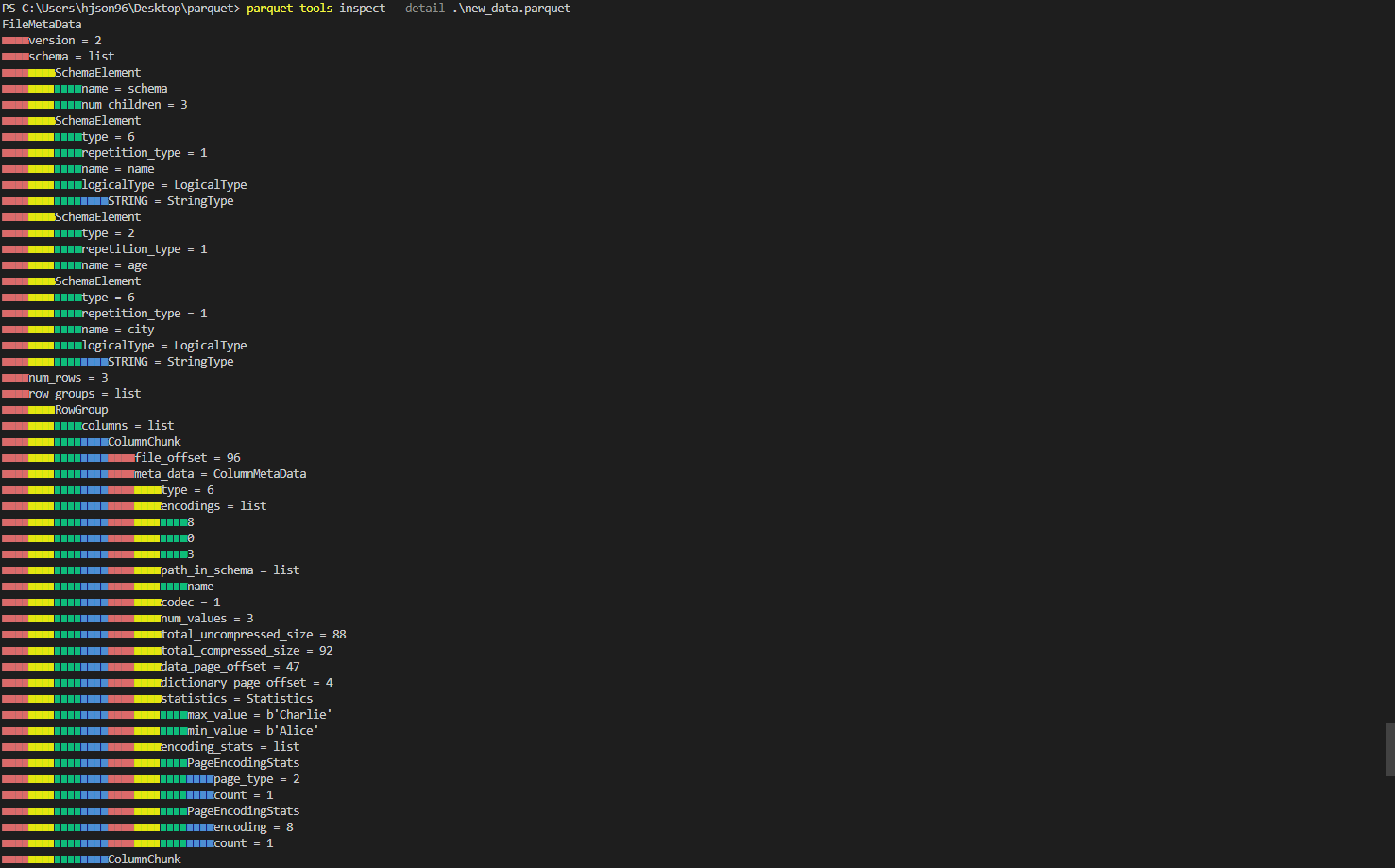
print("new_parquet_file.metadata: ", new_parquet_file.metadata)
print("####################################################################")
print("new_parquet_file.schema: ", new_parquet_file.schema)
print("####################################################################")
print("new_parquet_file.statistics: ", new_parquet_file.metadata.row_group(0).column(0).statistics)
print("####################################################################")
print(new_parquet_file)
print("####################################################################")
print(df)#결과
####################################################################
new_parquet_file.metadata: <pyarrow._parquet.FileMetaData object at 0x000001C642BB9490>
created_by: parquet-cpp-arrow version 11.0.0
num_columns: 3
num_rows: 3
num_row_groups: 1
format_version: 2.6
serialized_size: 2277
####################################################################
new_parquet_file.schema: <pyarrow._parquet.ParquetSchema object at 0x000001C64291AD40>
