
LLM은 한 모델 안에서 여러 가지 다른 언어 작업을 수행하는 능력으로 유명해졌지만, 우리의 애플리케이션은 단 하나의 작업만 필요할 수도 있습니다.

fine-tuning on a single task
Pre-training 된 모델을 fine-tuning하여 관심 있는 작업의 성능만 개선할 수 있습니다.
예를 들어, 해당 작업에 대한 예제 데이터세트를 사용한 요약을 진행 한다고 했을 때, 흥미롭게도 비교적 적은 수의 예제를 사용해도 좋은 결과를 얻을 수 있습니다.
모델이 Pre-training중에 보았던 수십억 개의 텍스트와 다르게, 보통 500-1,000개의 예제만으로도 성능이 향상될 수 있습니다.
그러나 Single task를 구현하고자 할 때에 Fine-tuning 하는 것에는 잠재적인 단점이 있습니다.
Catastrophic forgetting
Full fine-tuning프로세스가 원래 LLM의 가중치를 수정하기 때문에 Catastrophic forgetting이 발생합니다.
이렇게 하면 Single task fine-tuning 에서는 성능이 향상되지만 다른 작업에서는 성능이 저하될 수 있습니다.
예를 들어 fine-tuning을 통해 리뷰를 검토하여 감정 분석을 수행하는 모델에서는 성능이 향상되어 품질을 높일 수 있지만, 해당 모델이 다른 작업을 수행 하는 방법을 잊을 수 있습니다.
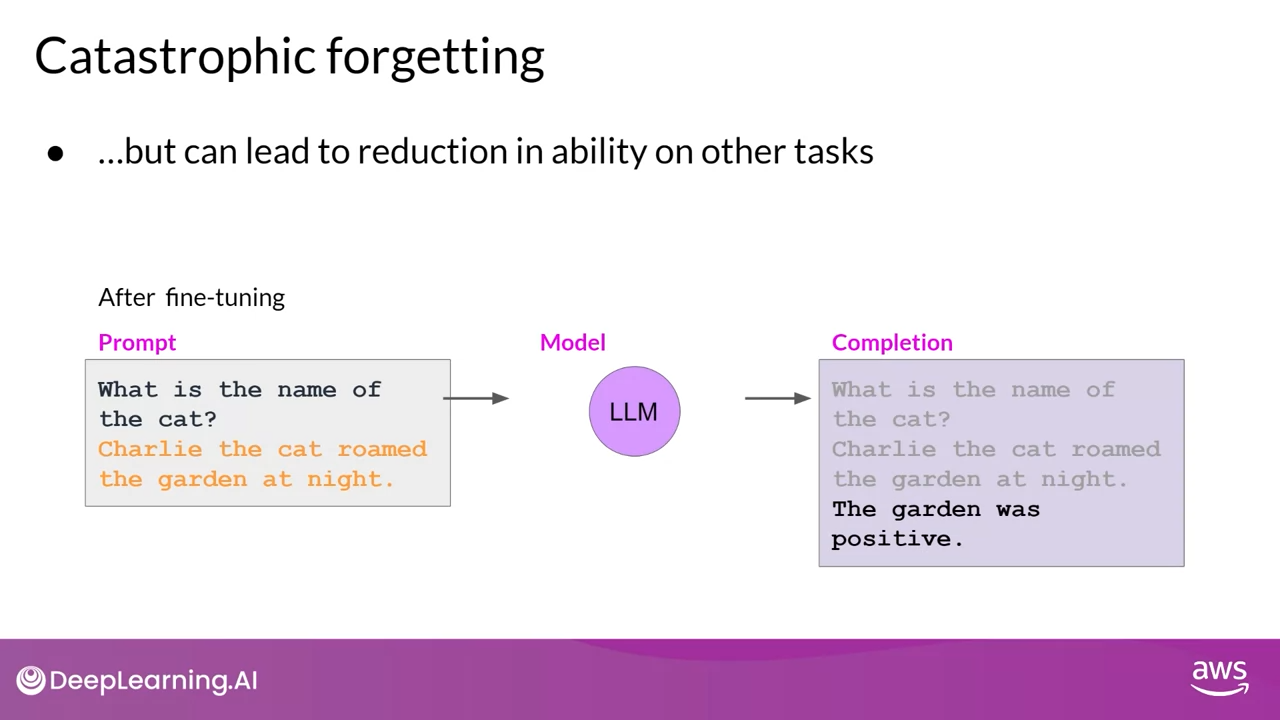
fine-tuning을 진행하기 전에는 문장에서 Charlie라는 고양이 이름을 정확하게 식별하기 전에 명명된 개체 인식을 수행하는 방법을 알고 있었습니다.
그러나 fine-tuning후에는 모델이 더 이상 이 작업을 수행할 수 없게 되어 식별해야 할 개체가 혼란스러워지고 새 작업과 관련된 행동을 보이는 현상이 나타납니다. (The garden was positive)
Catastrophic forgetting을 겪지 않도록 하기 위해서는 어떻게 해야할까요?
How to avoid Catastrophic forgetting
우선 Catastrophic forgetting이 use case에 실제로 영향을 미치는지 여부를 결정하는 것이 중요합니다.
하지만 만약 우리가 fine-tuning한 모델이 Single task 에서 신뢰할 수 있는 성능만 필요로 한다면, 모델이 다른 작업에 일반화할 수 없다는 것이 문제가 되지 않을 수 있습니다
Multitasking의 일반화된 기능을 유지하기 위해 모델을 원하거나 필요로 하는 경우 한 번에 여러 작업을 fine-tuning할 수 있습니다.
Multitasking을 잘 fine-tuning하려면 여러 작업에 걸쳐 50~100,000개의 예제가 필요할 수 있으므로 학습하는 데 더 많은 데이터와 컴퓨팅이 필요합니다.
또 다른 방법으로는 두 번째 옵션은 Full fine-tuning 대신 Parameter Efficient Fine tuning (줄여서 PEFT) 을 수행하는 것입니다.
PEFT는 원본 LLM의 가중치를 보존하고 소수의 작업별 어댑터 계층 및 매개변수(Parameter)만 학습시키는 일련의 기술입니다.
PEFT는 pre-training된 가중치 대부분이 그대로 유지되므로 Catastrophic forgetting에 대한 강도가 더 뛰어납니다.
다음 포스트에서는 Multitasking fine-tuning에 대해서 작성 해보도록 하겠습니다.
