Section 02
배열과 문자열
C++은 복합데이터형을 제공한다
=> 사용자 정의대로 새로운 데이터형은 만들 수 있다
복합데이터형이란?
기본 정수형과 부동소수점형의 조합
1. 배열(array)
같은 데이터형의 집합
배열의 선언
typeName arrayName[arraySize];ex. short month[12];
원소의 데이터형이 short이고, month라는 이름을 가진 크기가 12인 배열
배열의 초기화
typeName arrayName[arraySize] = {1, 2, 3};원소는 중괄호 안의 쉼표로 구분한다
12개의 공간 중 3개만 사용하게 된다
arrayName[index]위 형식으로 배열의 요소를 출력할 수 있다
배열의 규칙
- 배열 원소에 대입할 값들을 콤마로 구분하여 중괄호로 묶어 선언한다
- 초기화를 선언 이후 나중에 할 수는 없다
- 배열을 다른 배열에 통째로 대입할 수 없다
short month[5] = { ... };
short year[12] = { ... };
year = month; // <- 할 수 없다- 초기화 값의 개수를 배열 원소의 개수보다 모자라게 제공할 수 있다
- 배열을 부분적으로 초기화하면, 나머지 원소들을 자동으로 모두 0으로 설정한다
- 배열을 초기화할 때 대괄호 속을 비워두면 컴파일러가 초기화 값의 개수를 헤아려 배열 원소 개수를 저장한다
short month[] = {1, 2, 3};
// month[3]로 자동 인식 => 3 이상의 인덱스를 출력할 수 없다는 단점2. 문자열
문자의 열 (문자의 집합)
문자열의 출력
char a[6] = {'H', 'e', 'l', 'l', 'o', '\0'};자료형을 char로 입력하여 문자열임을 선언한다
마지막에 null 문자(\0)를 넣어 주어야 의미없는 값이 뒤에 따라붙지 않는다
더 효율적인 문자열의 출력
char a[] = "Hello";배열을 초기화할 때 대괄호 속을 비워두면 컴파일러가 초기화 값의 개수를 헤아려 배열 원소 개수를 저장한다는 배열의 특성을 이용하여 대괄호를 비워두고, null 문자를 포함하는 큰따옴표("")를 사용하면 문자열을 보다 효율적으로 출력할 수 있다
문자열을 쉽게 출력하는 방법
char arrayName[] = "text";
사용자 입력과 string
예제
사용자 입력을 받는 법, string이라는 복합 데이터형에 대해 알아본다
#include <iostream>
#include <cstring> // strlen 함수를 사용하기 위해서
using namespace std;
int main() {
const int Size = 15;
char name1[Size];
char name2[Size] = "C++programing";상수(const)를 15로 배열의 Size를 명시하고, 비어있는 배열 name1과 "C++programing"이라는 문자열 상수로 초기화된 배열 name2를 선언한다