required group field_id=-1 schema {
optional binary field_id=-1 name (String);
optional int64 field_id=-1 age;
optional binary field_id=-1 city (String);
}
####################################################################
new_parquet_file.statistics: <pyarrow._parquet.Statistics object at 0x000001C642BB9620>
has_min_max: True
min: Alice
max: Charlie
null_count: 0
distinct_count: 0
num_values: 3
physical_type: BYTE_ARRAY
logical_type: String
converted_type (legacy): UTF8
####################################################################
<pyarrow.parquet.core.ParquetFile object at 0x000001C640B9BA50>
####################################################################
name age city
0 Alice 25 New York
1 Bob 30 San Francisco
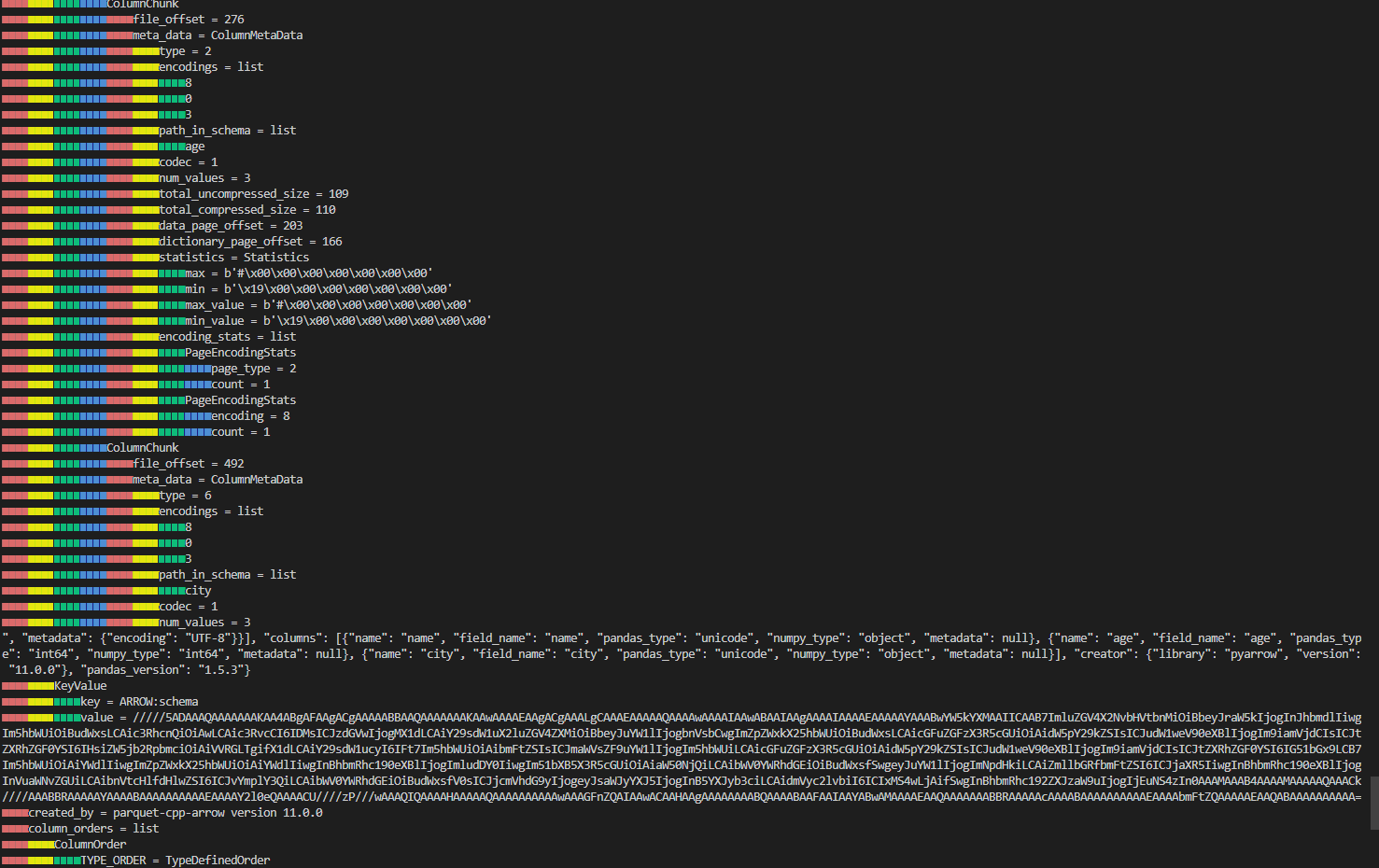
2 Charlie 35 Los Angelesparquet-tools로 세부정보 확인

병렬화 단위
- MapReduce - file/row group
- IO - column chunk
- encoding/compression - page
파일의 메타데이터는 모든 칼럼 메타데이터의 시작 위치를 포함. 메타데이터에 포함된 내용은 thrift 파일에서 확인 가능.
