

Transformer architecture를 사용하여 대규모 언어 모델을 구축하면 이전 세대의 RNN에 비해 자연어 작업의 성능이 크게 향상되었고 생성형 기능이 폭발적으로 증가했습니다
Transformer architecture는 문장에 있는 모든 단어의 관련성과 문맥을 학습할 수 있는 능력을 갖고 있습니다.
가까이 있는 단어 옆에 있는 각 단어뿐만 아니라 문장의 다른 모든 단어에도 적용됩니다.
이러한 관계에 주의력 가중치를 적용하여 모델이 입력값의 어느 위치에 있든 상관없이 각 단어와의 관련성을 학습할 수 있도록 하는 것입니다.
이를 통해 알고리즘은 문장에서 누가 책을 가지고 있는지? 혹은 누가 책을 소유하고 있는지, 심지어 문서의 더 넓은 맥락과 관련이 있는지 또한 알아 낼 수 있습니다.
Self-Attention
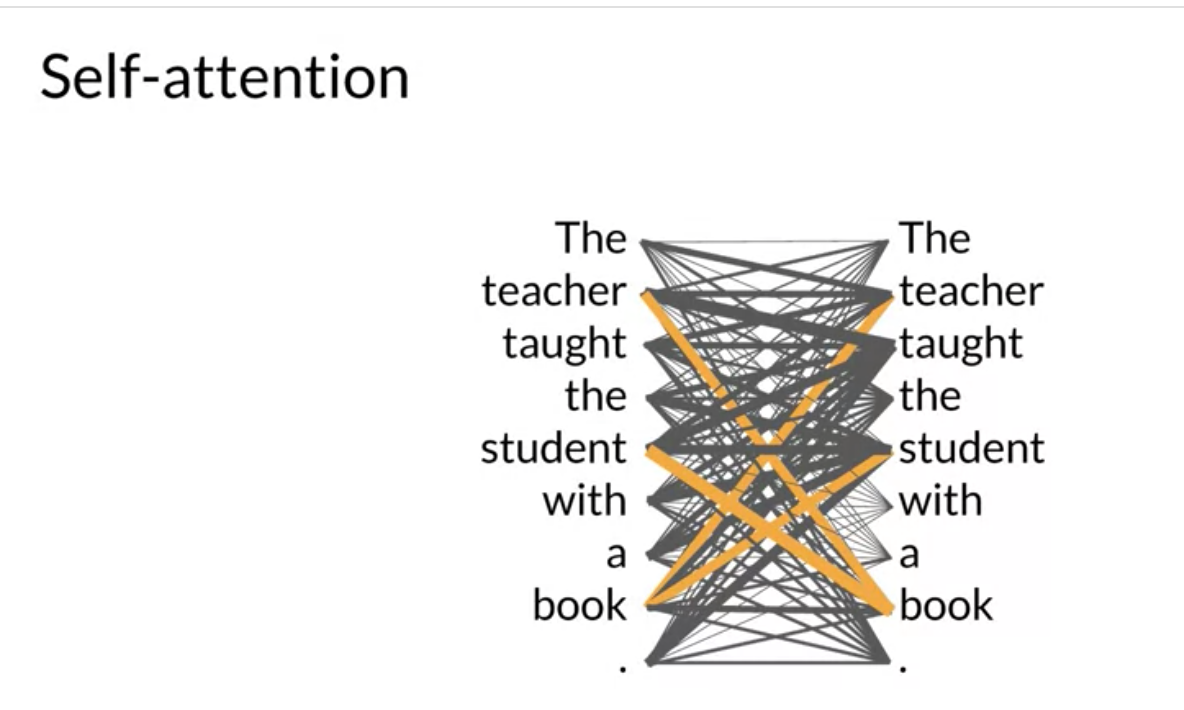
위 다이어그램을 Attention-map 이라고 하며, 각 단어와 다른 모든 단어 사이의 주의 가중치를 설명하는 데 유용할 수 있습니다.
위 다이어그램을 보면 책이라는 단어가 교사라는 단어 및 학생이라는 단어와 밀접하게 연관되어 있음을 알 수 있고, 이를 self-attention 이라고 합니다.
How To Work Transfomers?
