
Transformers 모델의 아키텍처 차이는 주로 모델들이 학습하는 방식의 차이 때문이 있습니다.
LLM Pre-training at a high level
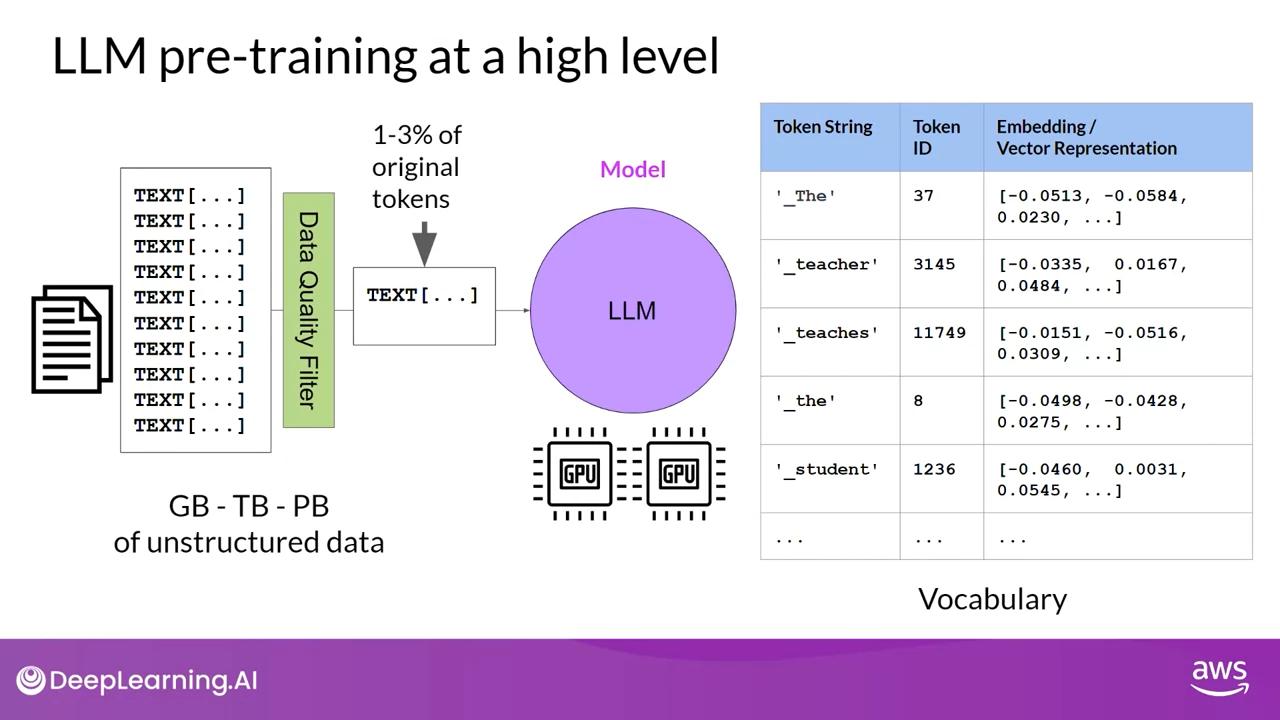
LLM은 언어를 깊게 이해하고 활용하기 위해 통계적으로 다양한 정보를 인코딩합니다.
이러한 이해력은 모델이 방대한 양의 비정형 텍스트 데이터를 학습하는 과정에서 형성됩니다.
이 데이터는 기가바이트, 테라바이트 심지어 페타바이트에 이를 정도로 막대한 양일 수 있으며, 인터넷에서 스크랩한 자료와 언어 모델 학습을 위해 특별히 수집한 텍스트 모음을 포함하여 다양한 출처에서 가져온 것입니다.
self-supervised learning단계에서 모델은 언어에 존재하는 패턴과 구조를 내면화 합니다.
Pre-training 중에 모델 가중치가 업데이트되어 훈련 목표 손실을 최소화 할 수 있고 Encoder는 각 토큰에 대한 임베딩 또는 벡터를 생성합니다. 또한 Pre-training을 위해서는 많은 양의 컴퓨팅과 GPU 사용이 필요합니다.
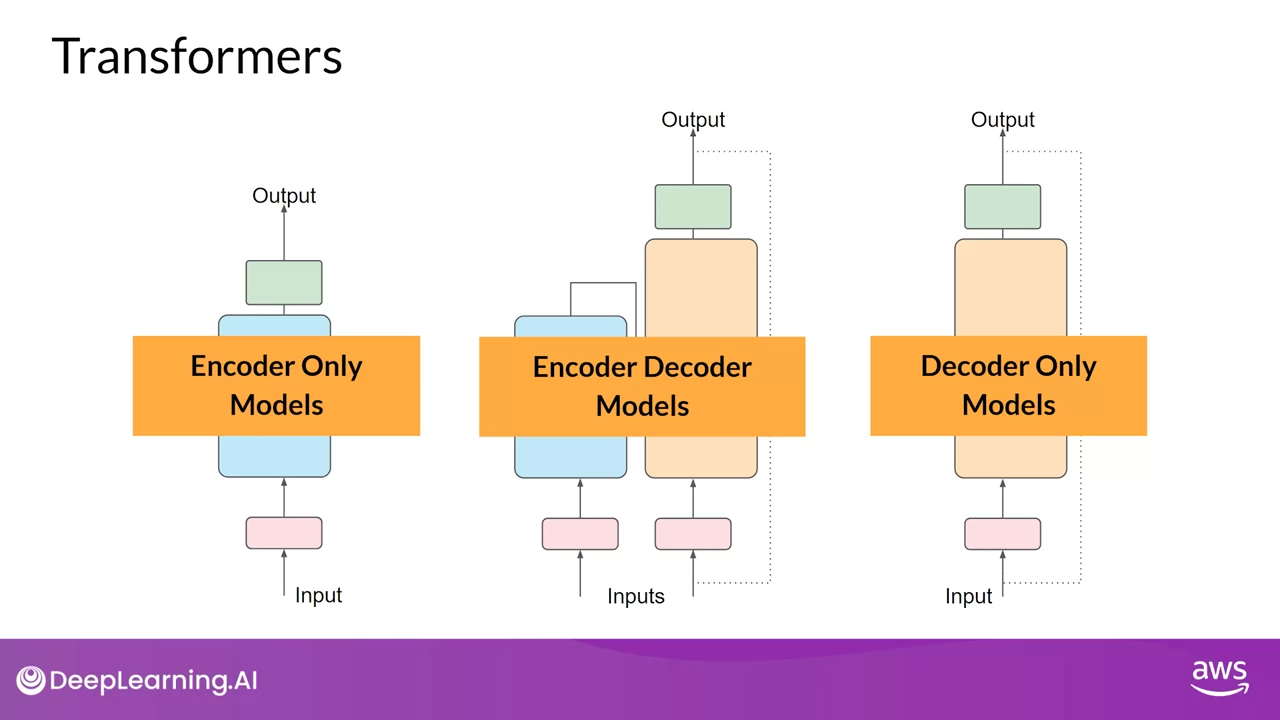
트랜스포머 모델에는 Encoder Only Models, Encoder-Decoder Models, Decoder Only Models의 세 가지 변형이 있는 것을 확인할 수 있습니다.
모델들은 각각 서로 다른 목표를 바탕으로 학습됐음으로 다양한 작업을 수행하는 방법을 학습합니다.
AutoEncoding Models (Encoder Only Models)