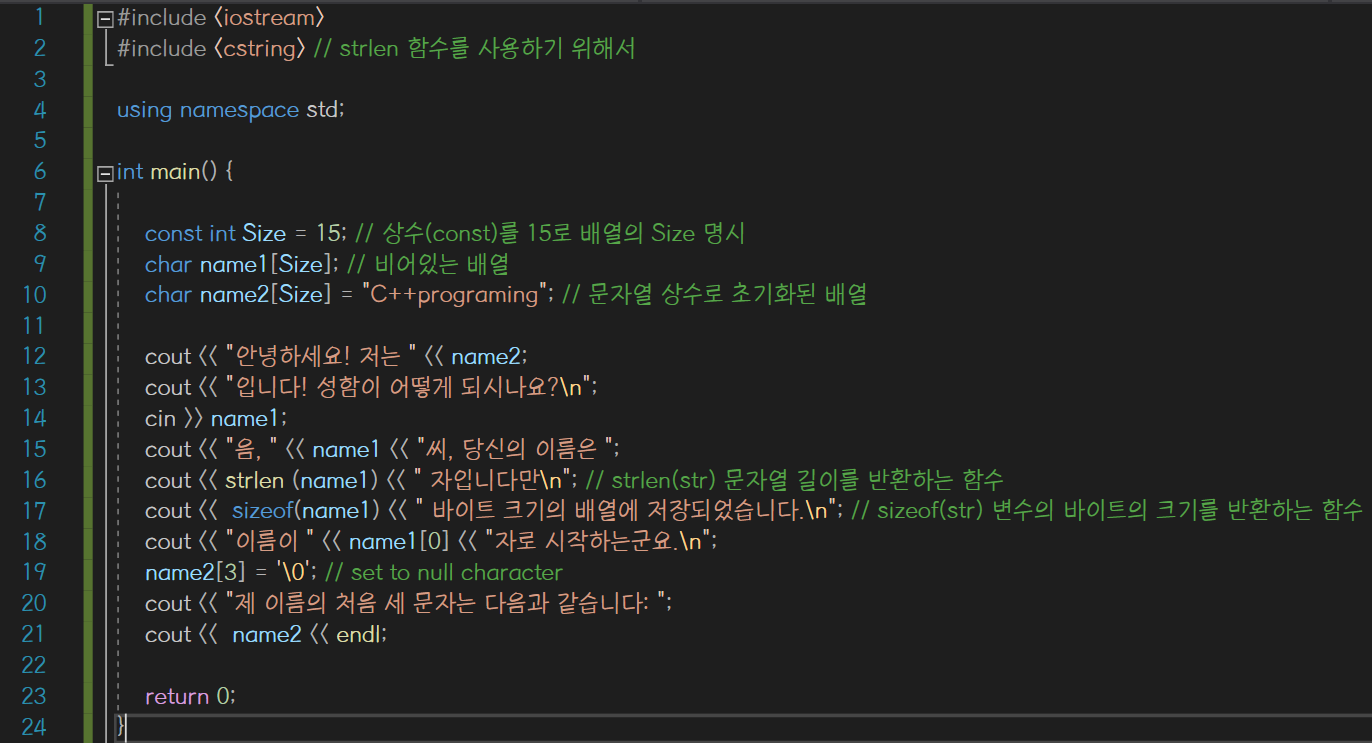
cout << "안녕하세요! 저는 " << name2;
cout << "입니다! 성함이 어떻게 되시나요?\n";
cin >> name1;cin >> 변수
사용자가 프롬프트에 입력한 값을 오른쪽의 변수에 저장한다
cout << "음, " << name1 << "씨, 당신의 이름은 ";
cout << strlen (name1) << " 자입니다만\n";
cout << sizeof(name1) << " 바이트 크기의 배열에 저장되었습니다.\n";strlen(character)
문자열 길이를 반환하는 함수
sizeof(character)
변수의 바이트의 크기를 반환하는 함수
cout << "이름이 " << name1[0] << "자로 시작하는군요.\n";
name2[3] = '\0'; index 3의 자리에 null문자를 삽입하여 cout을 실행했을때 index가 0, 1, 2인 앞의 세 글자만 출력되도록 한다
cout은 null 문자까지만 출력한다
cout << "제 이름의 처음 세 문자는 다음과 같습니다: ";
cout << name2 << endl;
return 0;
}
1. 사용자 입력
cin
사용자가 프롬프트에 입력한 값을 꺽쇠 >> 오른쪽의 변수에 저장한다
입력 값에 공백(띄어쓰기)이 들어갔을 때, 공백 직전까지의 한 단어만 저장한다
프롬프트에서 엔터는 입력이기 때문에 문자열의 끝에 대한 기준이 공백이기 때문이다
공백: space, tap
get/getline
get과 getline은 cin과 .으로 연결되어 동일하게 동작한다
cin.getline(character, Size);character: 입력을 저장할 변수
Size: 입력 받을 최대 크기
최대 크기를 설정하면 공백을 포함하여 입력을 받을 수 있다
2. string
C++에서 문자열을 다루는 방법 중 하나
string str1;
string str2 = "oatmeal";복합데이터명 string을 명시하고 값을 표기하지 않거나,
쌍따옴표 안에 선언하고 싶은 값을 넣어 선언할 수 있다
string의 특징
- C 스타일로 string 객체를 초기화할 수 있다
C 스타일: 선언, 정의, 초기화의 방식 - cin을 사용하여 string 객체에 키보드 입력을 저장할 수 있다
- cout을 사용하여 string 객체를 디스플레이할 수 있다
- 배열 표기를 사용하여 string 객체에 저장되어 있는 개별적인 문자들에 접근할 수 있다
=> string과 문자열은 기본적으로 동등하게 사용할 수 있다
string만의 장점
문자열과 달리 배열의 크기를 정하지 않아도 된다
문자열은 배열을 다른 배열에 통째로 대입할 수 없으나, string은 그것이 가능하다
구조체
C++만의 장점
사용자의 입맛대로 원하는 데이터형을 만들 수 있다
이 장점이 가장 잘 드러나는 복합데이터형이 바로 구조체
구조체란?