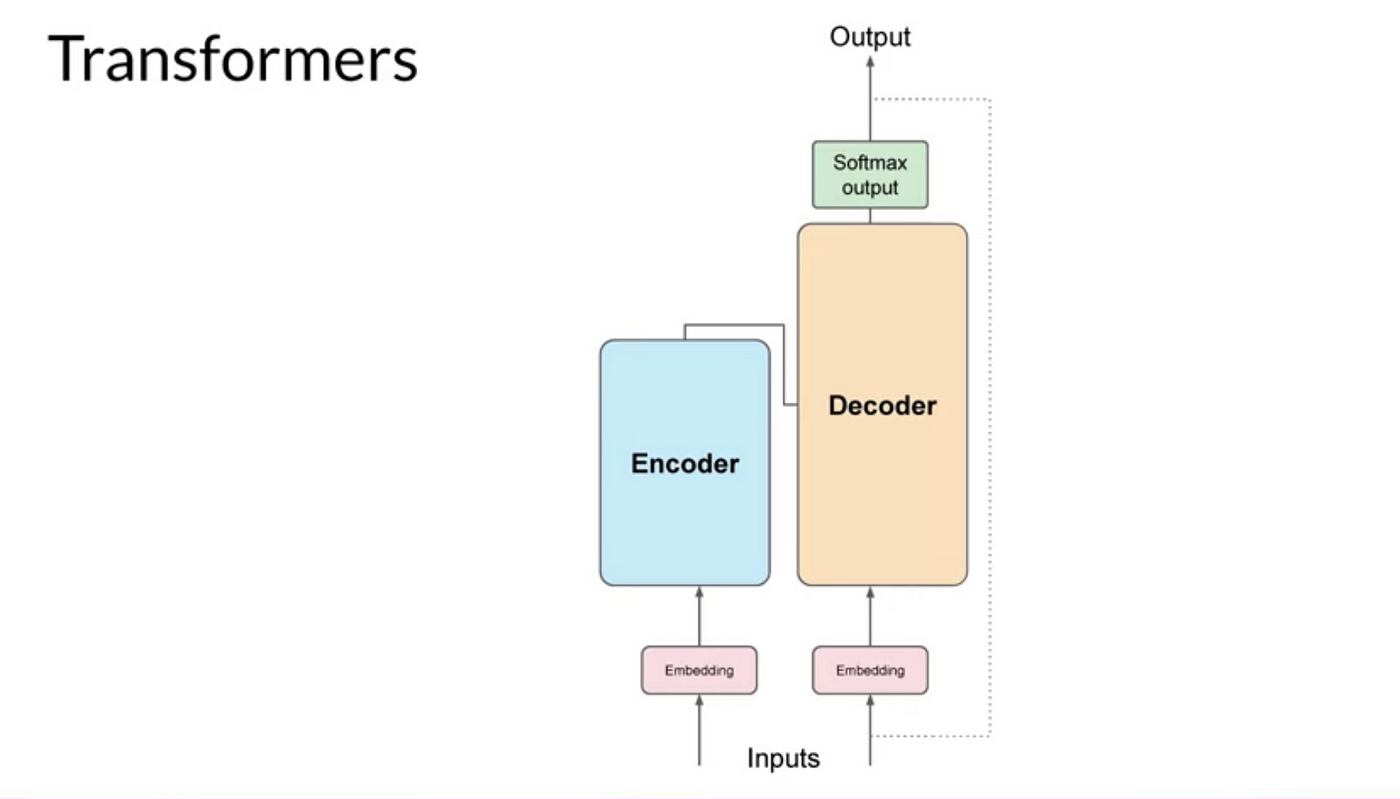
Transformer architecture는 Encoder와 Decoder 두 부분으로 구분됩니다.
이러한 구성 요소는 서로 연동되어 작동하며 여러 가지 유사점을 공유합니다.
