OpenAPI 란?
데이터를 가져다 쓸 수 있게 서버의 ‘창구’를 열어둔 것!
⇒ Dart Open API를 활용하면 공시 정보를 ‘데이터 분석’에 활용할 수 있어요.
⇒ 이제 일일이 공시자료를 보러가지 않아도, 분석을 할 수 있답니다!
⇒ 게다가, 이 모든 것을 쉽게 활용할 수 있게 만든 ‘라이브러리’까지. 🙂
API란?
서버에 접근하는 ‘창구’와 같은 것
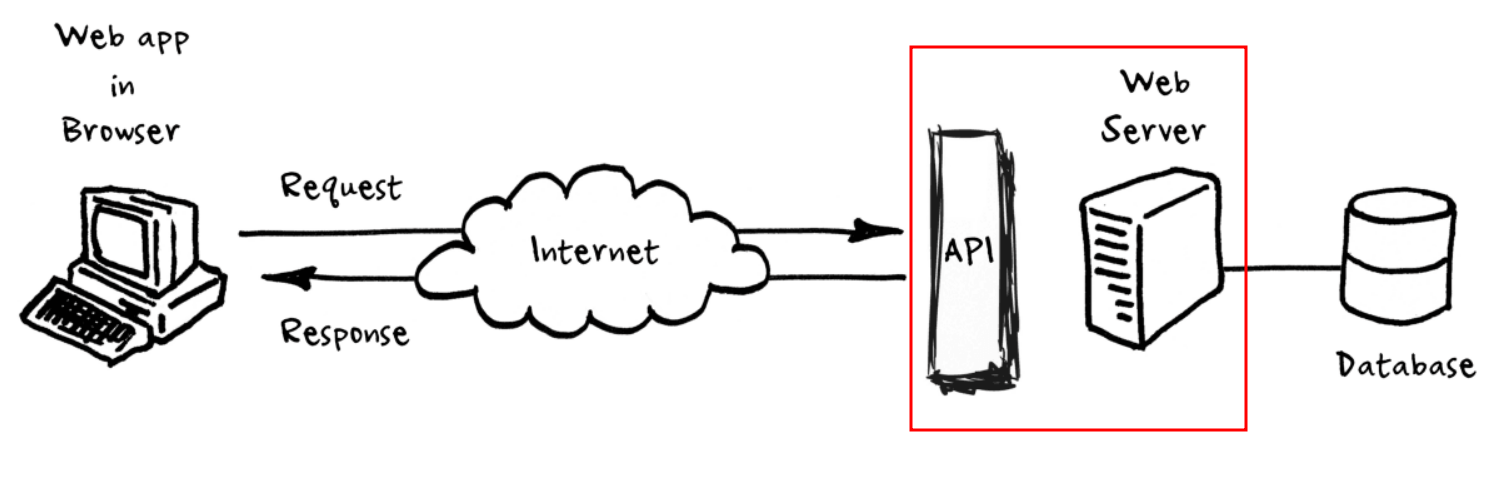
키는 왜 발급 받아야 할까?
: 은행에도 여러가지 데이터가 있지만, 우리는 ‘창구’를 활용해서 정해진 약속으로 정해진 데이터만 접근 할 수 있어요. 예) 입출금창구에 가서 주민등록증을 보여줘야 → 잔고를 확인할 수 있죠
⇒ 누구에게나 열어둔 ‘창구’이기 때문에, 너무 많은 요청이 오면 서버가 매우 힘들겠죠!
⇒ 그래서 인 당 할당량을 정해서 ‘key’를 발급하는 것이랍니다. 요청할 때 이 것이 늘 필요하죠.
Dart OpenAPI 키 발급
:⇒ 인증키 신청을 누르고 정보를 입력하면, 누구나 쉽게 키를 발급 받을 수 있습니다.
⇒ API 사용 환경은 ‘웹, 앱 모두’로 해주시고, 사용용도는 ‘개인 공부’라고 적어주세요
https://opendart.fss.or.kr/uat/uia/egovLoginUsr.do
<Dart 라이브러리 활용>
Dart-fss 라이브러리는?
Dart의 OpenAPI를 쉽게 사용할 수 있도록 만들어둔 코드입니다.
⇒ 라이브러리를 활용하면 복잡한 개발 가이드(링크) 없이 데이터들을 얻을 수 있답니다.
