
CoreML 이란?
CoreML은 Apple이 개발한 기계 학습 프레임워크로, iOS, macOS, watchOS 및 tvOS와 같은 Apple의 운영 체제에서 기계 학습 모델을 통합하는 데 사용됩니다.
CoreML을 사용하면 기계 학습 모델을 앱에 통합하여 이미지 분류, 텍스트 분석, 음성 인식 등 다양한 기계 학습 작업을 수행할 수 있습니다.
즉, CoreML은 Apple의 생태계에서 머신 러닝을 쉽게 사용할 수 있도록 도와주는 프레임워크입니다.
- 장점
- 기기 자체에서 모델을 실행 함으로 네트워크에 연결할 필요 없이 앱의 반응을 보장하면서 사용자 데이터를 비공개로 유지할 수 있습니다.
- CreateML을 사용하여 맞춤형 CoreML 모델을 학습 시킬 수 있습니다.
CreateML이란?
CreateML은 Apple의 머신 러닝 모델 개발 및 학습 도구로, CoreML을 지원하는 도구 중 하나입니다.
CreateML은 주로 모델 개발 및 훈련을 단순화하여 개발자가 머신 러닝 모델을 작성하고 학습시키는 과정을 더 쉽게 만듭니다.
즉, CreateML은 모델 개발 및 학습을 단순화하는 도구입니다.
-
CreateML
-
모델 유형

그래서 어디에 사용할까?
머신 러닝을 사용해야 할 이유가 각자 있겠지만 저는 파이널 프로젝트로 소개팅 앱을 만드는 중인데 타 소개팅 앱에서는 회원가입을 하고 관리자가 승인을 해야 하는 번거로움이 있어서 그 부분을 자동화하고자 머신러닝을 사용하게 되었습니다.
머신러닝 작업 흐름
- 훈련 단계
목표 정의 -> 데이터 수집 -> 데이터 준비 -> 모델 개발 -> 모델 훈련 -> 모델 평가 -> 목표 정의
- 추론 단계
입력 -> 입력 중비 -> 훈련된 모델 -> 출력 해석
모델 폴더 구조
모델링을 하려면 데이터들이 필요하겠죠? 학습 시키려는 데이터들로 아래와 같은 폴더 구조로 모델 폴터를 만들어주세요.
최상위 폴더 - 학습 데이터 - 분류 카테고리 - 데이터
최상위 폴더 - 테스트 데이터 - 분류 카테고리 - 데이터
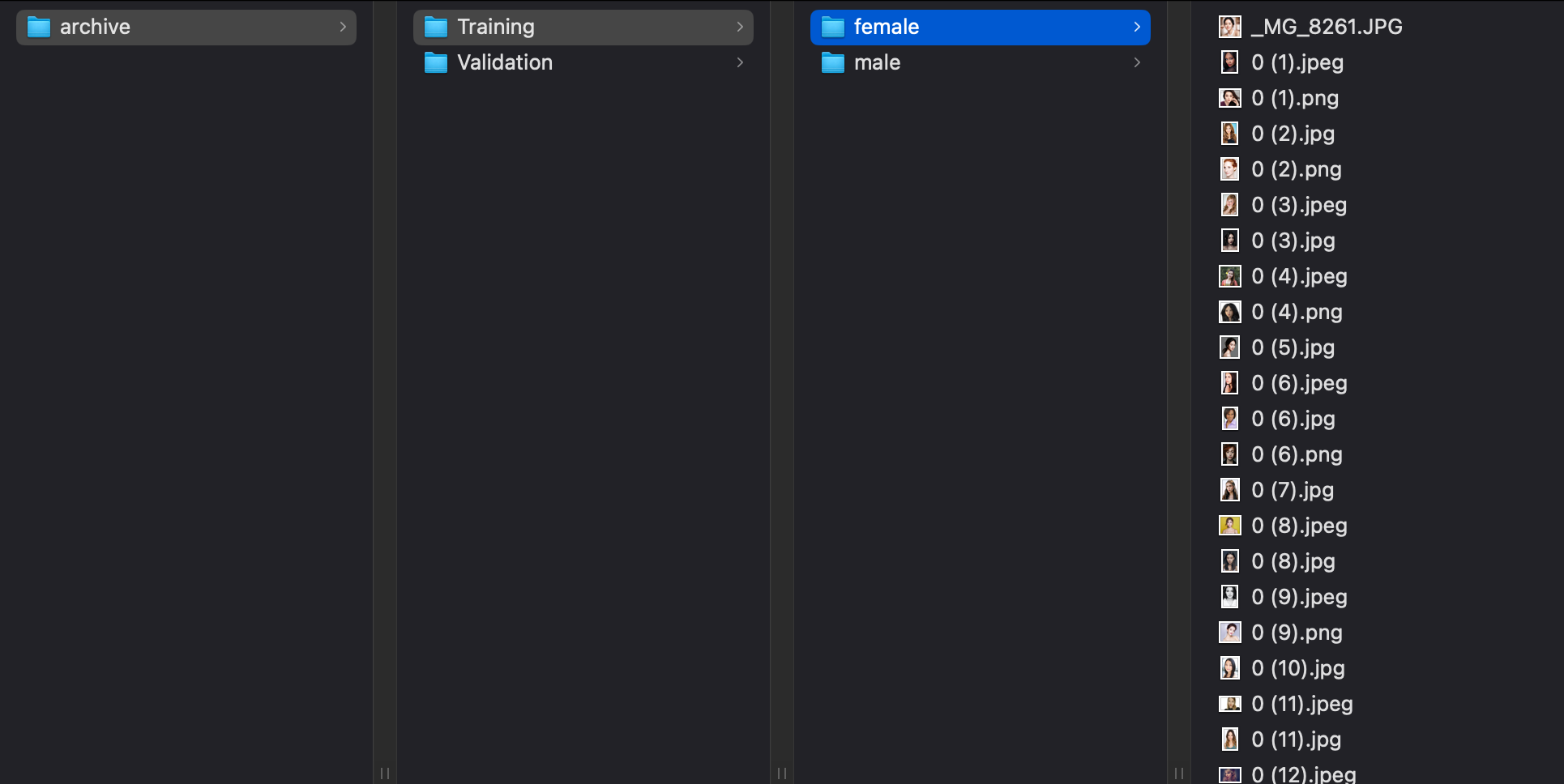

CreateML 시작하기
이제 직접 모델링을 해볼까요? 자~ 따라오시죠!

