Section 06
인라인 함수와 디폴트 매개변수
인라인 함수
일반적으로 함수의 호출은 함수의 주소로 점프하는 과정이다
인라인 함수는 컴파일된 함수 코드가 그대로 프로그램의 다른 코드에 삽입되어 있다
컴파일러의 인라인 함수 호출 = 점프가 아닌 그에 대응하는 함수 코드로 대체
인라인 함수 정의
inline float square(float x) {return x * x;}함수의 원형 부분 앞에 inline 키워드만 붙이면 인라인 함수로 동작한다
이후 함수를 호출하고 사용하는 부분은 일반적인 함수와 똑같다
인라인 함수는 프로그램의 실행속도 향상을 위해 지원된 기능이다
디폴트 매개변수
함수를 호출할 때 실제로 매개변수를 생략했을 경우에 실제 매개변수 대신 사용되는 디폴트, 즉 기본 값이다
함수의 원형에서 parameter의 타입이 정의되어 있는데 사용자가 argument로 그 값을 전해주지 않았을 때 기본적으로 함수에게 전달되는 값이다
예시
int sumArr(int*, int n = 1);이렇게 int n = 1 이라고 선언했을 때, 이 n에 해당되는 argument의 값이 없다면 이 n은 default로 1의 값을 가지게 된다
디폴트 매개변수 정의 순서
반드시 오른쪽에서 왼쪽의 순서로 디폴트 매개변수를 정의해 주어야 한다
ex. int sumArr(int*, int n = 1); // 가장 오른쪽 변수인 n만 디폴트=> 디폴트 매개변수를 선언해 주고자 할 때에는
1. 선언하고자 하는 디폴트 매개변수의 위치를 가장 오른쪽으로 선언하거나
2. 그 매개변수보다 오른쪽에 위치한 모든 매개변수에 대해 디폴트 값을 지정해 주어야 한다
참조 변수
참조(reference)란?
미리 정의된 변수의 실제이름 대신 사용할 수 있는 어떠한 대용적인 이름
함수의 매개변수에 사용한다
C++는 구조체의 원본이 아니라 그 복사본을 만들어서 복사본에 대해 작업을 한다
그런데 참조를 매개변수로 사용하게 된다면 그 함수는 복사본이 아니라 원본의 데이터를 가지고 작업을 하게 된다
=> 구조체의 볼륨이 크가면 함수에서 포인터 대신 참조를 사용하는 것이 실행속도 측면에서 유리하게 코딩할 수 있다
참조 변수 선언
int a;
int &b = a;참조 연산자 &, 참조 변수로 사용할 이름 b, 어떤 변수에 대한 참조인지 a를 입력
참조 연산자 &는 주소 연산자와 동일하다
참조로 전달하기
참조 변수의 방식으로 매개 변수를 전달하는 것
C와 C++ 언어간의 차이
한눈에 알아보기

함수에 매개변수를 전달해주는 세가지 방법을 한번에 정리하였다
정의하고 있는 코드는 모두 같으나, parameter 값의 형식에 차이가 있다
간단한 예시를 통해 값을 출력해 보면, swapA의 기존 값이 교환된 것을 볼 수 있으나, swapB와 swapC의 기존 값은 그대로 유지되는 것을 알 수 있다
함수에게 값으로 내용을 전달할 때(swapC)는 복사본을 가지고 작업하기 때문에 원본에 대한 내용이 침해되지 않는다
복사본이 아닌 원본에 대해 작업을 하기 위해서 참조를 이용해서 값을 전달(swapA)하거나, 포인터를 이용해서 값을 전달하는 방법으로 그 원본에 대한 데이터에 직접적으로 접근할 수 있다
의문점
왜 swapB의 값이 변하지 않았음에도 포인터로 값을 전달하는 방식이 원본에 대한 데이터에 직접적으로 접근할 수 있다는 것인가?
포인터로 값을 전달했을 때, 그 포인터가 가리키는 주소에 있는 원본 데이터를 변경하는 것은 가능하다
그러나, 포인터가 가리키는 주소를 변경하는 것은 불가능
함수에서는 매개변수가 복사되어 사용되기 때문
함수 오버로딩
함수의 다형이란?
함수가 다양한 형태를 지닌다는 것
함수 오버로딩이란?
