연구자들은 오랜 기간에 걸쳐 동시성 버그에 대해 연구해왔다. 초기 연구의 대부분은 교착상태(deadlock)에 초점을 맞췄고, 최근 연구는 비-데드락(non-deadlock) 버그에 초점을 맞추었다. 이 버그들의 예시를 살펴보면서 어떻게 해결하는 것이 좋을지 생각해보자
어떤 종류의 버그가 존재하는가?
동시성 프로그램에서 어떤 종류의 동시성 버그가 존재할까?
Lu 등의 연구에서 여러 인기있는 동시성 애플리케이션을 분석하였다. 이 연구는 4가지 오픈소스 애플리케이션을 살펴보았다. MySQL(인기 있는 데이터베이스 관리 시스템), Apache(잘 알려진 웹 서버), Mozilla(유명한 웹 브라우저), 그리고 OpenOffice(일부 사람들이 실제로 사용하는 MS Office의 무료 버전)입니다. 아래 사진에서 볼 수 있듯이 총 105개의 버그 중 대부분은 데드락이 아닌 버그(74개)였다.

Non-Deadlock Bugs
위의 연구에 따르면 비-데드락 버그는 동시성 버그의 대부분을 차지한다. Lu 등이 발견한 비-데드락 버그 유형인 원자성 위반 버그(atomicity violation bugs)와 순서 위반 버그(order violation bugs)에 대해 살펴보자
원자성 위반 버그
1 Thread 1::
2 if (thd->proc_info) {
3 fputs(thd->proc_info, ...);
4 }
5
6 Thread 2::
7 thd->proc_info = NULL;이 예제에서 두 개의 다른 스레드가 구조체 thd의 필드 proc_info에 접근한다. 첫 번째 스레드는 값의 NULL 여부를 확인한 뒤 값을 출력하고, 두 번째 스레드는 이를 NULL로 설정한다. 만약 첫 번째 스레드가 fputs호출을 하기 전에 두 번째 스레드가 실행된다면 NULL값을 확인하는게 의미가 없어지게된다. 첫 번째 스레드가 다시 실행되면 NULL 포인터가 역참조되기 때문에 fputs에서 충돌이 발생한다.
Lu 등의 연구에 따르면 원자성 위반의 공식적인 정의는 다음과 같다.
여러 메모리 접근 간의 원하는 직렬화 가능성이 위반된다.
(즉 코드 영역이 원자적이어야 하지만 실행 중에 원자성이 보장되지 않는다.)
위의 예제 코드에서 proc_info의 NULL여부를 확인 한 뒤 fputs()를 호출하는 과정에서 proc_info를 사용하는 것에 대해 원자성 가정을 하고 있다. 이 가정이 틀리면 코드는 작동하지 않을 것이다. 해결책은 공유 변수 참조 주위에 락을 추가하여 각 스레드가 proc_info 필드에 접근할 때 락을 얻도록 한다.
순서 위반 버그
1 Thread 1::
2 void init() {
3 mThread = PR_CreateThread(mMain, ...);
4 }
5
6 Thread 2::
7 void mMain(...) {
8 mState = mThread->State;
9 }이 코드에서, Tread 2는 mTread변수가 이미 초기화(NOT NULL)되었고 사용될 수 있다고 가정한다. 그러나 Tread 2가 생성되자마자 실행되면, 스레드 2의 mMain()에서 mTread에 접근할 때 값이 설정되지 않았으므로 NULL 포인터 역참조로 충돌이 발생할 수 있다.
순서 위반의 공식적인 정의는 다음과 같다.
두 그룹의 메모리 접근 간의 원하는 순서가 뒤바뀐다.
(실행 중에 원하는 순서가 보장되지 않는다.)
이 버그를 수정하려면 순서를 강제해야한다.
1 pthread_mutex_t mtLock = PTHREAD_MUTEX_INITIALIZER;
2 pthread_cond_t mtCond = PTHREAD_COND_INITIALIZER;
3 int mtInit = 0;
4
5 Thread 1::
6 void init() {
7 ...
8 mThread = PR_CreateThread(mMain, ...);
9
10 // signal that the thread has been created...
11 pthread_mutex_lock(&mtLock);
12 mtInit = 1;
13 pthread_cond_signal(&mtCond);
14 pthread_mutex_unlock(&mtLock);
15 ...
16 }
17
18 Thread 2::
19 void mMain(...) {
20 ...
21 // wait for the thread to be initialized...