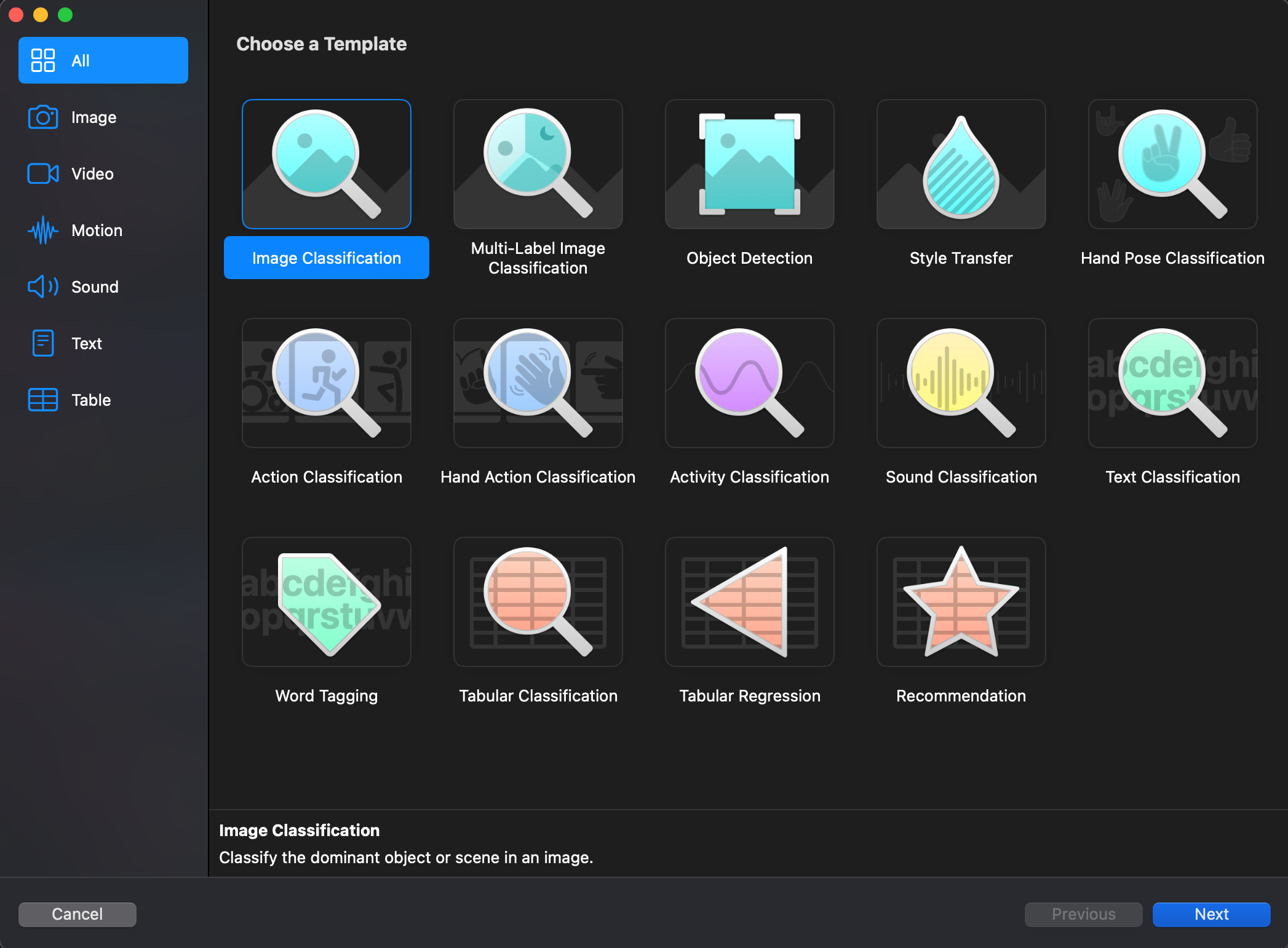
저는 이미지로 분류하려고 하기 때문에 Image Classification을 선택했습니다.

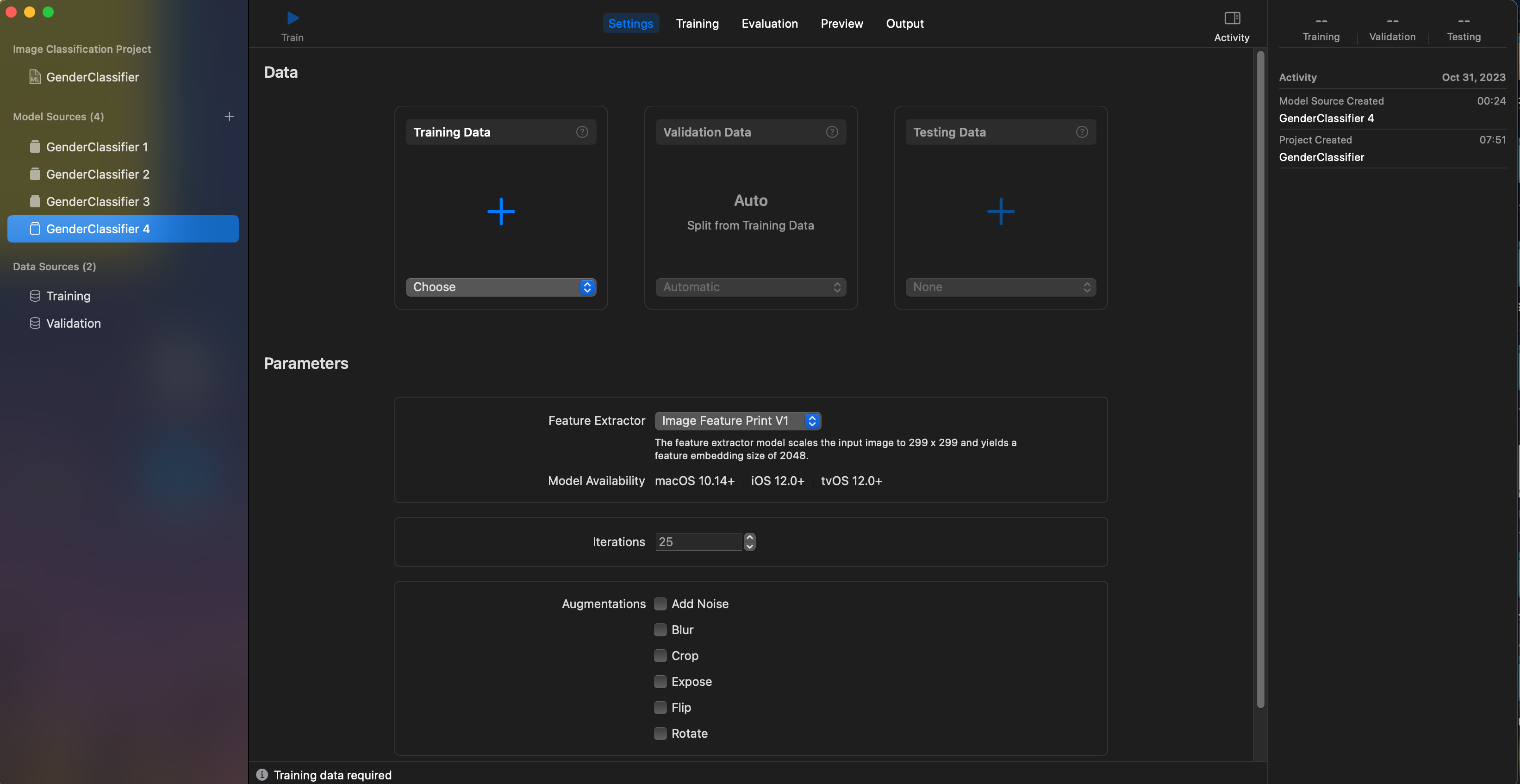
저는 이전에 모델링 한 파일이 있어 4번 파일로 생성되었지만, 처음 생성하면 1번으로 생성되는 게 맞습니다.
신기한 게 많기 때문에 모델링을 하기 전에 어떤 것이 있는지 먼저 살펴보겠습니다.
여기에 저희가 학습시킬 데이터를 넣으면 되는 곳입니다.