Encoder Only Models는 AutoEncoding Models 이라고도 하며 마스킹된 언어 모델링을 사용하여 Pre-training 합니다.
입력 시퀀스의 일부 토큰이나 무작위로 마스크를 하게 됩니다. 이 마스크된 토큰을 예측하여 원래 문장을 재구성하는 것이 훈련의 목표이며, 이를 노이즈 제거 목표라고도 합니다.
이런 방식으로 모델은 입력 시퀀스의 양방향 표현을 학습하게 됩니다.
즉, 모델은 단어뿐만 아니라 토큰의 전체적인 문맥을 이해할 수 있게 됩니다. 이렇게 학습된 Encoder Only Models은 양방향 컨텍스트를 활용하는 작업에 이상적입니다.

이런 Encoder Only Models는 감정 분석, 명명된 개체 인식, 단어 분류와 같은 토큰 수준의 작업뿐만 아니라 문장 분류 작업도 수행할 수 있습니다.
대표적인 예로는 BERT와 Roberta가 있습니다.
Autoregressive Models (Decoder Only Models)

Causal languge model의 경우 autoregressive model의 또 다른 말로 문장에서 단방향 모델을 통해 다음 단어를 예측, 추측하는 언어모델을 말합니다.
이전 토큰 시퀀스를 기반으로 다음 토큰을 예측하는 것이 training 목표하며, 이를 전체 언어 모델링이라고도 합니다. Decoder 기반의 모델은 입력 시퀀스를 마스킹하여 해당 토큰 이후의 입력 토큰만 볼 수 있습니다. 다시 말해, 이 모델은 문장의 끝을 알지 못합니다.(단방향) 모델은 입력 시퀀스를 반복하여 다음 토큰을 예측합니다. 이러한 방식으로 모델은 다음 토큰을 예측하는 데 필요한 통계적 표현을 학습합니다.