tokenization
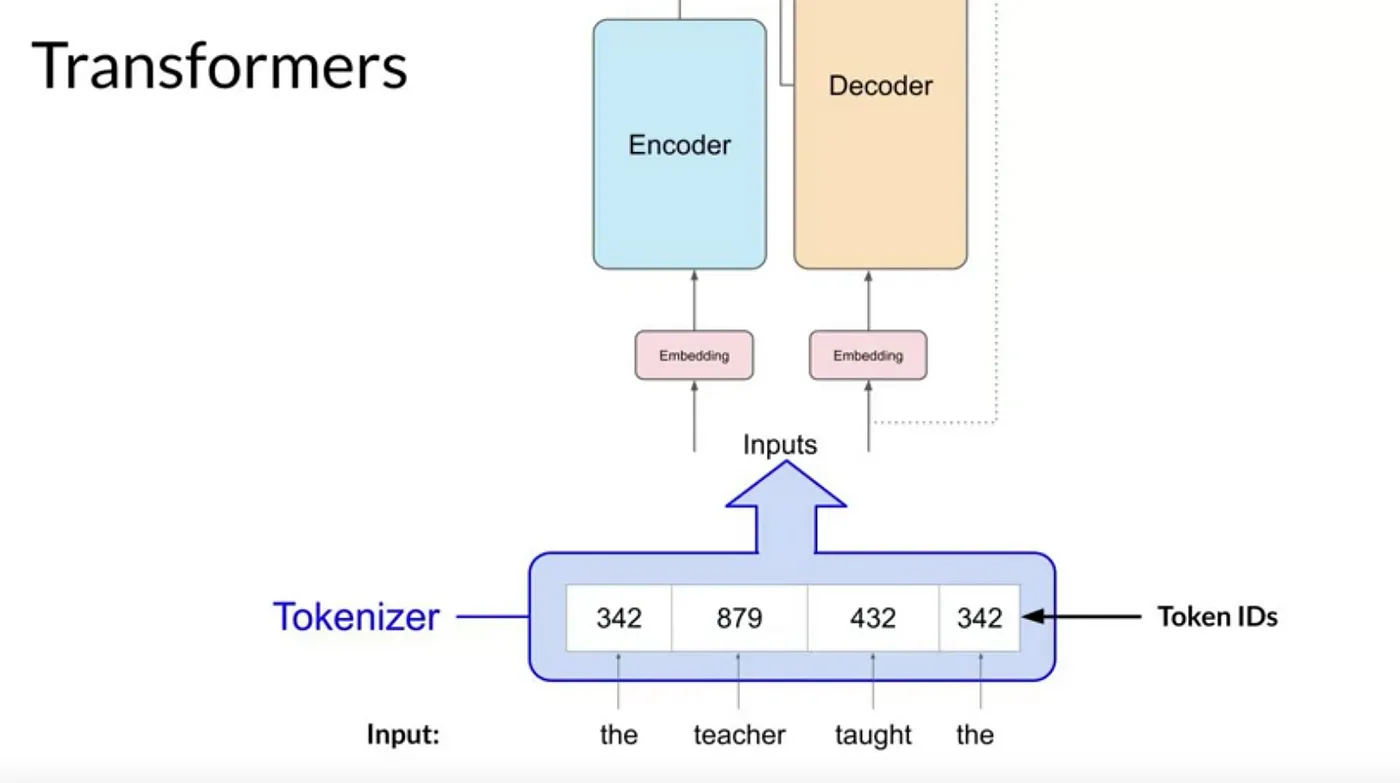
Machine-learning models은 단어가 아닌 숫자를 다루는 큰 통계 계산기일 뿐입니다.따라서 텍스트를 제공하기 전에 단어를 숫자로 바꿔야 합니다.
이를 tokenization(토큰화)라고 합니다.
이는 모델이 알고 있는 단어로 구성된 큰 사전에서, 이해하는 특별한 숫자를 각 단어에 부여하는 것과 같습니다.