다른 데이터형이 허용되는 데이터의 집합
cf. 배열: 같은 데이터형의 집합
구조체의 등장 이유
야구선수로 예시를 들어 설명하면,
int main() {
string name;
string position;
float height;
float weight;
return 0;
}결국에는 이 모든 데이터가 한 사람의 축구선수에 대한 데이터이다
=> 여러 개의 변수로 표기하는 게 아니라 배열로 한꺼번에 정리하면 편하겠다
=> 다른 데이터형이 허용되는 데이터의 집합인 구조체 등장
구조체의 선언과 초기화
구조체의 선언
struct structName
{
string str;
float flt;
// 예시
}str과 flt는 구조체 structName 안에 member라고 불리는 구성 요소로 자리잡게 된다
구조체의 멤버 연산자 dot (.)
MyStruct A;
A.name = "Ohtani";
A.position = "Pitcher / Designated hitter";
A.height = 193;
A.weight = 102;구조체의 초기화
MyStruct A = {
"Ohtani",
"Pitcher / Designated hitter",
193,
102
};콤마로 멤버들끼리 구분한다
콤마를 기준으로 순서대로 초기화된다
아래와 같이 구조체를 정의하는 부분에서 중괄호 뒤에 변수명을 입력하게 되면, 새로운 구조체를 선언하지 않아도 자동으로 생성된다
struct MyStruct
{
string name;
string position;
int height;
int weight;
} B;
B = {
// 이렇게 아무것도 입력하지 않으면 0으로 초기화된다
};구조체 배열
구조체 역시 배열로 선언할 수 있다
Mystruct A[arraySize] = {
{"Ohtani", "Pitcher / Designated hitter", 193, 102},
{"someone", "something", 174, 60}
}배열에서 구조체의 원소에 접근하는 법
structName[index].memberName
// ex. A[0].height공용체와 열거체
공용체 (union)
서로 다른 데이터형을 한 번에 한 가지만 보관할 수 있는 데이터형
공용체 정의 방법
union unionName
{
int intVal;
long longVal;
float floatVal;
};공용체 선언 방법
unionName A;코드로 알아보기
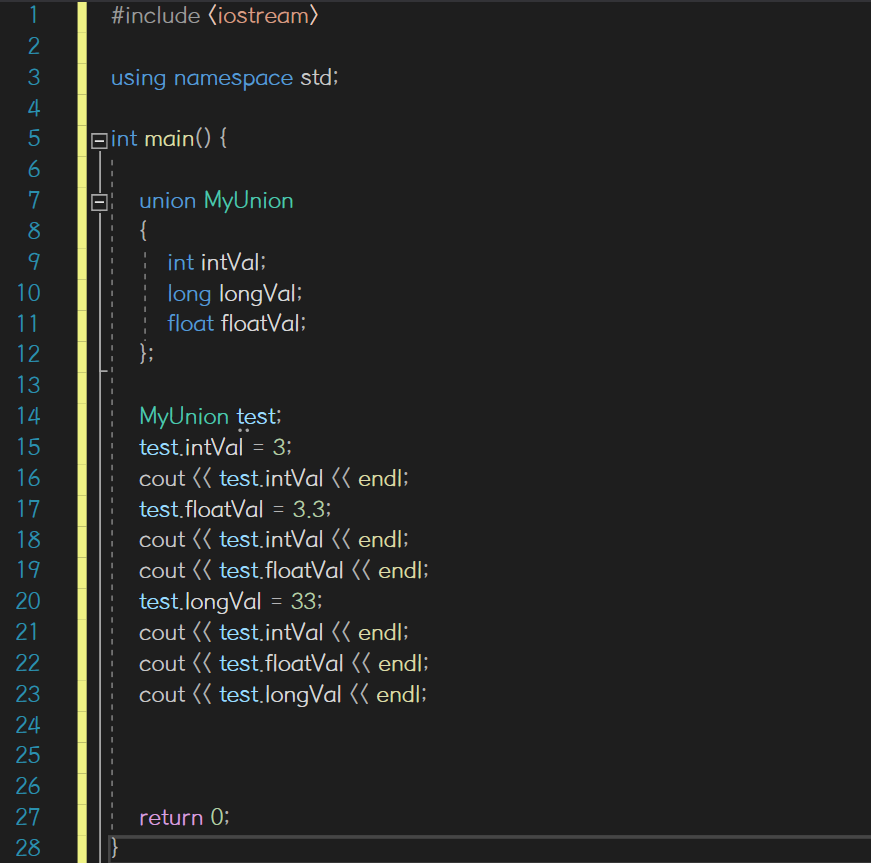
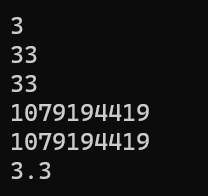
첫 출력에서는 intVal이 3으로 잘 출력되었다