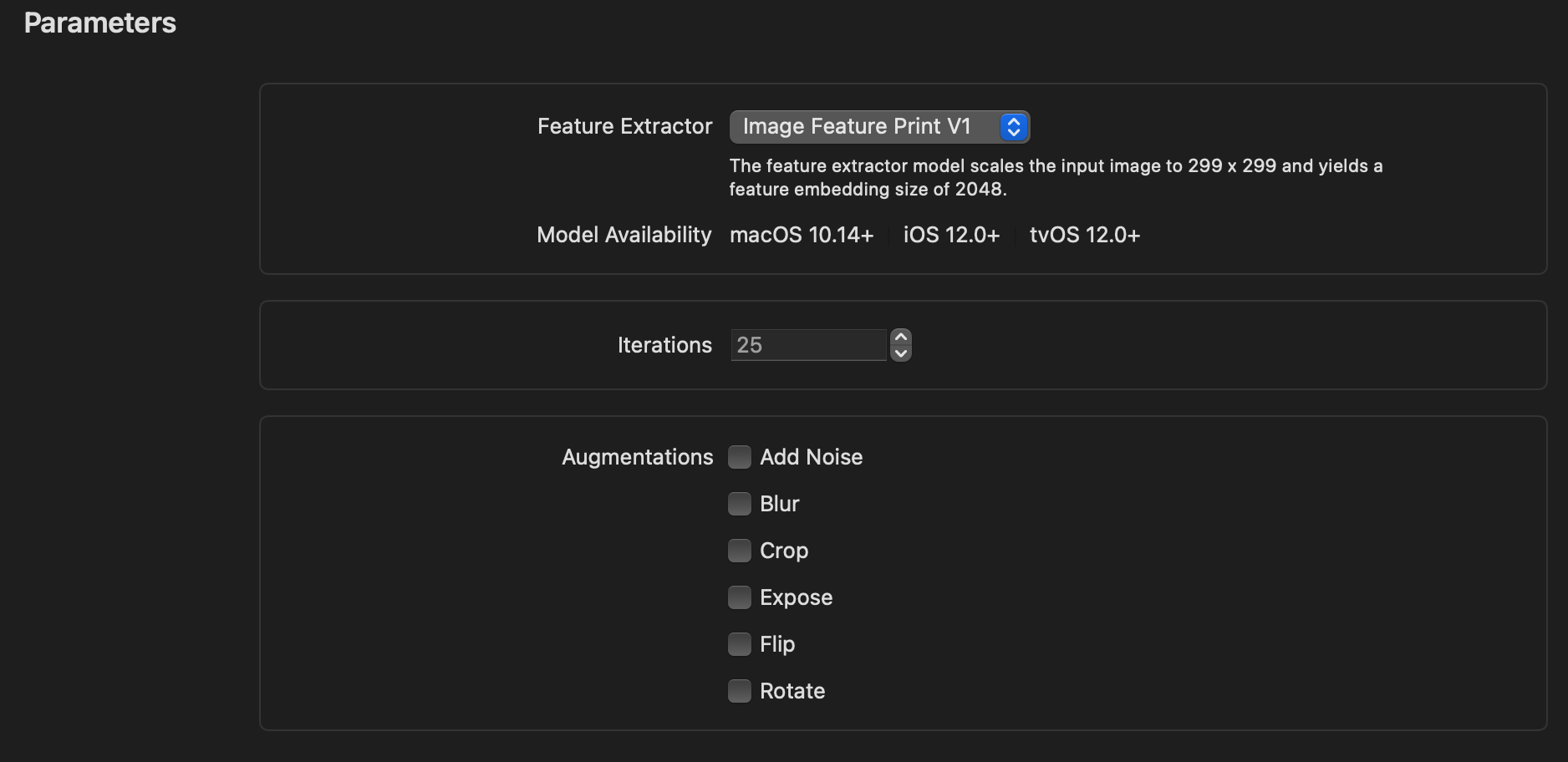
- Iterations(반복 횟수)
학습을 몇 번 반복할 것인지 정할 수 있습니다. (학습을 많이 반복한다고 모델 성능이 높은 것이 아닙니다!)
- Augmentations(증강)
각 데이터 세트의 이미지를 복사하여 추가 이미지를 수집하지 않고도 변환 또는 필터를 적용합니다. (데이터 수가 적을 때 유용합니다.)
모델링 시작하기
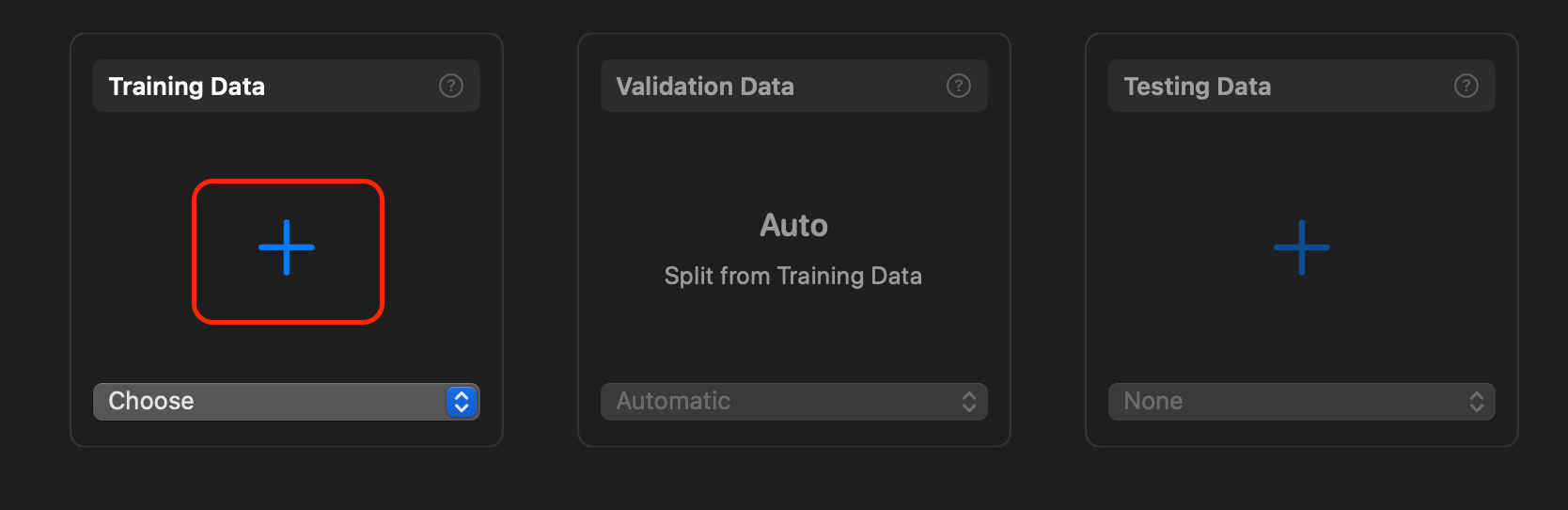
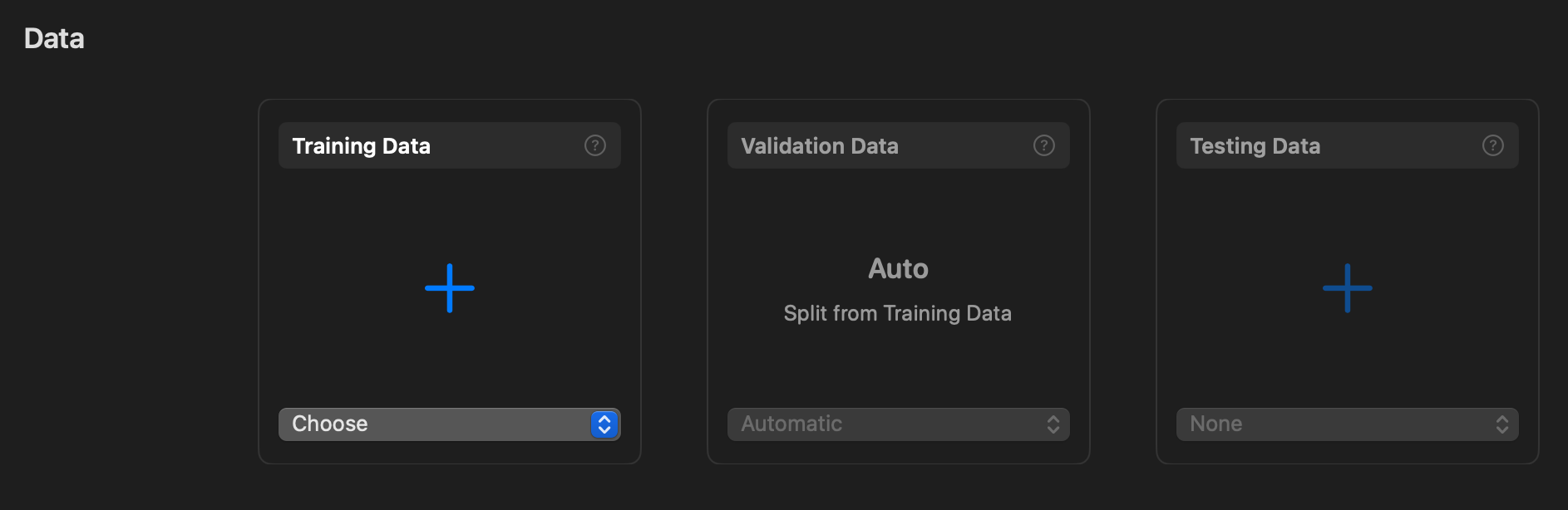
Training Data를 선택하여 Training 폴더를 넣어줍니다.