Embedding Layer
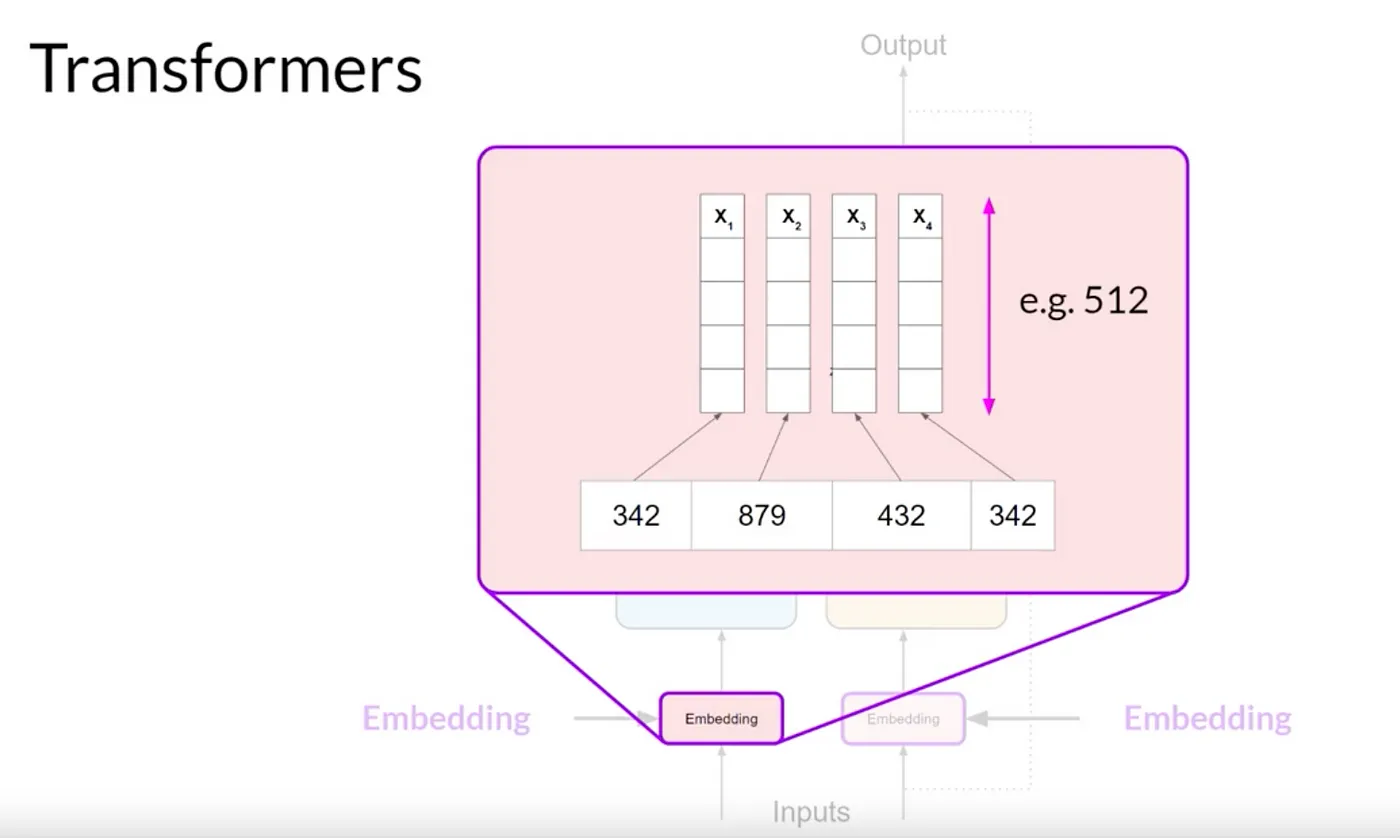
tokenization(토큰화) 된 텍스트는 이제 각 토큰이 벡터로 표현되어 고차원 공간으로 전달됩니다.
각 토큰 ID는 다차원 벡터에 매칭되며, 이 벡터들은 입력 시퀀스 내 개별 토큰의 의미와 문맥을 인코딩하는 데 학습됩니다.