두번째와 세번째에서는 intVal과 longVal 모두 33으로 출력되었다
네번째와 다섯번째에서는 intVal과 longVal 모두 1079194419로 출력되고, 마지막에 floatVal만 3.3으로 출력되었다
공용체는 한 번에 한 가지의 데이터만 보관할 수 있어 마지막으로 선언한 데이터형만이 보관되고 그 이전의 것들은 소실된다
공용체의 장점
메모리를 절약할 수 있다
열거체 (enum)
C++에서 기호 상수를 만드는 것에 대한 또다른 방법
cf. 상수: 한번 만들고 나서 변경할 수 없는 수
이런 상수를 기호적으로 사용할 수 있는 것이 열거체
열거체 정의 방법
enum enumName {a, b, c, d, ..., z};열거체 선언 방법
enumName A;코드로 알아보기

<기능>
1. spectrum을 새로운 데이터형 이름으로 만든다
2. red, orange, yellow ... 들을 0에서부터 7까지 정수 값을 각각 나타내는 기호 상수로 만든다
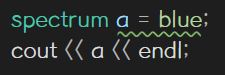

선언한 열거체에는 열거자의 값만 대입할 수 있다
코드에서 열거자 blue의 기호 상수 값이 4이기 때문에 프롬프트에 4가 출력된다
기호 상수는 상수로서 관리하기 때문에 산술 연산을 적용할 수 없다
spectrum a = red + blue; // error열거자들을 정수형에 대입할 때는 int형으로 변환될 수 있다
int b;
b = blue;
b = blue + 3; // 4+3 = 7이 변수 b에 할당된다열거자 초기화
기본적으로는 0부터 시작하여 1씩 더해가며 자동으로 지정된다
명시적 대입 연산자 equal(=)을 사용해서 그 값을 넣어줄 수도 있다
enum spectrum {red = 0, orange = 2, yellow = 4, green, blue, violet, indigo, purple};
초기화 값은 반드시 정수여야만 하고,
초기화하지 않은 열거자들은 직전의 열거자에 1씩 더하는 값으로 초기화된다
ex. 위의 코드에서 green은 5, blue는 6 ...
포인터와 메모리 해제
int val = 3;
cout << &val << endl;&변수명 으로 메모리의 주소를 확인할 수 있다
보통의 주소는 16진수를 사용한다
C++: 객체지향 프로그래밍의 특징
컴파일 시간이 아닌 실행 시간에 어떠한 결정을 내릴 수 있다
=> C와는 달리 코드가 돌아가고 있는 동안에도 결정을 내릴 수 있다
=> 융통성을 가진다
ex. 배열을 생성하고자 할 때,
재래적/절차적 프로그래밍: 배열의 크기가 미리 결정되어야 한다
객체지향 프로그래밍: 배열의 크기를 실행 시간에 결정할 수 있다
= 배열의 크기를 변수로 설정할 수 있다
포인터란?