- dart-fss 깔고 전체 기업목록 불러오는 코드 (아래)
import dart_fss as dart_fss
import pandas as pd
api_key = '여기에 API 키를 입력'
dart_fss.set_api_key(api_key=api_key)
corp_list = dart_fss.get_corp_list()
corp_list.corps<종목 정리하기>
전체 종목을 보는 코드
all = dart_fss.api.filings.get_corp_code()
all[0]df = pd.DataFrame(all) 살펴보기
: stock_code 가 있는 종목은 상장사, 없는 종목은 비상장사를 의미
df_listed = df[df['stock_code'].notnull()].notnull(): none이 아니다!
df_non_listed = df[df['stock_code'].isnull()].isnull(): none이다!
엑셀로 저장해두기
⇒
.to_excel('파일명.xlsx')만 붙이면 엑셀로 만들어준답니다. 판다스의 힘!
df_listed.to_excel('상장종목.xlsx')
df_non_listed.to_excel('비상장종목.xlsx')<dart API 사용해보기>
1) 한 개 종목을 정해서 코드를 찾기
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
corp_code
2) dart api 를 사용해보기
<사업보고서>
나온 정보중에 모르는것이 있다면?
dart open api사이트 - 개발가이드 - 공시정보 - 기업개황 바로가기
- 기업 정보
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
dart_fss.api.filings.get_corp_info(corp_code)- 미등기임원 보수 총액
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.unrst_exctv_mendng_sttus(corp_code, '2021', '11011')
pd.DataFrame(data['list'])- 증자(감자)현황
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.irds_sttus(corp_code, '2021', '11011')
pd.DataFrame(data['list'])- 배당 현황
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')
pd.DataFrame(data['list'])5.최대주주 현황
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.hyslr_sttus(corp_code, '2021', '11011')
pd.DataFrame(data['list'])⇒ 최대주주 중 몇 명이 주식을 샀는지 / 팔았는지도 알 수 있겠군요!
pd.DataFrame(data['list'])[['nm','bsis_posesn_stock_qota_rt','trmend_posesn_stock_qota_rt']]
- 임원 사항
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.exctv_sttus(corp_code, '2021', '11011')
pd.DataFrame(data['list'])- 직원 현황
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.emp_sttus(corp_code, '2021', '11011')
pd.DataFrame(data['list'])- 이사 보수
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.hmv_audit_indvdl_by_sttus(corp_code, '2021', '11011')
pd.DataFrame(data['list'])- 연봉 top 5
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.indvdl_by_pay(corp_code, '2021', '11011')
pd.DataFrame(data['list'])- 타법인 출자 현황
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.otr_cpr_invstmnt_sttus(corp_code, '2021', '11011')
pd.DataFrame(data['list'])<상장기업 재무정보>
⇒ 재무제표의 3년 치 주요 정보
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')
pd.DataFrame(data['list'])⇒ 모든 항목
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt_all(corp_code, '2021', '11011', 'CFS')
pd.DataFrame(data['list'])
- 참고: CFS:연결재무제표, OFS:재무제표
<지분공시 종합정보:주주정보>
임원, 주요 주주 소유 보고
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.shareholder.elestock(corp_code)
pd.DataFrame(data['list'])특정 사람
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.shareholder.elestock(corp_code)
df_temp = pd.DataFrame(data['list'])
df_temp[df_temp['repror'] == '김범수']<상장종목 분석하기1:시총 Top 50 社 - 연봉왕 뽑아보기>
1) 한 종목에 대해 뽑아보기
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
print(corp_code)
def get_salary(name):
corp_code = df_listed[df_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.info.indvdl_by_pay(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df = df[['corp_name','nm','ofcps','mendng_totamt']]
df.columns = ['기업명','이름','역할','보수']
#보수 내림차순 보기위해 숫자로 만드는 작업
df['보수'] = pd.to_numeric(df['보수'].str.replace(',',''))
df = df.sort_values(by='보수',ascending=False)
return df#df.dtypes
해당부분 숫자인지(int64) 확인!
여러개 종목에 대해 뽑아보기
names = ['삼성전자','LG에너지솔루션','SK하이닉스','NAVER','삼성바이오로직스','삼성전자우','카카오','삼성SDI','현대차','LG화학','기아','POSCO홀딩스','KB금융','카카오뱅크','셀트리온','신한지주','삼성물산','현대모비스','SK이노베이션','LG전자','카카오페이','SK','한국전력','크래프톤','하나금융지주','LG생활건강','HMM','삼성생명','하이브','두산중공업','SK텔레콤','삼성전기','SK바이오사이언스','LG','S-Oil','고려아연','KT&G','우리금융지주','대한항공','삼성에스디에스','현대중공업','엔씨소프트','삼성화재','아모레퍼시픽','KT','포스코케미칼','넷마블','SK아이이테크놀로지','LG이노텍','기업은행']
dfs = []
for name in names:
try:
df = get_salary(name)
dfs.append(df)
except:
print(f'error - {name}')
#합치기 concat!
