들어가기에 앞서
- 이 포스팅(시리즈)의 타겟은 다음과 같습니다.
- 대학에서 컴퓨터공학 등 기초 지식/이론을 배워본 적이 없는 사람
- HTML,JS,파이썬/자바 등으로 "Hello World!" 정도의 출력은 할 수 있는 사람
- 웹개발에 대해 공부를 하고 있는 사람
-
면접준비 용이라고 되어있는 여러 지식들을 공부하기 전에, 큰 그림을 이해 해서 더 효율적으로 공부하시길 바라며 적는 내용입니다.
-
웹개발자라면 "이정도는 알아야 하지 않을까?" 정도의 기초적인 지식의 내용을 포함하고 있습니다. 따라서 깊이 있게 파고들지 않을 것이며, 직접 시간을 들여서 공부하시는 것을 추천드립니다. 더 자세한 내용은 더 시간을 들여서 찾아봐주세요.
-
여기저기 긁어온 글과 링크로 구성되어있을 수 있습니다.
최대한 출처를 표기하도록 노력하겠습니다.
1. 개요
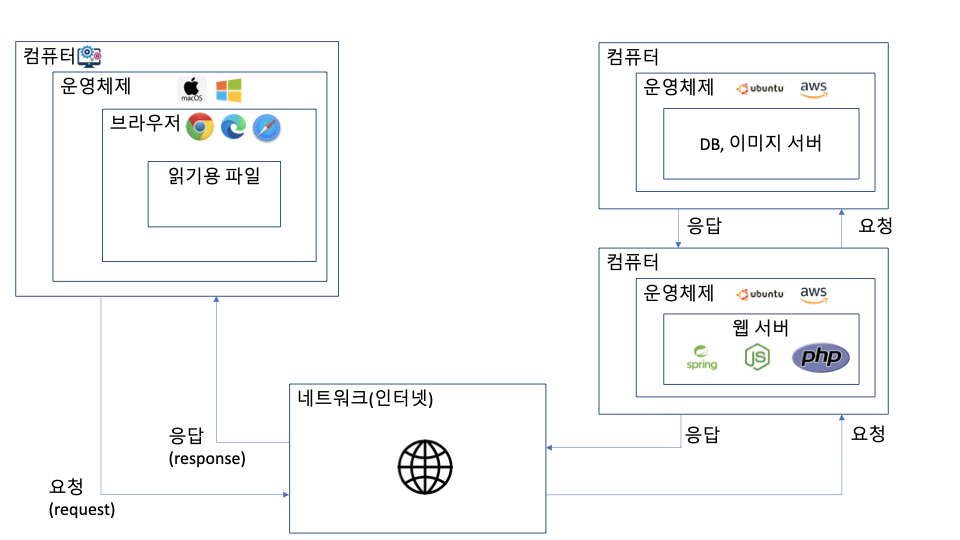
"내가 네이버에서 "구글" 이라는 단어를 검색했을 때, 어떻게 검색 결과가 내 화면에 나타날까?" 에 대해서 설명해보고자 합니다.
이 설명의 대략적인 흐름을 아래의 그림으로 표시해보겠습니다.
1. 흐름 설명
-
사용자는 브라우저에서 검색어를 누르고 "검색 버튼"을 누릅니다.
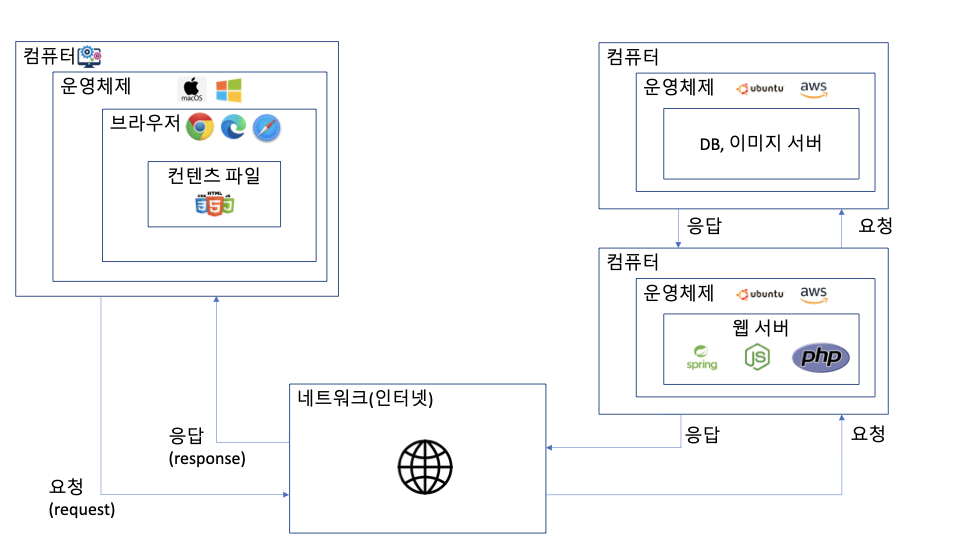
1-1. 브라우저는 컨텐츠 파일에 저장된 값을 보고, "검색 버튼"에 저장된 기능을 확인합니다.
1-2. 브라우저는 "검색버튼"에 저장된 기능과 값에 따라, 네이버 서버에 "요청" 을 보냅니다. -
운영체제는 브라우저의 동작에 반응하여 요청을 다른 컴퓨터(네트워크)에 보내달라고 하드웨어(컴퓨터)에 신호를 보냅니다.
-
하드웨어는 연결된 네트워크(인터넷)에 요청 신호 를 보냅니다. 이 요청에는 어디(어떤 서버 주소) 에 어떤 요청(내용)을 보낼지가 포함되어 있습니다.
-
네트워크는 요청에 담긴 주소를 확인해서 서버(컴퓨터)에 전달합니다.
-
서버는 요청을 확인해서, 개발자가 짜둔 프로그램에 따라서 응답을 네트워크로 전달합니다.
5-1. 이 과정에서 프로그램 내부에 갖고 있지 않은 데이터가 필요하면, DB나 이미지가 저장된 서버와 요청/응답을 주고받아 필요한 데이터를 불러옵니다. -
네트워크는 받은 응답을, 사용자의 컴퓨터에 보냅니다.
2. 웹개발자가 하는 것
-
브라우저의 '컴텐츠 파일'(HTML/CSS/JS)을 만듭니다.
-
'컨텐츠 파일'에 각종 기능(검색, 이메일 읽기/쓰기, 블로그 읽기/쓰기, 회원가입/로그인)을 제공할 수 있습니다.
-
서버내에 저장된 프로그램(Node JS, PHP, Spring)을 만듭니다.
-
또 다른 서버(DB, 이미지 저장소)를 만들고 주소와 데이터를 관리합니다.
-
요청을 받을 때, 이에 대한 접근권한이 있는지 확인하는 등의 보안조치를 취합니다.
3. 사용자가 하는 것
-
(일반적인)사용자는 브라우저만 조작할 수 있습니다.
-
이는 자신이 가진 HTML/CSS/JS파일을 변경하지 못하고, 자신의 IP주소/쿠키 등을 변경하지 못한다는 뜻입니다.
그럼 이제부터, 사용자가 브라우저에서 읽기용 파일을 어떻게 볼 수 있고, 읽기용 파일은 어떻게 동작하는지에 대해 알아보겠습니다.