사용할 주소에 이름을 붙인다
즉, 포인터는 포인터의 이름이 주소를 나타낸다
간접값 연산자/간접 참조 연산자 "*"
예제
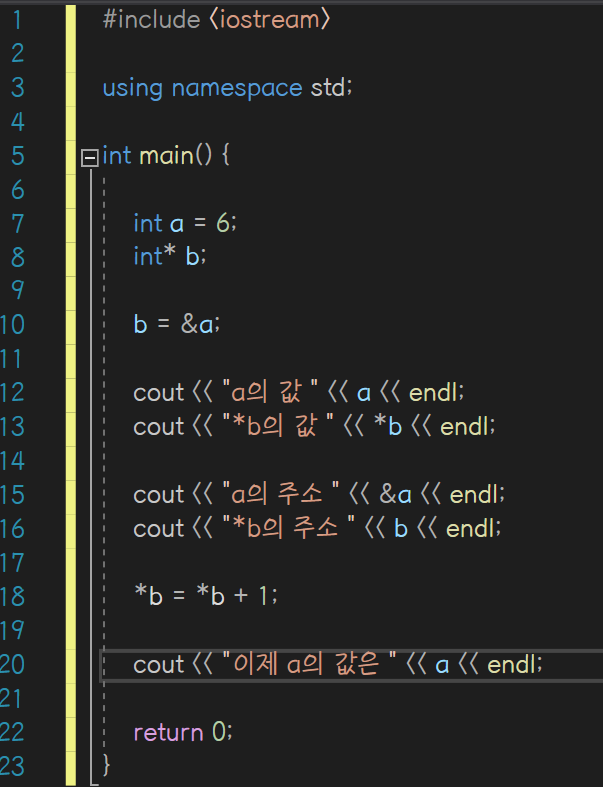

- 그냥 변수의 값: a
그냥 변수의 주소: &a - 포인터 변수의 값: b
포인터 변수의 주소: &b = b
객체지향 프로그래밍에서 포인터가 필요한 이유
포인터를 이용하여 주소의 값에 변화를 주어서 그 값을 수정하게 하는 것이 가능하다
아직 결정되지 않은 메모리를 대입할 수 있다는 점이 포인터의 진정한 쓸모
포인터의 선언
int *a; // C style
int* b; // C++ style
int* c, d; // 가장 앞에 있는 c만 포인터 변수, d는 int 변수로 선언new 연산자
new 연산자의 기능
- 어떤 데이터형을 원하는지 new 연산자에게 알려 주면,
- new 연산자는 그 데이터형에 알맞는 크기의 메모리 블록을 찾아내고
- 그 블록의 주소를 리턴한다
예제
int* pointer = new int; int형 데이터를 지정할 수 있는 새로운 메모리가 필요하다고 알려준다
new 연산자는 뒤따라오는 데이터형을 확인하고 몇 바이트가 필요한지 계산한다
현재 예제에서는 4byte -> 저장할 수 있는 메모리 블록을 찾아 그 주소를 int* pointer에게 리턴하여 초기화한다
이전 시간에는 따로 int형 변수를 만들어서 그 주소를 가지고 포인터를 초기화했는데, new 연산자를 사용하게 되면 그러한 과정 없이 포인터 변수를 초기화할 수 있다
비교
- 이전 방식
int a;
int* b = &a;b와 a의 주소를 통해서 접근 가능
- new를 사용
int* pointer = new int;pointer 변수 하나만이 오른쪽의 int형 값에 접근할 수 있는 유일한 방법
이 포인터는 지시하는 메모리의 이름이 없는데 어떻게 접근하는가?