Positional Encoding
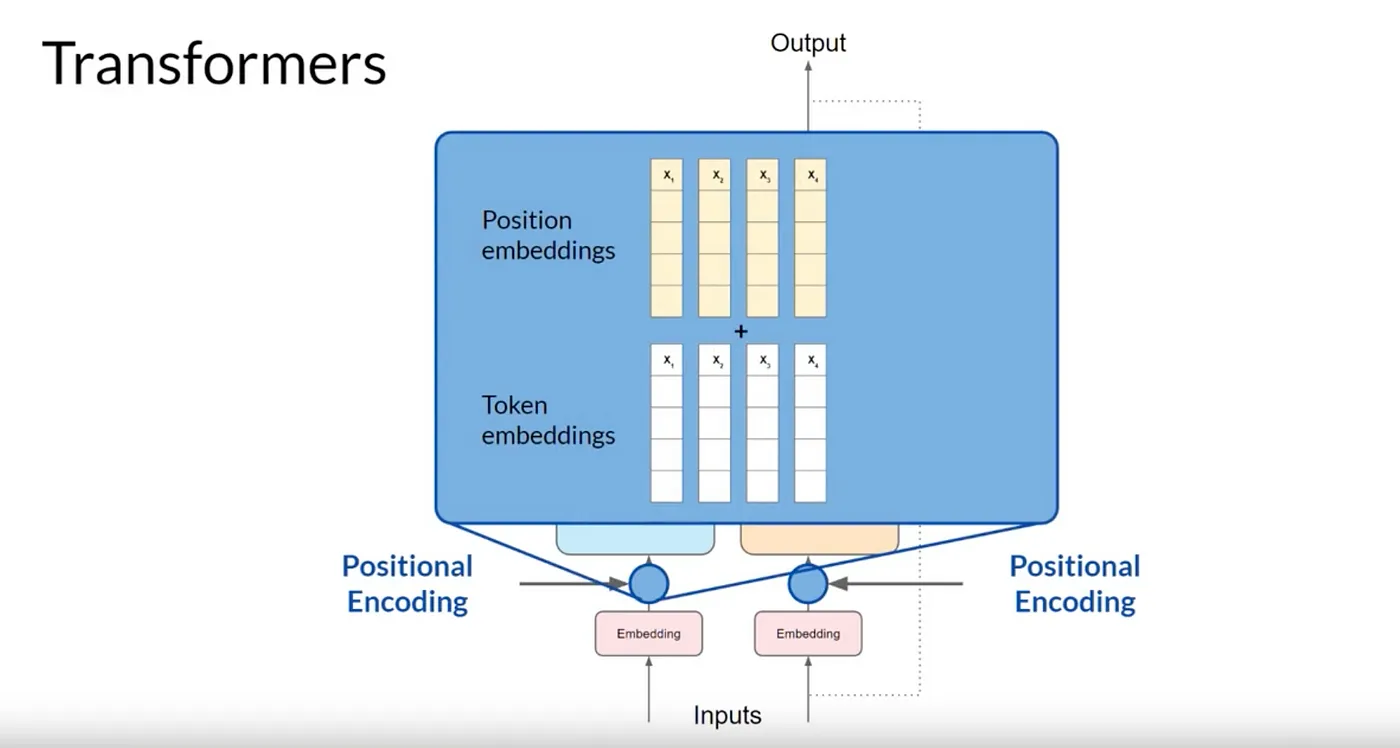
단어 순서 관련성을 유지하기 위해 Positional Encoding 이 인코더와 디코더 모두의 토큰 벡터에 추가됩니다.
이는 문장의 단어 위치에 대한 정보를 보존하여 입력 토큰의 효율적인 병렬 처리를 보장 해줄 수 있습니다.
그렇기 때문에, 단어 위치의 관련성을 잃지 않습니다.
Self-Attention Layer
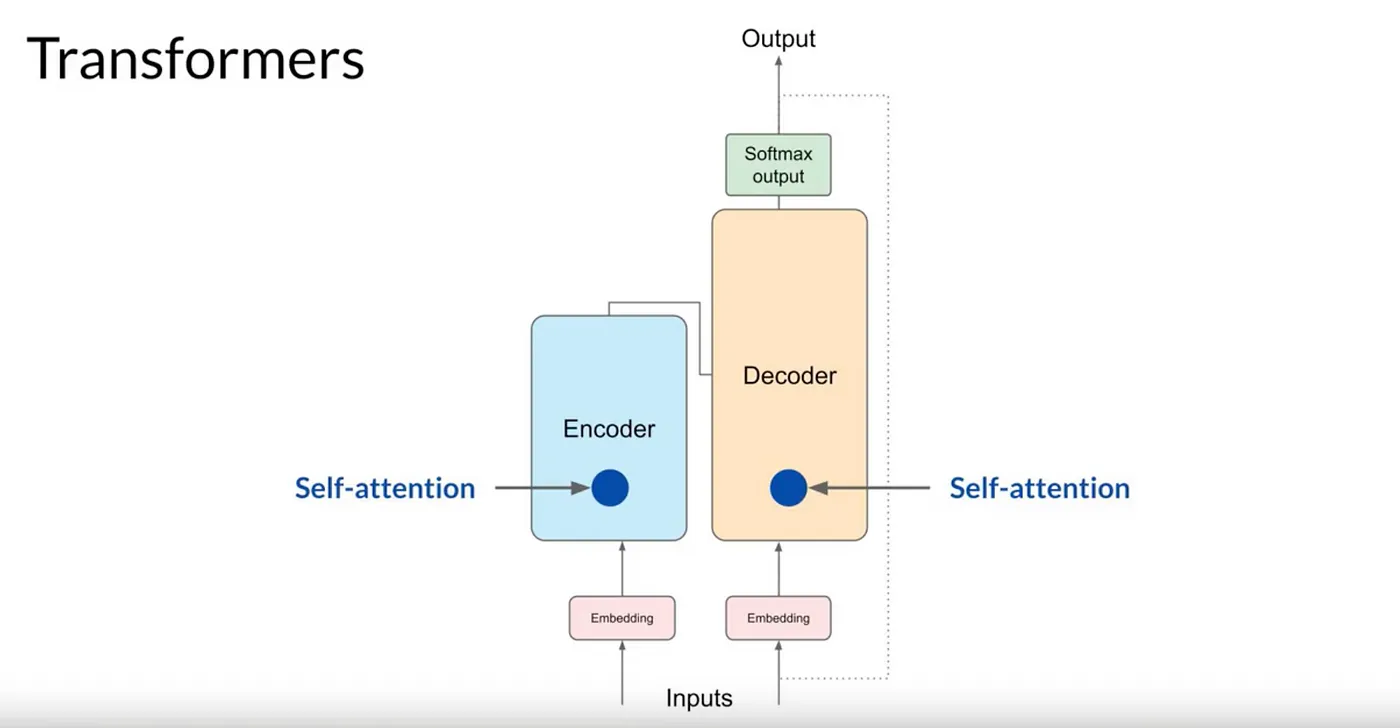