여러 개의 함수를 같은 이름으로 연결하는 것
함수의 다형 = 함수의 오버로딩
함수 오버로딩의 열쇠
함수 오버로딩의 열쇠는 바로 매개변수의 리스트이다
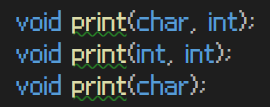
모두 같은 이름의 함수이지만 매개변수에 대해 차이점이 있다
사용자가 print함수를 사용하였을 때 매개변수를 읽고, 그에 알맞는 함수로 C++이 매칭을 시켜주게 된다
오버로딩을 사용하는 경우
서로 다른 데이터형을 대상으로 하지만 같은 작업을 수행하는 함수들에 사용하는 것이 바람직하다
예제
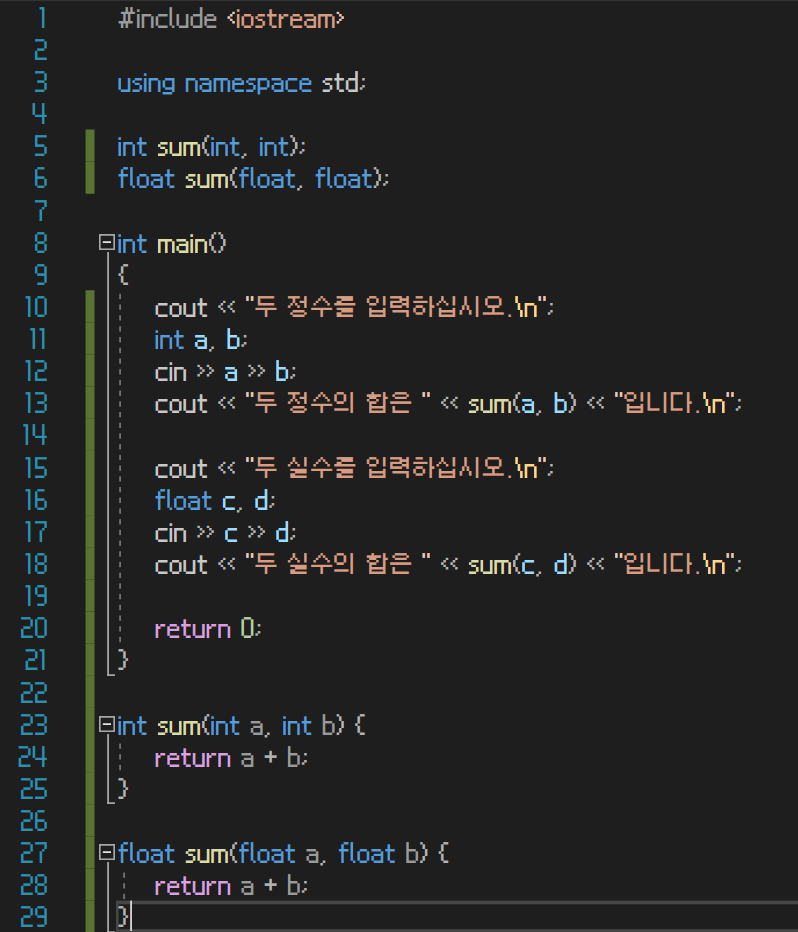
오버로딩을 사용할 수 없는 경우
1. 파라미터의 데이터 형식은 같은데, 리턴형만 값이 다른 경우
파라미터의 데이터 형식에 따라 C++이 매칭시켜 주는 것이 오버로딩이기 때문에 무조건 파라미터의 데이터 형식이 달라야 한다
2. 함수를 사용할 때, 두 개 이상의 함수에 대응되는 경우
여러 함수에 대응된다면 컴파일러가 어떤 함수에 대응시켜줄지 결정을 하지 못하기 때문이다
함수 템플릿
일반화 프로그래밍
템플릿은 구체적인 데이터형 대신에 일반형으로 프로그래밍 하므로 이것을 일반화 프로그래밍이라고 일컫는다
일반화란?
객체지향 프로그래밍의 목표 중 하나
특정한 데이터형에 귀속되지 않고, 일반적으로/범용적으로 사용할 수 있게 만드는 것
함수의 템플릿이란?
함수의 일반화에 대한 서술
함수의 템플릿은 어떠한 구체적인 데이터형을 포괄할 수 있는 일반형으로 함수를 정의한다
= 어떤 데이터형을 템플릿에 매개변수로 전달하게 된다면, 컴파일러가 그 데이터형에 맞는 함수를 생성한다
함수의 템플릿
데이터형에 상관없이 일반적으로 사용할 수 있는 함수를 만드는 것
템플릿
템플릿 작성 방법
template <class templateName>
// or
template <typeName templateName>예제

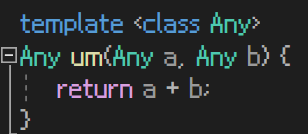
템플릿 Any를 통해서 Any형 변수 a와 Any형 변수 b의 값을 리턴하는 sum이라는 함수를 만들었다
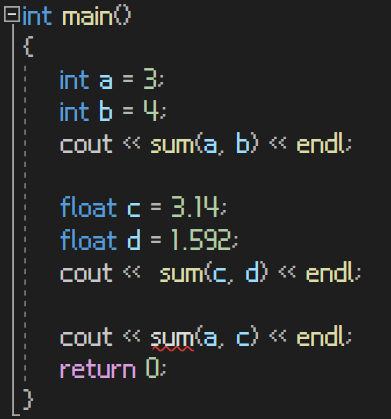
순서대로,
1. int형 변수 a와 int형 변수 b를 받는 sum 함수
2. float형 변수 c와 float형 변수 d를 받는 sum 함수
3. int형 변수 a와 float형 변수 c를 받는 sum 함수 => error!