메타데이터는 single pass writing을 허용하기위해 데이터 뒤에 작성됨.
데이터와 메타데이터가 분리되어 설계됨. 여러개의 파케파일을 하나의 메타데이터로 참조할 수 있음.
Row group size
크기가 더 큰 row group은 더 큰 column chunk를 허용하므로 더 많은 순차적인 IO를 가능하게 한다. 더 큰 그룹은 write path에서 더 많은 버퍼링이 필요하다 (512MB ~ 1GB의 큰 row group을 권장). 전체 row group을 읽어야 할 수 있으므로 하나의 HDFS 블록에 완전히 맞도록 HDFS 블록 사이즈는 더 크게 설정해야 한다.
최적화된 읽기 설정은 다음과 같다.
row groups: 1GB
HDFS block size: 1GB
1 HDFS block per HDFS file
parquet의 주요 기능
- Dictionary encoding (String들을 압축할 때 dictionary를 만들어서 압축하는 방식, 길고 반복되는 String이 많다면 좋은 압축률을 기대할 수 있다)
- Column pruning (필요한 컬럼만을 읽어 들이는 기법)
- Predicate pushdown, row group skipping (predicate, 즉 필터를 데이터를 읽어 들인 후 적용하는 것이 아니라 저장소 레벨에서 적용하는 기법)
파케에서는 딕셔너리 인코딩이 디폴트.
중첩 인코딩(Nested Encoding)
중첩 칼럼들을 인코딩 하기 위해 파케는 정의 레벨(definition level)과 반복 레벨(repetition level)을 사용한 Dremel 인코딩 방식을 쓴다. 정의 레벨은 칼럼의 옵셔널 필드가 어느 정도 깊이로 정의되어 있는지를 나타내고(null의 위치 기준) 반복레벨은 각 필드의 반복되는 필드의 위치를 나타낸다. 정의 레벨과 반복 레벨의 최대값은 스키마에 의해 계산되는데 (얼마나 중첩되어 있는지..) 레벨을 저장하기 위한 최대 비트수를 정의한다. <- 그냥 밑에 트위터 기술 블로그를 보자...
Two encodings for the levels are supported BIT_PACKED and RLE. Only RLE is now used as it supersedes BIT_PACKED.
Dermel 인코딩 방식 관련 twitter 기술 블로그
https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet 참고
schema 구조
열 형식으로 저장하려면 스키마를 사용하여 데이터 구조를 설명해야함 (protocol buffers와 유사). 맵,리스트,세트와 같이 복잡한 타입이 필요없이 반복 필드와 그룹의 조합에 매핑될 수 있음.
스키마의 root는 "message" 라고 하는 필드그룹.
각 필드는 3개의 속성을 갖는다: repetition, type, name
type은 group 또는 primitive 타입(예: int, float, boolean, string)
repetition은 다음 세가지 중 하나 (맨 앞에)
- required: exactly one occurrence (무조건 하나)
- optional: 0 or 1 occurrence (있거나 없거나)
- repeated: 0 or more occurrences
아래는 address book이름의 스키마 예시
message AddressBook {
required string owner;
repeated string ownerPhoneNumbers;
repeated group contacts {
required string name;
optional string phoneNumber;
}
}
좋은 포스팅 잘 보고 갑니다. 감사합니다.