
자료구조 중 선형구조에 해당하는 Stack, Queue, Deque에 대해 순서대로 정리해보자.
Stack
LIFO(Last In First Out) 방식의 구조로, 한 쪽에서만 데이터 삽입과 삭제가 이루어진다.

자료를 밀어넣는것을 push, 뽑아내는것을 pop이라고 칭한다.
가장 최근에 저장된 데이터는 top, 혹은 peak라고 칭하는데, 이는 스택의 동작 방식에 따라 가장 먼저 삭제될 데이터이다.
스택이 꽉 찬 상태를 overflow, 빈 상태를 underflow라고 한다.
삽입과 삭제 과정
삽입 과정은 다음과 같다.
1. 스택이 꽉 찼는지 확인한다.만약 꽉 찼다면, 즉 overflow 상태라면 종료.
2. 꽉 차지 않았다면, top(peak)+1을 한 후, 그 자리에 데이터를 추가한다.
삭제 과정은 먼저 스택이 underflow 상태임을 확인한 후, 삽입의 역순으로 진행된다.
스택이 사용되는 경우
- 웹 브라우저의 뒤로가기 기능
- 실행 취소(undo)기능
- 문자열 뒤집기 기능
- 후위표기법(postfix) 연산
- DFS 알고리즘
시간 복잡도
삽입과 삭제는 top의 데이터를 다루면 되므로 O(1)
탐색은 스택,큐와 달리 index를 통해 바로 데이터에 접근할 수 있으므로 O(1).
Queue
FIFO(First In First Out)방식의 구조로, 한 쪽에서는 삽입만, 또 다른 한 쪽에서는 삭제만 가능하다.
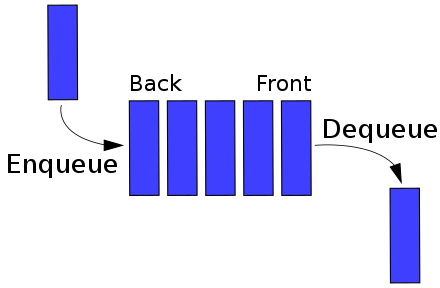
큐의 Rear(Back)에 데이터를 추가하는것을 enqueue, Front에서 데이터를 꺼내는것을 Dequeue라고 한다.
큐는 사이즈가 고정되어있고 데이터의 삽입과 삭제시 나머지 요소들은 이동하지 않는다. 삽입 삭제가 반복되며 결국 빈 공간이 있더라도 활용하지 못하게 되는 경우가 생길 수 있다.
이 공간을 활용하기 위해서는 데이터들을 앞으로 재배치 하는 작업이 필요하다.
이러한 단점을 보완하기 위해 front와 rear가 순환하는 형식의 원형 큐(circular queue)를 사용한다.
또한 데이터에 우선순위를 부여하는 우선순위 큐(Priority Queue)로도 구현하는데, 이는 우선순위가 높을수록 먼제 삭제된다.
우선순위가 없는 큐를 일반 병원 외래 진료로 빗대자면, 우선순위 큐는 응급한 정도에 따라 환자를 처리하는 응급실에 빗댈 수 있겠다.
큐가 사용되는 경우
- cpu 스케줄링
- 프린트 대기열
- BFS 알고리즘
시간 복잡도
스택과 마찬가지로 삽입과 삭제는 front의 데이터를 다루면 되므로 O(1), 탐색은 O(n)의 복잡도를 가진다.
Deque(double-ended queue)
양쪽 끝에서 삽입과 삭제를 할 수 있는 방식의 구조.
큐를 2개 겹쳐놓은 것과 비슷하기 때문에 double-ended queue라고 한다.
연속적인 메모리를 기반으로 하는 시퀀스 컨테이너이고 선언 이후 크기를 줄이거나 늘릴 수 있는 가변적 크기를 갖는다. 또한
시간 복잡도
스택,큐와 마찬가지로 삽입과 삭제는 양 끝의 데이터를 다루면 되므로 O(1), 탐색은 O(n)의 복잡도를 가진다.