error의 내용
인수 목록이 일치하는 함수 템플릿 sum에 인스턴스가 없다
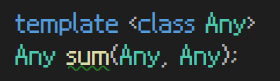
=> 여기서의 템플릿 Any는 현재 데이터형의 일반화이다
=> 어떤 데이터형을 사용할지 정해지지 않았다
위의 코드를 보면 class Any는,
1번에서 int int를 받아 (int+int=)int를 반환하는 함수로 정의되고,
2번에서 float float를 받아 (float+float=)float를 반환하는 함수로 정의된다
그런데 3번에서 int float를 집어넣게 되면,
먼저 들어간 int를 보고 컴파일러가 int를 반환하는 1번 함수로 매칭하게 된다
=> 두번째 매개변수로 int가 아닌 float을 전달하고 있으므로 에러가 발생한다!
3번이 가능하도록 코드 수정
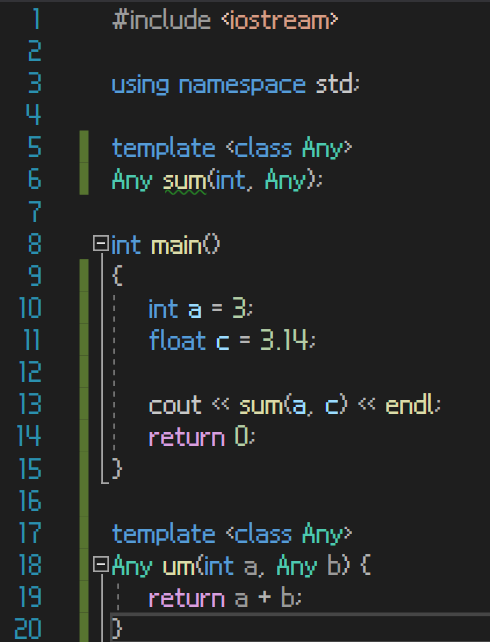
그러나, 이렇게 되면 첫번째 파라미터는 반드시 int형 데이터형이 와야 한다는 제한사항이 붙게 된다
템플릿과 오버로딩
일반형 프로그래밍을 위해 함수 오버로딩을 템플릿에 적용할 수 있다
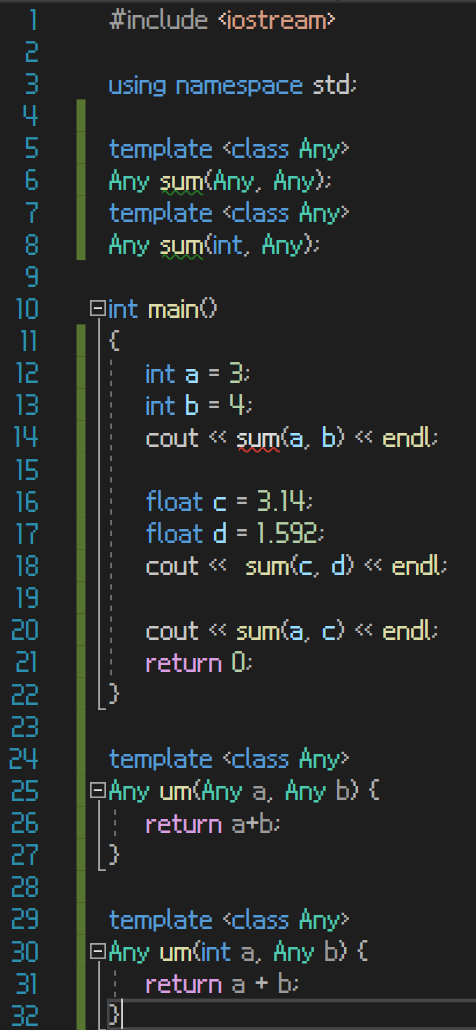
이렇게 되면 여러 함수에 모두 적용되게 할 수 있다
그러나 sum(a, b)에서 오류가 발생하는 이유는 오버로딩을 사용할 수 없는 2번의 상황이기 때문이다
- 함수를 사용할 때, 두 개 이상의 함수에 대응되는 경우
여러 함수에 대응된다면 컴파일러가 어떤 함수에 대응시켜줄지 결정을 하지 못하기 때문이다