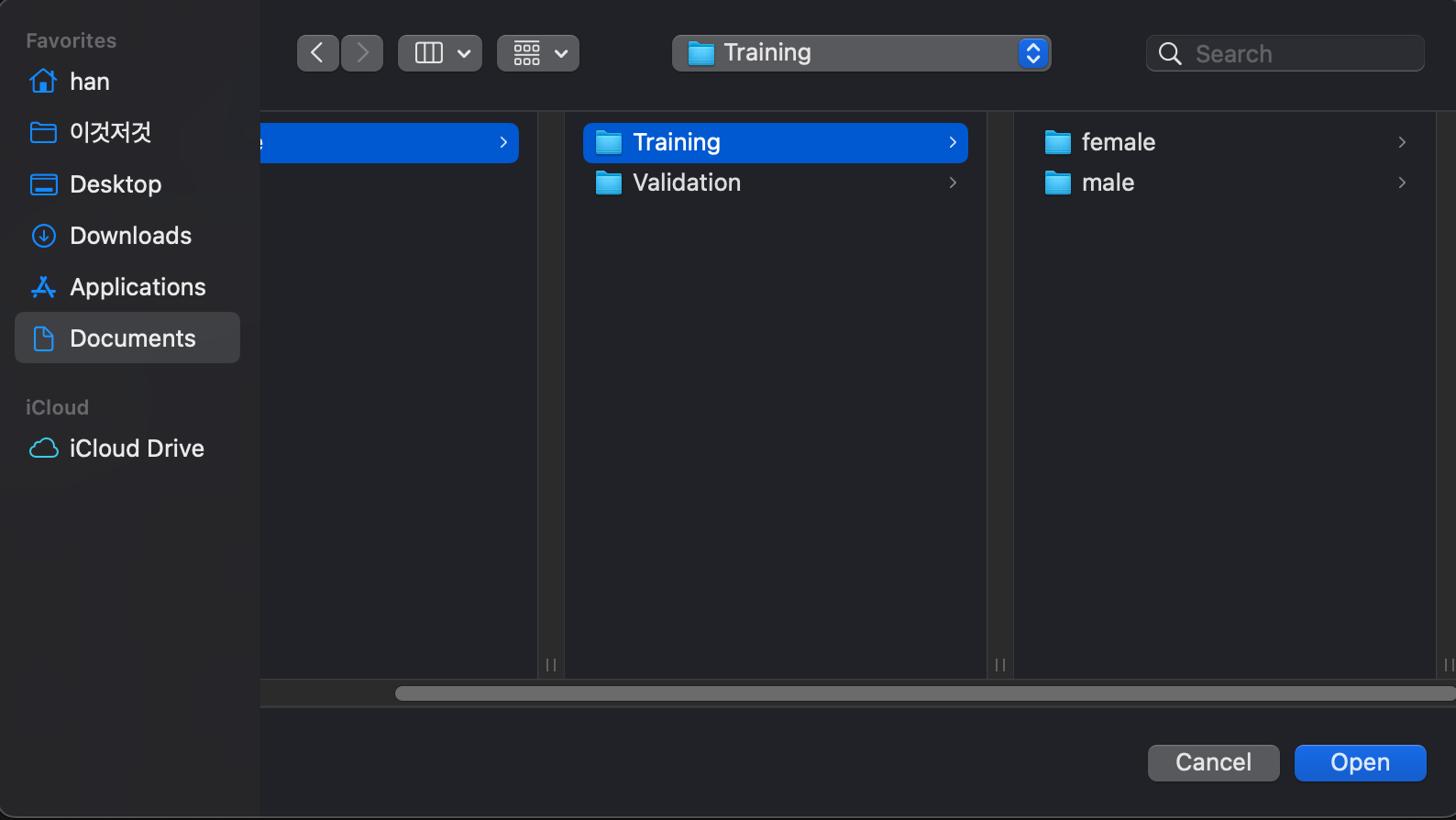
마찬가지로 오른쪽의 Testing Data를 선택하여 Validation 폴더를 넣어줍니다.
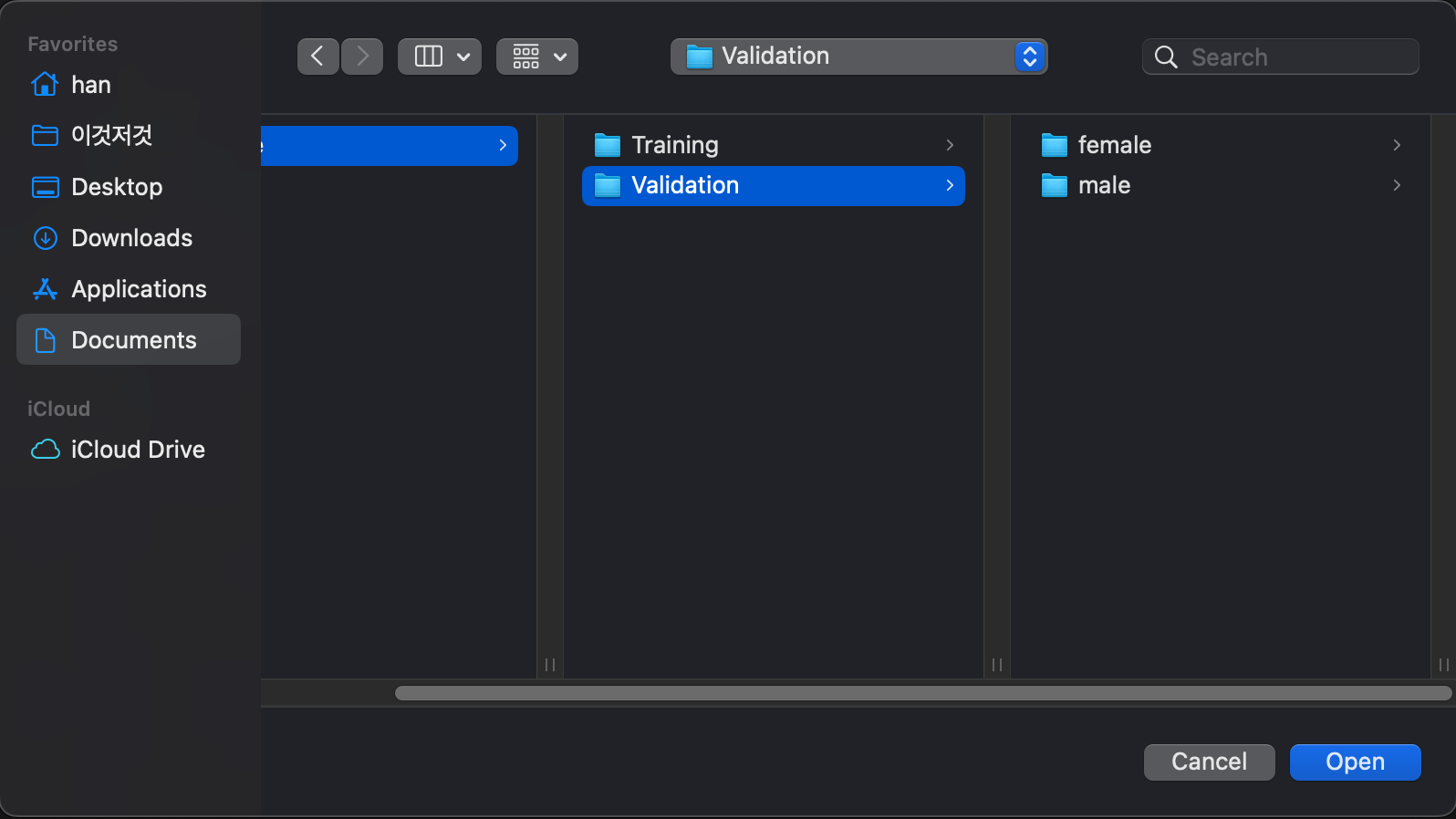
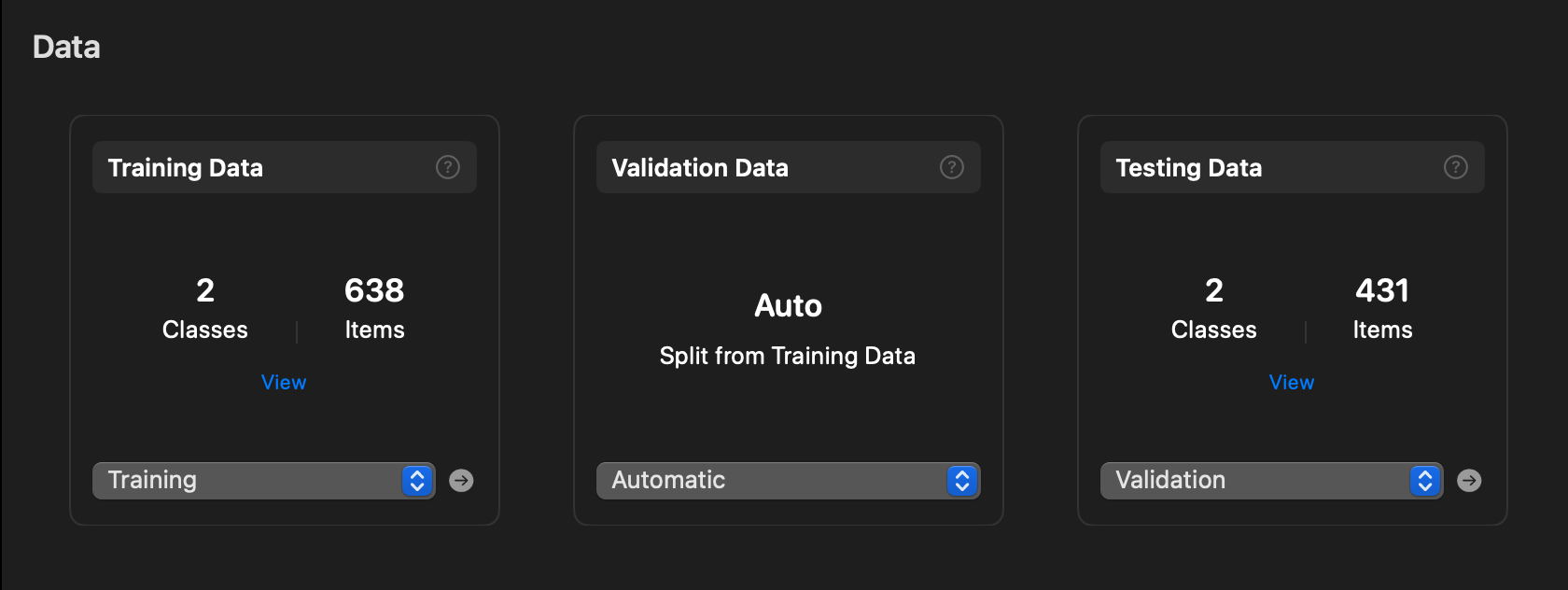
Training Data와 Testing Data 폴더를 잘 넣었다면 위와 같이 데이터가 잘 들어간 것을 볼 수 있습니다.
(Class 2개 = female, male)