포인터가 데이터의 객체를 지시하고 있다고 표현한다
=> 메모리 제어권을 사용자에게 준다는 장점!
delete 연산자
사용한 메모리를 다시 메모리 풀로 환수한다
환수된 메모리는 프로그램의 다른 부분이 다시 사용할 수 있다
int* ps = new int;
// 어떠한 코드로 메모리 사용
delete ps;new를 사용하고 나서 반드시 delete를 사용해야 한다
그렇지 않으면 대입은 되었으나 사용되지 않는 메모리 누수가 발생할 수 있다
delete 규칙
- new로 대입하지 않은 메모린는 delete로 해제할 수 없다
- 같은 메모리 블록을 연달아 두 번 delete로 해제할 수 없다
- new[]로 메모리를 대입할 경우. delete[]로 해제한다
- 대괄호를 사용하지 않았다면 delete도 대괄호를 사용하지 않아야 한다
예제
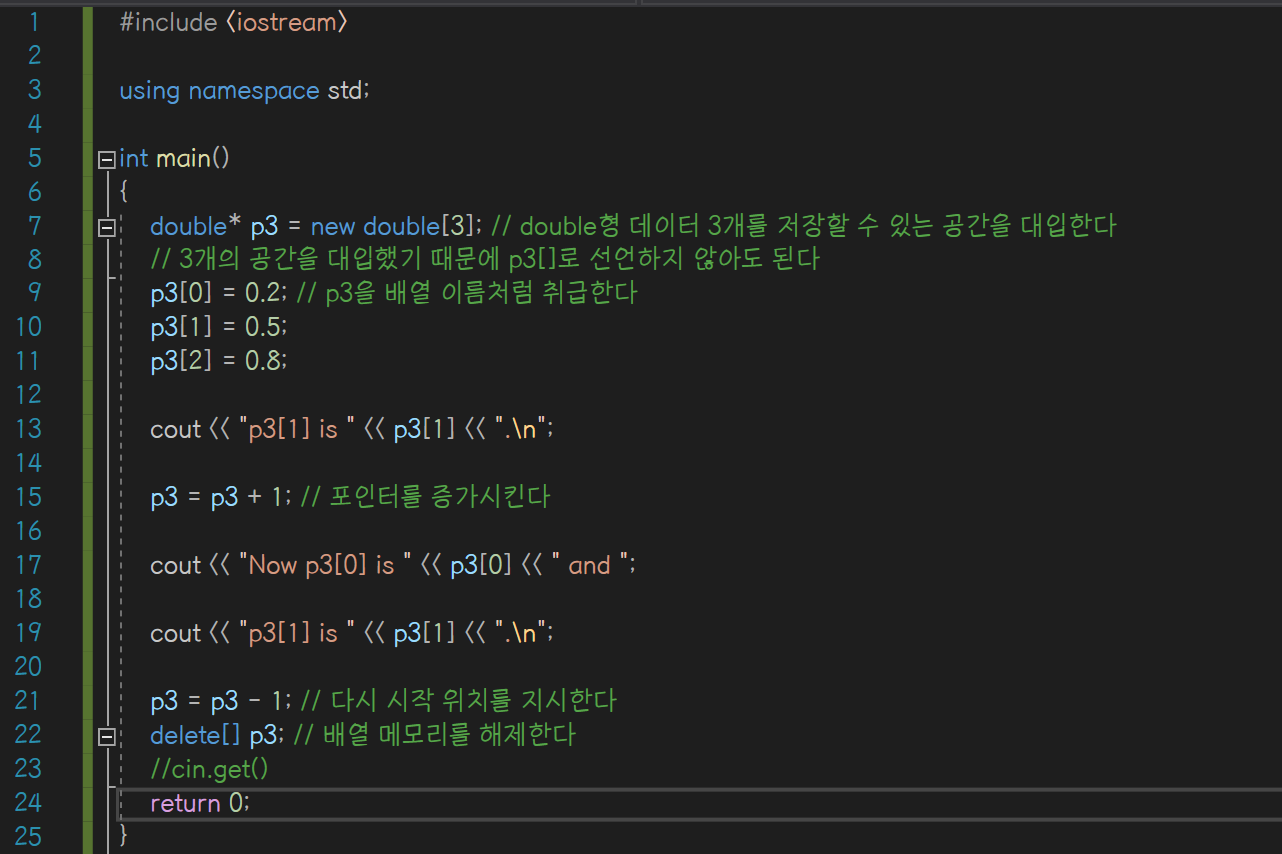

p3+1을 했을 때,
p3[0] = 0.2, p3[1] = 0.5, p3[2] = 0.8에서
p3[0] = 0.5, p3[1] = 0.8을 가리키게 된다
+1에서의 1은 double형 데이터 공간 한 개로 의미된다
포인터 연산
포인터와 배열
포인터 변수에 1을 더하게 되면 값이 그 포인터가 지시하는 데이터형의 바이트 수 만큼 증가하게 된다
ex. p3의 포인터 변수가 double형이니까 double의 바이트만큼 그 값이 증가하게 된다