22 pthread_mutex_lock(&mtLock);
23 while (mtInit == 0)
24 pthread_cond_wait(&mtCond, &mtLock);
25 pthread_mutex_unlock(&mtLock);
26
27 mState = mThread->State;
28 ...
29 }조건 변수 mtCond와 락mtLock, 상태변수 mtInit을 추가했다. 초기화 코드가 실행되면, mtInit의 상태를 1로 설정하고 이를 신호로 보낸다. 만약 Tread 2가 이전에 실행되었다면 이 신호를 기다리게된다. 그리고 신호를 받아서 진행할 것이다. 여기서 mTread자체를 상태변수로 사용할 수도 있지만 단순성을 위해서 그렇게 하지 않았다. 스레드 간에 순서가 중요한 경우 조건변수(또는 세마포어)가 해결책이 될 수 있다.
Deadlock Bugs
이전에 살펴본 것처럼 교착상태가 날 수 있는 코드들이 있다.
Thread 1: Thread 2:
pthread_mutex_lock(L1); pthread_mutex_lock(L2);
pthread_mutex_lock(L2); pthread_mutex_lock(L1);이 코드에서는 Tread 1이 L1을 잡고, Tread 2가 L2를 잡으면서 교착상태가 일어날 것이다.
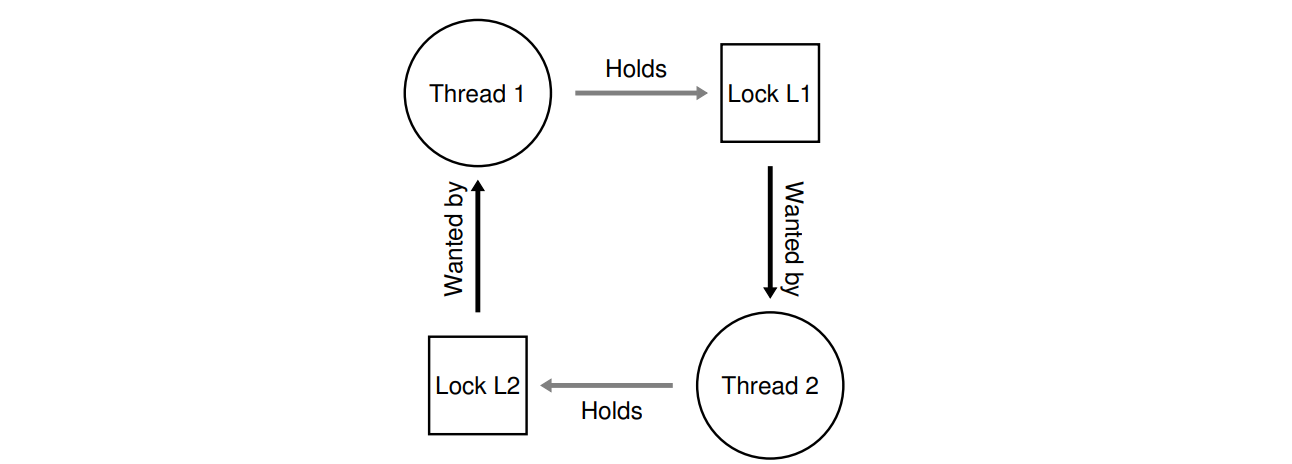
왜 교착 상태가 발생하는가?
위의 교착상태는 Tread 1과 Tread 2의 순서를 정해주면 발생하지 않을 것이다. 쉽게 교착상태를 피할 수 있을 것 같은데 왜 교착상태가 발생하는 것일까?
첫 번째는 대규모 코드에서 복잡한 의존성(dependencies)이 발생하기 때문이다. 예를 들어, 운영체제에서,
가상 메모리 시스템은 디스크에서 블록을 페이지로 가져오기 위해 파일 시스템에 접근해야 할 수 있다.
파일 시스템은 그 블록을 읽어오기 위해 메모리 페이지를 필요로 하여 가상 메모리 시스템에 연락할 수 있다.
이렇게 대규모 시스템에서 자연스럽게 발생할 수 있는 순환 의존성을 피하기 위해 신중히 설계해야
한다.