이제 Train을 누르면 머신러닝을 시작하게 됩니다!
(저는 데이터 수가 적기 때문에 Augumentations에서 몇 개 선택했습니다.)
모델 해석
학습이 끝나면 아래같이 테스트 정확도 및 실패 등 여러 정보를 볼 수 있는데 해석할 줄 알아야겠죠?
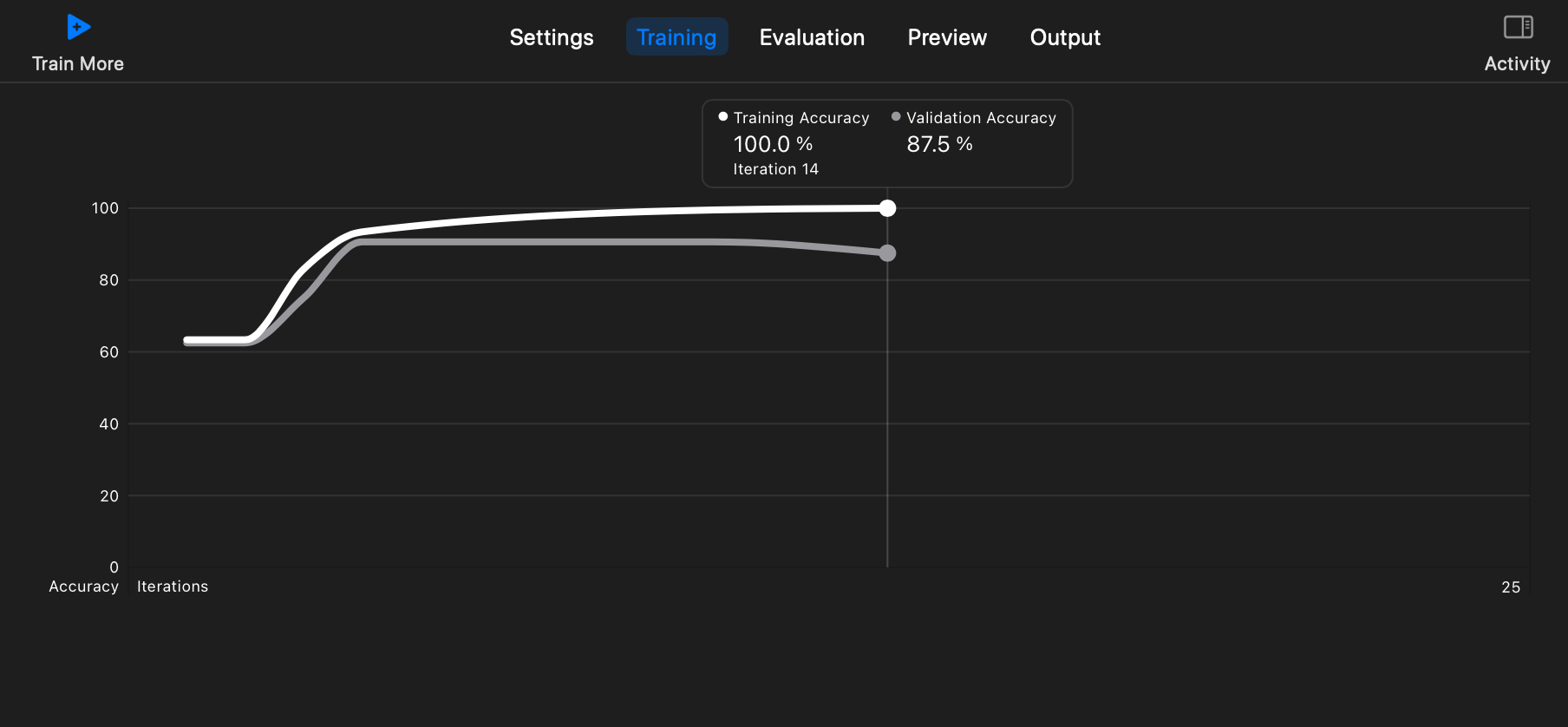
- Training Accuracy(훈련 정확도)
훈련 정확도는 훈련 데이터에 모델을 학습시킬 때 모델이 훈련 데이터에 얼마나 잘 맞는지를 측정한 지표입니다.