Decoder Only Models은 텍스트 생성에 주로 사용되지만, 규모가 큰 Decoder Only Models은 강력한 Zero Shot 추론 기능을 보여 다양한 작업을 잘 수행할 수 있는 경우가 많습니다.
Decoder 기반 Autoregressive Models의 잘 알려진 예로는 GPT와 BLOOM이 있습니다.
Sequence-to-Sequence Models (Encoder-Decoder)
Encdoer-Decoder 컴포넌트를 모두 사용하는 Seq2Seq 모델입니다. Pre-training 목표의 정확한 세부 사항은 모델마다 다르지만, 널리 사용되는Seq2Seq 모델 T5 토큰의 임의 시퀀스를 마스킹하는 스팬 손상을 사용하여 Encodr를 pre-training합니다. 그런다음 마스킹 한 부분을 고유한 Sentinel 토큰 (여기서 x로 표시) 으로 대체합니다.
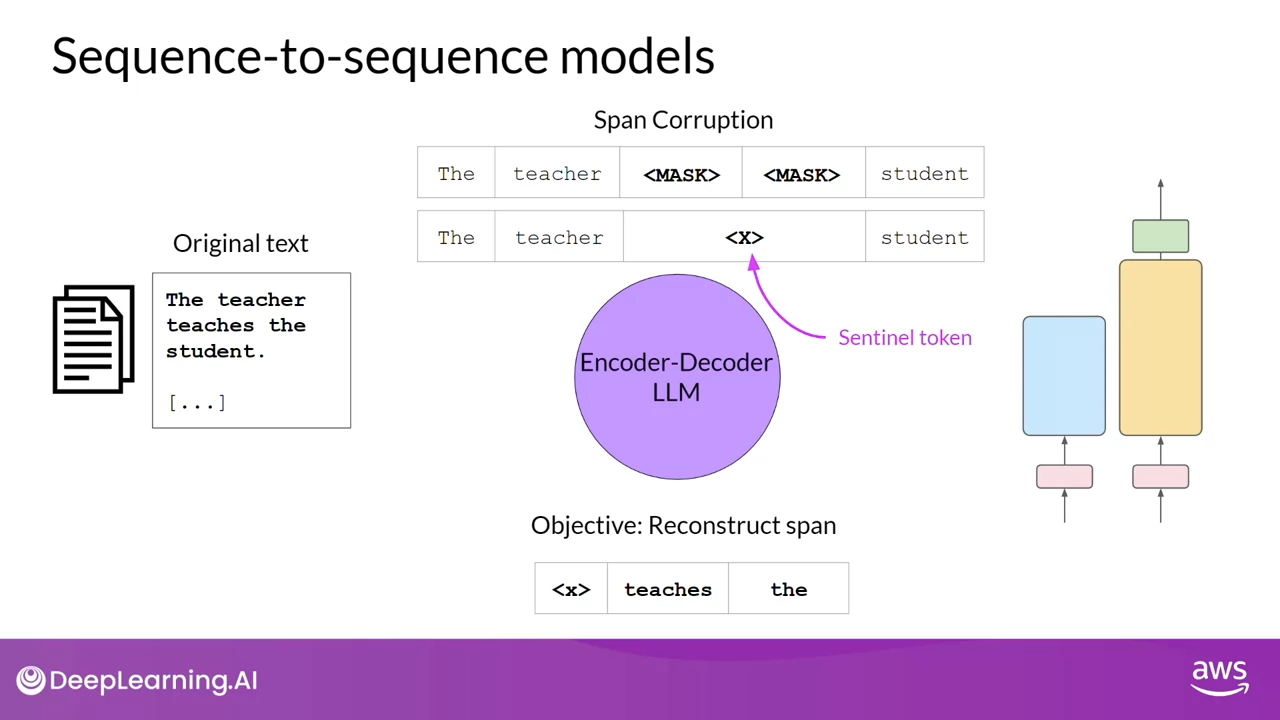
Decoder는 마스킹된 토큰 시퀀스를 다시 원래 문장으로 복원하는 작업을 수행합니다. 이 과정에서Sentinel 토큰과 예측된 토큰이 순차적으로 출력 됩니다.

이런 방식으로 훈련된 모델은 번역, 요약, 질문 응답 등 다양한 자연어 처리 작업에 활용될 수 있으며, 일반적으로 텍스트 본문이 입력과 출력으로 모두 사용되는 경우에 유용합니다.
T5 외에도 잘 알려진 또 다른 Encoder-Decoder 모델은 BART입니다.