df_result = pd.concat(dfs)
df_result.sort_values(by='보수',ascending=False)
df_result.sort_values(by='보수',ascending=False).head(30)<상장종목 분석하기2:최대 주주의 주식 변동 모아보기>
def get_shareholders(corp_code):
data = dart_fss.api.info.hyslr_sttus(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df = df[['corp_name','nm','relate','bsis_posesn_stock_qota_rt','trmend_posesn_stock_qota_rt','rm']]
df.columns = ['회사명','이름','관계','기초지분율','기말지분율','비고']
df = df[df['관계'].notnull()]
df['기초지분율'] = pd.to_numeric(df['기초지분율'])
df['기말지분율'] = pd.to_numeric(df['기말지분율'])
return df.sort_values(by='기초지분율',ascending=False).head(3)* 상장 종목 중 10개만 추려내기
⇒ 하루에 쓸 수 있는 콜 수가 정해져 있답니다.
10개종목 추려서df_listed.sample(10) 증감 큰 순서대로 정렬하기
corp_codes = list(df_listed.sample(10)['corp_code'])
dfs = []
for corp_code in corp_codes:
try:
df = get_shareholders(corp_code)
dfs.append(df)
except:
print(f'error - {corp_code}')
df_result = pd.concat(dfs)
df_result['증감'] = df_result['기말지분율'] - df_result['기초지분율']
df_result.sort_values(by='증감',ascending=False)
<상장 종목 분석하기3: '돈 많이 번 회사’를 찾기; 이익잉여금 많아진 회사>
def get_profit(name):
corp_code = df_listed[df_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
cond = (df['fs_div'] == 'CFS') & (df['account_nm'] == '이익잉여금')
df = df[cond]
df['name'] = name
df = df[['name','thstrm_amount','frmtrm_amount']]
df.columns = ['기업명','당기','전기']
df['당기'] = pd.to_numeric(df['당기'].str.replace(',',''))
df['전기'] = pd.to_numeric(df['전기'].str.replace(',',''))
df['증감'] = df['당기'] - df['전기']
df['증감율'] = abs(df['증감'])/abs(df['전기'])
return df#절대값: abs
상장사 10개
names = list(df_listed.sample(10)['corp_name'])
dfs = []
for name in names:
try:
df = get_profit(name)
dfs.append(df)
except:
print(f'error - {name}')
df_result = pd.concat(dfs)
df_result.sort_values(by='증감율', ascending=False)
df_result<비상장 종목 분석하기: 배당항목으로 당기순이익 확인>
: 비상장 종목은 ‘사업보고서 주요정보’만 분석할 수 있어요**
def get_earning(name):
corp_code = df_non_listed[df_non_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df = df[df['se'] == '(연결)당기순이익(백만원)']
df = df[['corp_name','thstrm','frmtrm','lwfr']]
df.columns = ['기업명','2021','2020','2019']
df['2021'] = pd.to_numeric(df['2021'].str.replace(',',''))
df['2020'] = pd.to_numeric(df['2020'].str.replace(',',''))
df['2019'] = pd.to_numeric(df['2019'].str.replace(',',''))
return df과제
def get_salary(name):
corp_code = df_listed[df_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.info.emp_sttus(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df = df[['corp_name','sexdstn','jan_salary_am']]
df_result = pd.DataFrame()
doc = {
'기업명': name,
'연봉(남)':df[df['sexdstn'] == '남'].iloc[-1,-1],
'연봉(여)':df[df['sexdstn'] == '여'].iloc[-1,-1]
}
df_result = df_result.append(doc, ignore_index=True)
df_result['연봉(남)'] = pd.to_numeric(df_result['연봉(남)'].str.replace(',',''))
df_result['연봉(여)'] = pd.to_numeric(df_result['연봉(여)'].str.replace(',',''))
df_result['차이(남-여)'] = df_result['연봉(남)'] - df_result['연봉(여)']
df_result['평균'] = (df_result['연봉(남)']+df_result['연봉(여)'])/2
return df_result
#-----------------------------------
corp_codes = list(df_listed.sample(10)['corp_name'])
dfs = []
for corp_code in corp_codes:
try:
df = get_salary(corp_code)
dfs.append(df)
except:
print(f'error - {corp_code}')
df_result = pd.concat(dfs)
df_result.sort_values(by="차이(남-여)",ascending=True)