이 시리즈는 개념이 아예 없는 사람들을 위한 입문용 글이 될 예정입니다.
1. 데이터 베이스를 왜 알아야 하나요?
정의 :데이터 베이스란 데이터를 "정리된 형태로 저장"해둔 데이터의 집합을 의미한다.
-
정리된 데이터라 하면 엑셀파일로만 데이터를 다루면 정말 편리하겠지만, 엑셀/txt/일반 파일 내의 텍스트 등은, GUI환경(그래픽 기반 인터페이스)에서 다루기 위해, 또 각종 편의기능을 제공하기 위해 성능을 포기한 부분이 있다.
-
100개~ 1,000개의 데이터를 다루기 위해서는 엑셀을 사용하는것도 나쁘지 않겠지만, 사용자/주문/접속로그 등 하루에 몇천~몇만개 씩 쌓이는 데이터를 다루기 위해서는 속도가 중요하고, 속도를 위해서는 효율이 필수적이다.
-
정리된 데이터가 있다는 것은, 중학교의 학생들 목록을 알고 싶을 때 동네별로 동사무소를 돌아다니면서 특정 연령대의 사람을 찾지 않고, 중학교의 학생부를 찾을 수 있다는 것을 의미한다.
-
즉 데이터베이스는 데이터를 "정리된 형태로, 가능한 고성능으로" 다루기 위해 최적화된 툴이기 때문에, 코딩을 하기 위해서는 다룰 줄 알아야 하는 부분이 되겠다.
2. 데이터베이스란 무엇인가요?
- "데이터"란 무엇인가? 컴퓨터 내에 저장된 데이터는 0과1의 집합이고, 이는 보통 하드디스크나 메모리에 내에 저장되어 있을 것이다.
- 위에서 말한 것처럼, "정리된 데이터"라 함은 하드디스크, 메모리내에 저장된 데이터들의 주소의 목록을 저장해둔 것을 의미한다.
- 데이터베이스를 사용하면, 특정 학생을 찾고 싶을 때 학년 -> 반 -> 번호를 조회하는 것처럼, 혹은 이름/생년월일/사진 으로 조회하는 것처럼, 조회가 쉽게 가능해진다.
3. 기본용어
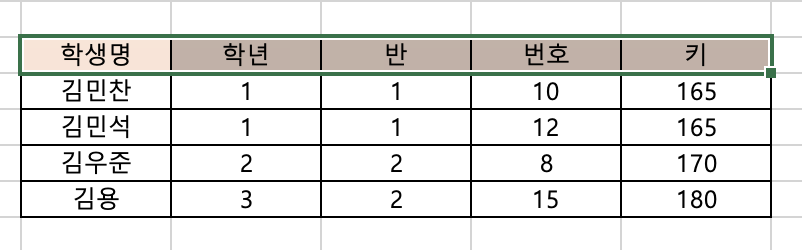
테이블, 필드, 레코드
-
필드
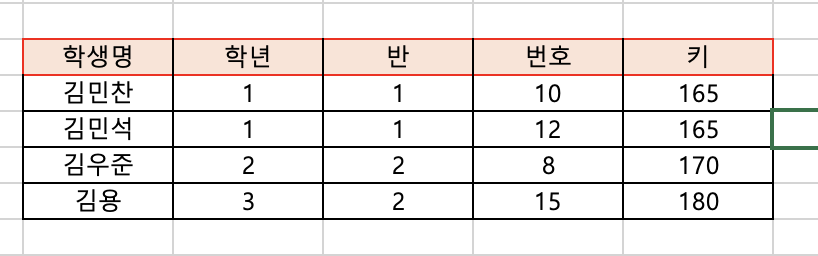
위의 사진에서, (학생명, 학년, 반, 번호, 키) 라는 다른 행들을 분류해주는 행을 필드, 속성, 프로퍼티 등 (field, attribute, property) 라는 이름으로 부른다.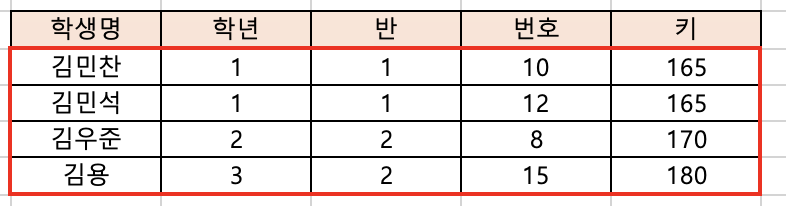
-
데이터
위의 사진에서, (학생명 : 김민찬, 학년 : 1, 반 : 1, 번호 : 10, 키 : 165 ) 라는, 완성된 하나의 행을 데이터, 레코드, 엔터티 (data, record, entity) 라고 한다. (* 엔티티라는 발음이 아니다. 엔터티라고 한다.)
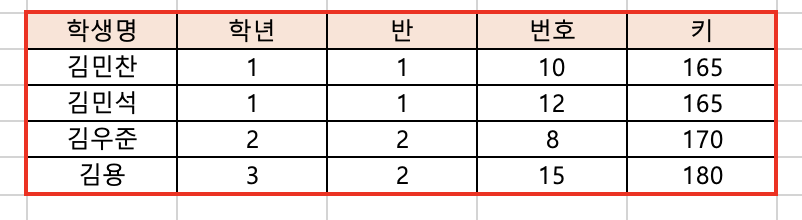
-
이렇게 필드와 레코드를 합치면 테이블이 된다.