=> 그래서 정확히 p3[0] = 0.2, p3[1] = 0.5, p3[2] = 0.8에서
p3[0] = 0.5, p3[1] = 0.8으로 다음의 값을 가리키게 된 것
new 연산자를 통해 동적인 배열을 생성할 수 있고, 포인터를 사용해 그 배열의 원소에 개별적으로 접근할 수 있다
포인터와 문자열


코드 설명
char형의 배열로 문자열을 정의하고자 할 때는 문자열의 크기를 미리 컴파일러에게 알려 주어야 하는데, 지금같은 경우에는 size가 1보다 작은 문자라면 사용자가 몇 글자의 문자를 입력할지 모르는 상황이다
=> new 연산자를 통해 사용자가 몇 글자의 문자를 입력하든 문자를 복사하기 충분한 공간을 ps에게 부여해줄 수 있다
컴파일 시간의 어떤 배열의 크기를 결정하는 것보다
실행 시간의 배열이 크기를 결정하는 것이 메모리적 차원에서 훨씬 유리하다
포인터와 구조체
동적 (dynamic)
컴파일 시간이 아닌 실행 시간에 메모리를 대입받는 것
동적 구조체 생성
배열 생성 방법과 동일하다
structName* ps = new structName;동적으로 생성된 구조체 안에서는 기존 멤버 연산자(.)와 달리 화살표(->)를 통해 구조체의 멤버에 접근할 수 있다
예제
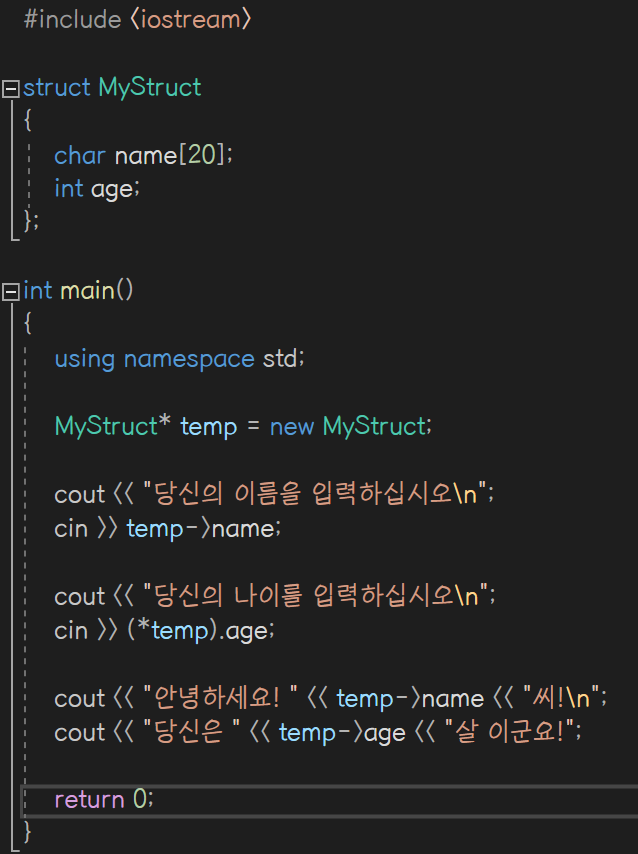

temp->name;
(*temp).age;어느 쪽을 선택해도 기능은 같다