입력 토큰과Positional Encoding을 합산 한 후에는 Self-Attention Layer로 전달됩니다. 여기서 모델은 입력 시퀀스의 토큰 간의 관계를 분석합니다.
Self-Attention을 사용하면 모델이 입력 시퀀스의 여러 부분에 Attention(주의)를 기울여, 단어 간의 문맥과 맥락을 더 잘 파악할 수 있고, 각 단어가 시퀀스의 다른 모든 단어에 미치는 중요성을 반영합니다.
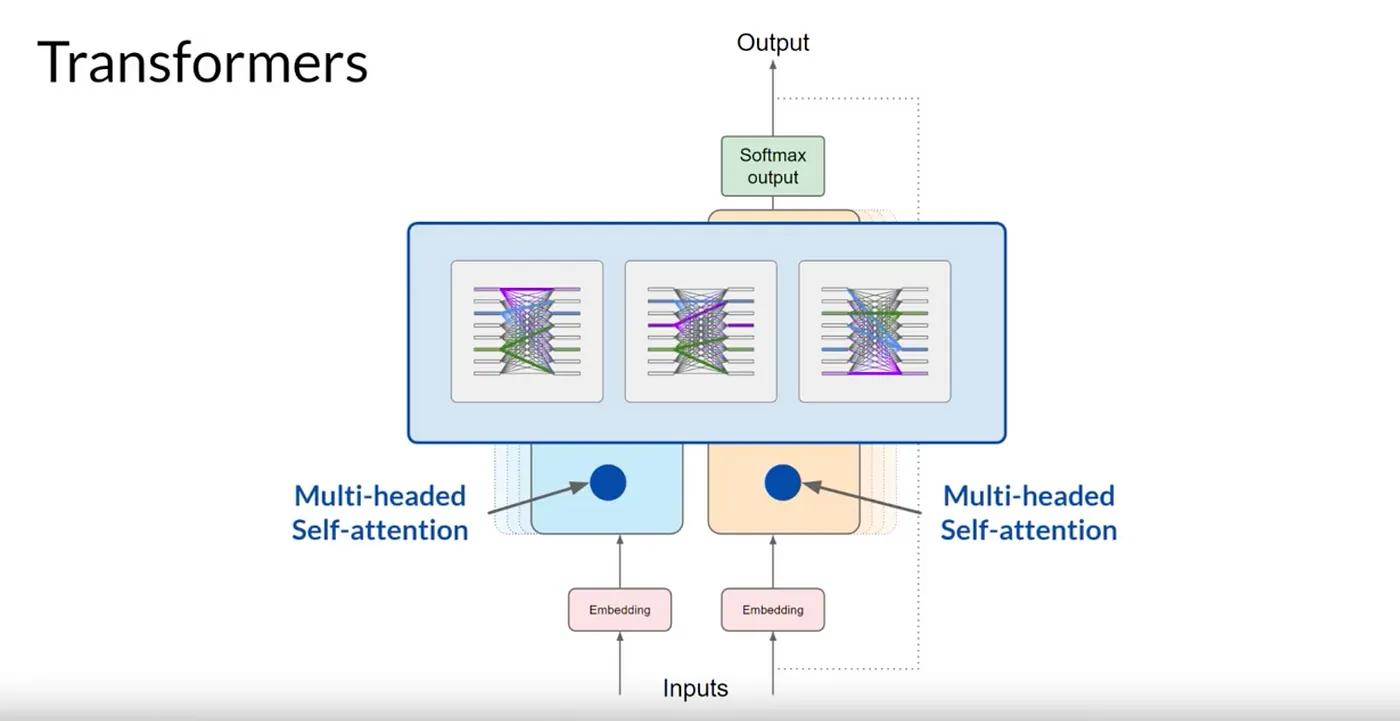
레이어에 포함되는 Headed의 수는 모델마다 다르지만, 12~100개 범위의 숫자가 일반 적입니다.