두 번째는 캡슐화(encapsulation)의 특성 때문이다. 소프트웨어 개발자로서 우리는 구현 세부 사항을 숨기고 소프트웨어를 모듈 방식으로 쉽게 구축하도록 배운다. 하지만 이런 모듈성은 락과 잘 맞지 않는다. Jula 등이 지적한 바와 같이 일부 무해해보이는 인터페이스가 교착 상태를 초래할 수 있다. 예를 들어, Java Vector클래스와 AddAll()메서드를 생각해보자
Vector v1, v2;
v1.AddAll(v2);내부적으로, 메서드는 멀티스레드 안정성을 유지하기 위해 벡터 v1과 v2의 락을 획득해야한다. v1 다음 v2의 락을 얻을건데, 만약 다른 스레드가 거의 동시에 v2.AddAll(v1)을 호출하면, 교착 상태가 발생할 가능성이 있다.
교착 상태의 조건
교착 상태가 발생하려면 다음 네가지 조건이 모두 충족되어야한다.
- 상호배제 (Mutual exclusion)
스레드가 필요한 리소스에 대해 배타적 제어 권한을 주장한다. - 보유 및 대기 (Hold-and-wait)
스레드는 추가 리소스를 기다리는 동안 이미 할당된 리소스를 보유한다. - 비선점 (No preemption)
리소스는 해당 리소스를 보유한 스레드에서 강제로 제거될 수 없다. - 순환 대기 (Circular wait)
각 스레드가 체인의 다음 스레드에 의해 요청되는 하나 이상의 리소스를 보유하는 순환 체인이 존재한다.
이 네가지 조건중 하나라도 충족되지 않으면 교착상태는 발생하지 않는다. 따라서 교착상태를 예방하기 위해서 위 조건 중 하나가 발생하지 않도록 할 수 있다.
예방 방법
순환 대기
순환 대기를 유발하지 않게해서 교착상태를 예방하려면, 락을 얻을때 전체 순서를 제공해야한다. 예를 들어 시스템에 락 L1,L2가 있을 때, 항상 L1을 확득한 다음 L2를 획득하도록 해서 교착상태를 방지할 수 있다.
물론, 복잡한 시스템에서는 여러개의 락이 존재하므로 이것을 달성하기 어려울 수도 있다. 따라서 부분 순서를 이용하는 것이 유용한 방법이 될 수 있다. 이것에 대한 예는 리눅스의 메모리 매핑 코드에서 볼 수 있다.
전체 및 부분 순서는 잠금 전략을 신중하게 설계해야 하며, 매우 주의 깊게 구성해야 한다. 또한, 순서는 단지 규칙에 불과하므로 부주의한 프로그래머가 잠금 프로토콜을 무시하여 잠재적으로 교착 상태를 유발할 수 있다. 마지막으로, 잠금 순서는 코드베이스에 대한 깊은 이해와 다양한 루틴이 어떻게 호출되는지에 대한 이해가 필요다.
보유 및 대기
이 방법을 쓰기 위해 '모든 락'을 원자적으로 획득하게 한다.
1 pthread_mutex_lock(prevention); // begin acquisition
2 pthread_mutex_lock(L1);
3 pthread_mutex_lock(L2);
4 ...
5 pthread_mutex_unlock(prevention); // end먼저 prevention 락을 획득해서 락 획득중 전환이 일어나지 않게 해야지 데드락을 피할 수 있다.
하지만 이 방법은 캡슐화 때문에 문제가 될 수 있다. 루틴을 호출할 때 어떤 락이 보유되어야하는지 정확히 알아야하며, 사전에 이를 획득해야한다. 또한, 이 기술은 모든 락을 한 번에 획득하므로 필요하지 않을때도 락을 획득하여 병행성을 감소시킬 수 있다.
비선점
보통 락은 unlock이 호출될 때 까지 보유된 것으로 간주하기 때문에, 여러 락을 획득하는 것이 문제가 된다. 하나의 락을 기다리는 동안 다른 락을 보유하고 있기 때문이다.
pthread_mutex_trylock()루틴은 락을 잡고 성공을 반환하거나, 오류 코드를 반환한다.
top:
pthread_mutex_lock(L1);
if (pthread_mutex_trylock(L2) != 0) {
pthread_mutex_unlock(L1);
goto top;
}이걸 통해 deadlock을 피할 수 있지만 새로운 문제가 발생한다.
두 스레드가 이 시퀀스를 반복적으로 시도하고 두 락을 계속해서 획득할 수 있다. 코드 시퀀스를 반복하지만 진전이 없기 때문에 livelock이라고 부른다.
이에 대한 해결책도 있다. 예를 들어 전체 시퀀스를 다시 시도하기 전에 임의의 지연을 추가하여 경합하는 스레드 간의 반복적인 간섭 가능성을 줄일 수 있다.