훈련 정확도는 일반적으로 높습니다.(100%에 가까울 수 있음) 왜냐하면 모델은 훈련 데이터에 맞추어 학습되기 때문입니다.
훈련 정확도는 모델이 훈련 데이터에 대한 성능을 나타내며, 과적합(Overfitting) 문제를 나타낼 수 있습니다. 과적함은 모델이 훈련 데이터에 너무 맞추어져 새로운 데이터에 대한 일반화 능력이 떨어지는 상황을 의미합니다.
- lidation Accuracy(검증 정확도)
검증 정확도란 검증 데이터에 대한 모델의 성능을 측정하는 지표입니다.
검증 정확도는 모델이 새로운 데이터에 대한 성능을 나타내므로 모델의 실제 성능을 평가하는 데 더 유용합니다.
검증 정확도와 훈련 정확도 사이의 큰 차이가 있는 경우, 모델이 과적합되었거나 고품질의 모델이 아닐 수 있습니다.
- Testing Accuracy(테스트 정확도)
테스트 정확도란 기계 학습 모델의 성능을 평가하기 위해 사용되는 또 다른 중요한 지표입니다.
중요한 점은 테스트 데이터는 모델 훈련 및 평가 과정 중에 완전히 독립적이어야 합니다. 그렇지 않으면 모델이 테스트 데이터를 미리 알고 있을 수 있으며, 이로 인해 정확한 성능 측정이 어려워질 수 있습니다.
한마디로 초반에 데이터를 넣을 때 학습 데이터와 테스트 데이터가 겹치지 않아야 제대로 평가할 수 있다는 뜻입니다.