Transformer architecture 에서는 Multi-Headed-Attention 이라고 하는 여러 Self-Attention 가중치 세트가 독립적으로 병렬로 학습됩니다.
예를 들어, Headed-1은 문장의 활동에 집중 할 수도 있고, 또 다른 Headed는 다른 속성에 초점을 맞출 수도 있습니다.
Feed Forward Network
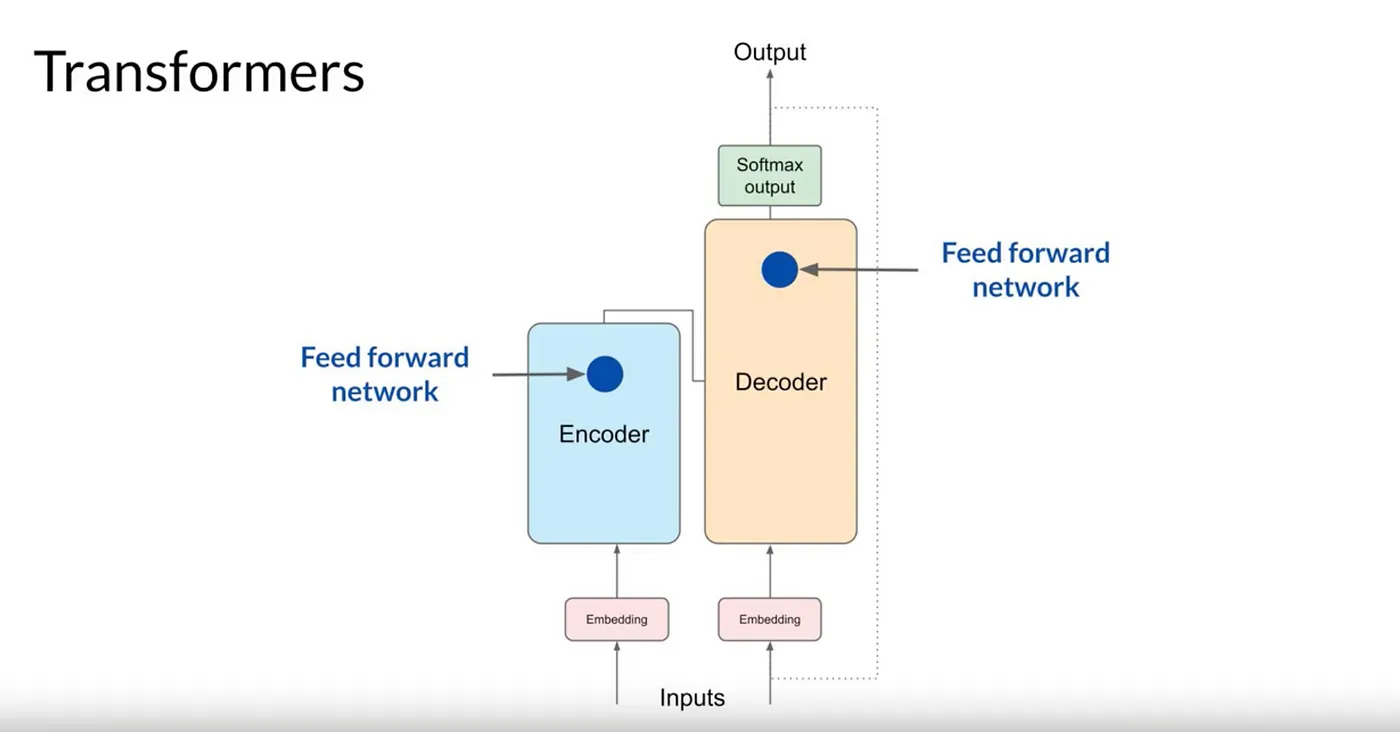
이 레이어는 토크나이저 사전의 모든 토큰에 대한 확률(P) 점수를 나타내는 로짓을 생성합니다.