이 해결책의 한가지 주의할 점은 trylock의 접근 방식이다. 캡슐화된 루틴안에 락 중 하나가 숨겨져 있다면 복잡해질 수 있다.
이 접근방식이 실제로 선점(preemption)을 추가하지는 않지만 trylock접근 방식을 사용해서 락 소유권을 포기하게 한다.
상호 배제
상호 배제를 없애기에는 critical section이 있다. 어떻게 해야할까? Herlihy는 잠금을 전혀 사용하지 않고도 다양한 데이터 구조를 설계할 수 있다는 아이디어를 가졌다. 하드웨어를 사용하여 락과 대기 없이 데이터 구조를 구축할 수 있다.
CompareAndSwap루틴은 하드웨어에서 제공되는 원자적인 명령어로 다음을 수행한다.
int CompareAndSwap(int *address, int expected, int new) {
if (*address == expected) {
*address = new;
return 1; // 성공
}
return 0; // 실패
}이제 일정량만큼 값을 원자적으로 증가시키고 싶다면 다음과 같이 할 수 있다.
void AtomicIncrement(int *value, int amount) {
do {
int old = *value;
} while (CompareAndSwap(value, old, old + amount) == 0);
}업데이트할 때 락을 획득하는 대신, 값을 새로운 값으로 반복적으로 업데이트하고 CompareAndSwap루틴을 사용하여 이를 수행하는 방식으로 접근했다. 이 방법으로 락을 획득하지 않고도 교착상태가 발생하지 않는다. (livelock은 여전히 가능하다.)
다음은 조금 더 복잡한 예시인, 리스트의 헤드에 삽입하는 코드이다.
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
n->next = head;
head = n;
}이 코드는 간단한 삽입을 수행하지만, 여러 스레드에서 동시에 호출되면 race condition이 발생한다. 이 문제는 코드를 락으로 둘러쌈으로써 해결할 수 있다.
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
pthread_mutex_lock(listlock); // 임계 영역 시작
n->next = head;
head = n;
pthread_mutex_unlock(listlock); // 임계 영역 종료
}이번에는 락 대신 CompareAndSwap루틴을 사용해보겠다.
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
do {
n->next = head;
} while (CompareAndSwap(&head, n->next, n) == 0);
}이 코드는 현재 헤드를 가리키도록 다음 포인터를 업데이트하고, 새로운 노드를 리스트의 새로운 헤드로 교체하려고 시도한다. 그러나 이 코드는 다음 스레드가 그 사이에 새로운 헤드를 교체한 경우 실패한다. 그리고 이 스레드는 새로운 헤드로 다시 시도하게 된다.
스케줄링을 통한 교착상태 회피
교착상태를 방지하는 것 보다 회피하는 것이 선호될 수 있다. 회피는 각 스레드가 실행 중에 어떤 락을 잡을 수 있는 지에 대한 전역적인 지식이 필요하며, 그에 따라 해당 스레드를 스케줄하여 교착상채를 회피한다.
예를 들어 스레드(T1,T2,T3,T4)와 락(L1,L2)가 있을때 다음의 상황을 가정하자

스케줄러는, T1과 T2가 L1과 L2를 요구하기에 T1과 T2가 동시에 실행되지 않으면 교착상태가 발생하지 않을 것이라고 계산할 수 있다. 따라서 T1과 T2를 같은 CPU에 넣을 수 있다.

T3는 하나의 락만 잡기에 T1이나 T2와 동시에 실행되어도 교착상태를 발생시키지 않을 것이다.
만약 T3도 L1을 잡기를 원한다면,

다음과 같이 스케줄할 것이다.

이렇게 함으로써 교착상태를 피할 수 있지만 성능에 영향을 미친다. 따라서 스케줄링을 통한 교착상태 회피는 널리 사용되는 범용 솔루션은 아니다.
감지 및 복구
교착상태가 발생하는 것을 허용한 다음, 이를 감지하여 조치를 취할 수도 있다. 단순히 운영체제가 1년에 한 번 멈춘다면 기기를 부팅해서 작업을 계속하는 것이 더 실용적일 것이다.
많은 데이터베이스 시스템은 감지 및 복구 기술을 사용한다. 교착상태 탐지기가 주기적으로 실행되며 리소스 그래프를 작성하고 사이클(deadlock)을 확인한다. 사이클이 발생하면 시스템을 다시 시작해야한다.