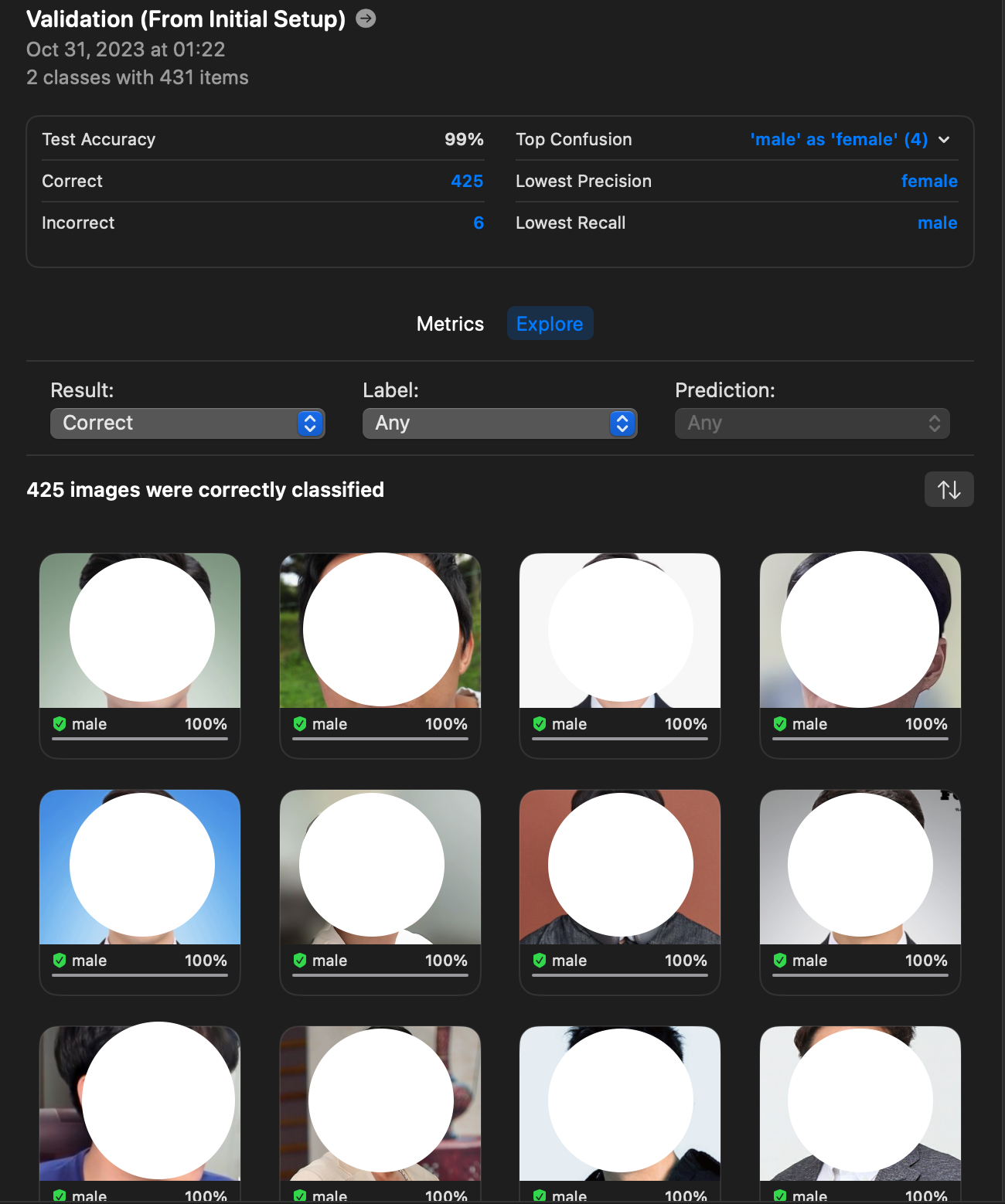
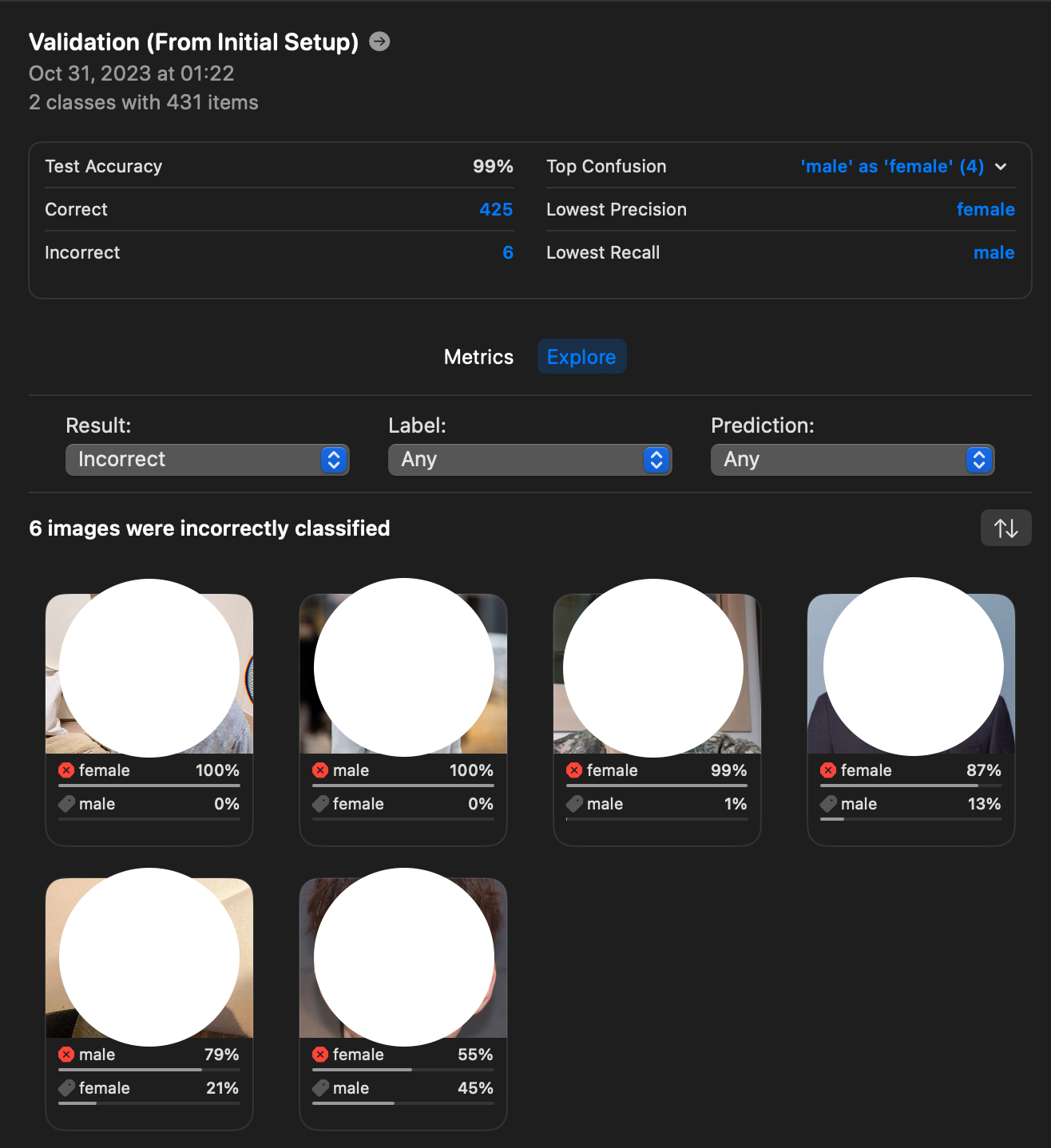
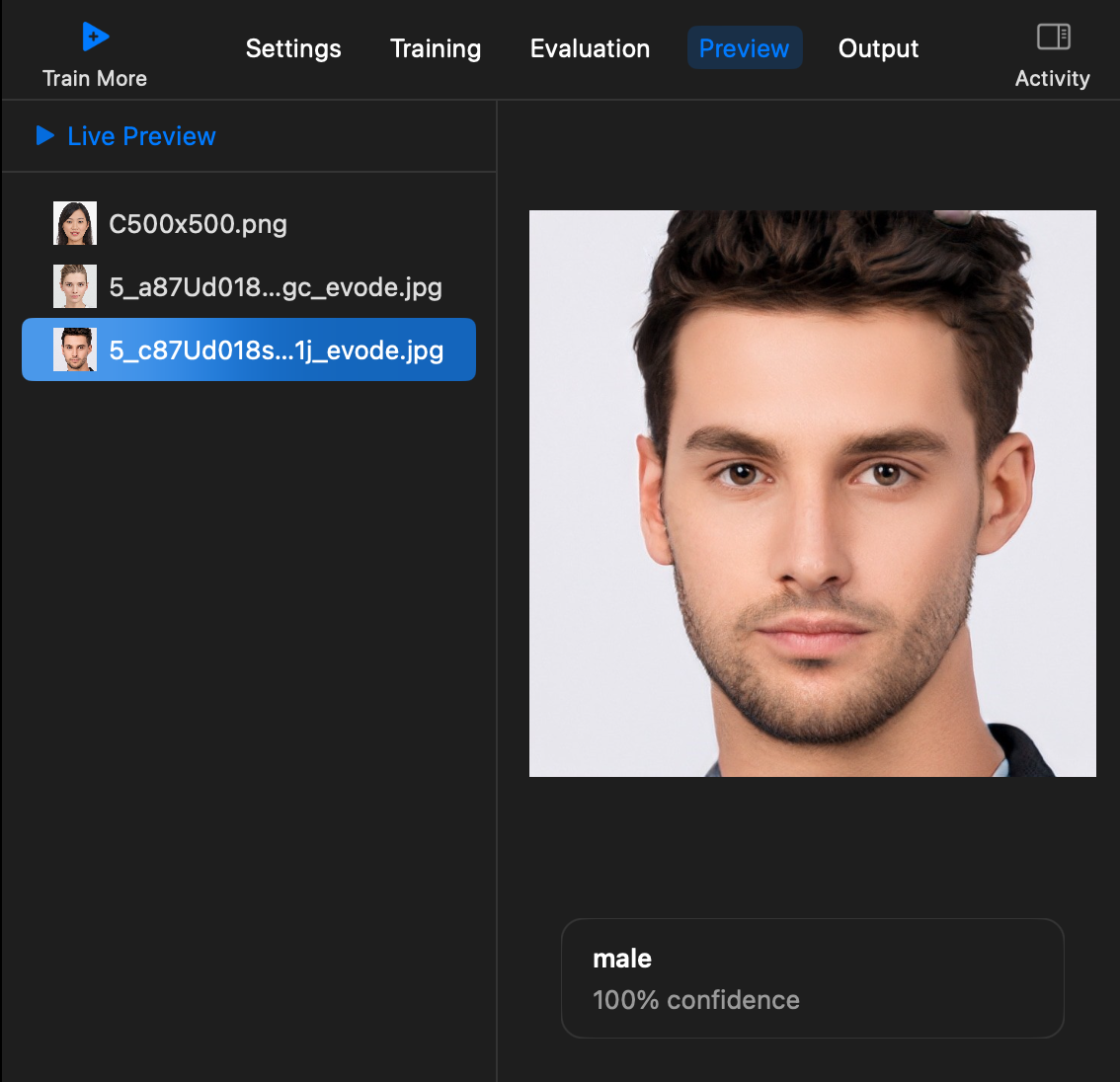
Preview에서 실시간 테스트도 가능하고 이미지를 드래그하면 위와 같이 결과값을 볼 수 있습니다.
모델 정확도 개선
학습시킨 모델의 정확도를 개선하기 위해서 몇 가지 방법이 있습니다.
- 학습 반복 횟수 증가 후 추가 학습
Augumentations을 설정 후 학습- 다양한 데이터를 추가 후 추가 학습
❗ 주의할 점
- 과도한 반복 학습은 오히려 정확도를 떨어트릴 수 있다.
모델이 훈련 데이터에 지나치게 적응하여 새로운 데이터에 대한 일반화 능력이 부족할 수 있습니다.
Overfitting(과적합)
- 데이터가 많을수록 좋지만, 반드시 많은 데이터 학습 수가 모델의 성능을 좌우하지는 않는다.
아래의 데이터를 보면 첫 번째 모델의 경우 학습시킨 데이터 수가 49,201개로 두 번째 모델의 데이터 개수인 638개 보다 압도적으로 많은 것을 볼 수 있습니다.
하지만 결과값을 보면 첫 번째 모델이 데이터 수가 많음에도 불구하고 검증 정확도가 떨어지는 것을 볼 수 있습니다.