Softmax Layer
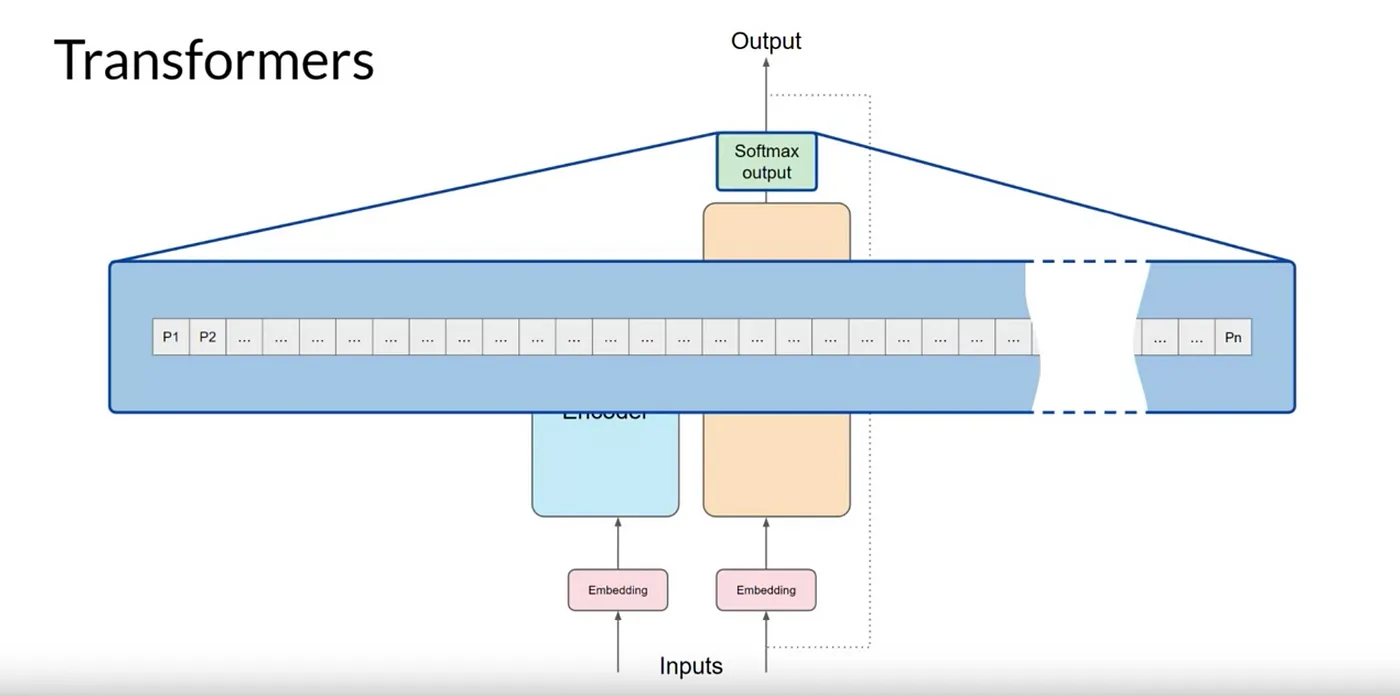
Feed Forward Network를 거친 후 최종적으로 Softmax Layer로 전달하면 각 단어의 확률을 계산합니다.
결과적으로 수천 개의 점수가 생성되며, 하나의 토큰이 가장 높은 점수를 가지며 가장 가능성이 높은 예측을 나타냅니다.
Transformer architecture가 어떤 Flow인지 간단하게 작성해봤습니다.
정확하지 않은 부분들이 분명히 있을 것이기 때문에 Attention Is All You Need 논문 링크를 첨부합니다.