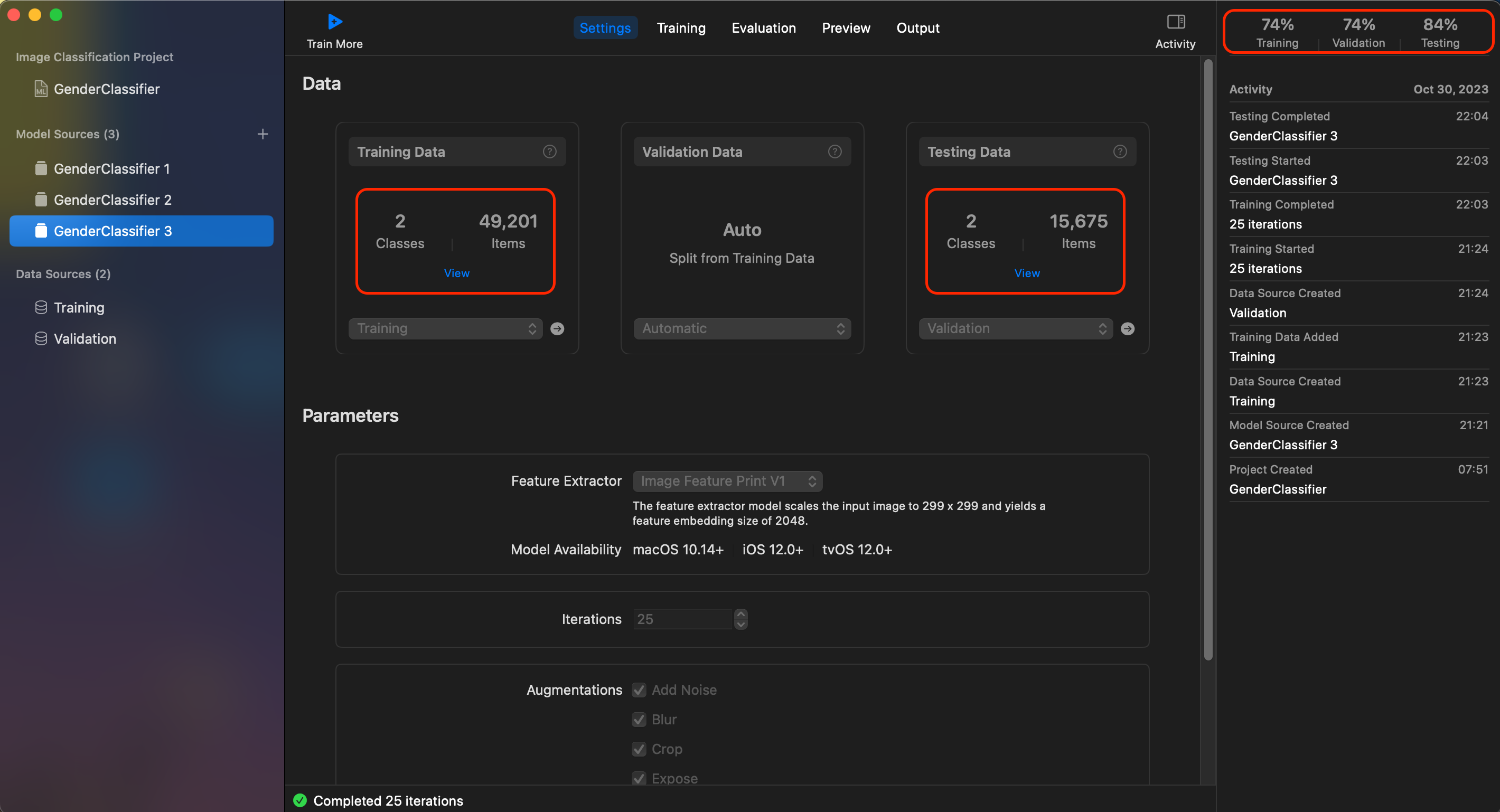
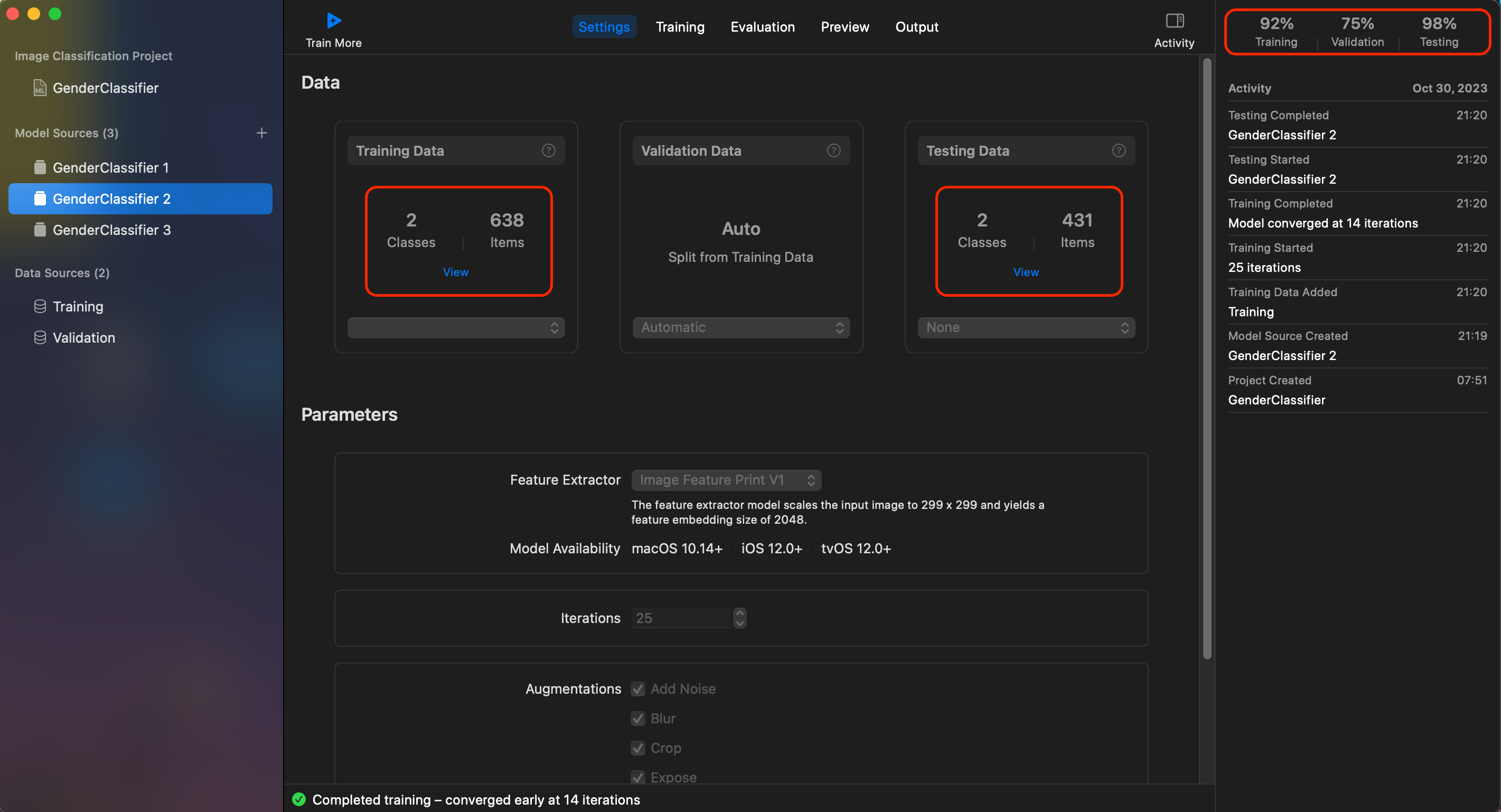
- 데이터의
양보다 품질이 중요합니다. (품질이 낮은 데이터는 모델의 성능을 저하시킬 수 있습니다.)
- 데이터의
다양성이 중요합니다. (모델이 여러 다양한 예제를 보는 것이 중요합니다.)
참고 자료
https://ios-daniel-yang.tistory.com/28?utm_source=pocket_saves
다음 포스팅은 오늘 만들어 본 모델을 사용하는 방법에 대한 내용으로 찾아오겠습니다.
