1. 내장함수
- SQL에서는 함수의 개념을 사용하여 특정 값이나 열의 값을 입력받아 그 값을 계산하여결과값을 돌려줌.
- SQL의함수는 DBMS가 제공하는 내장함수(built-in function)와 사용자가 필요에 따라 직접 만드는 사용자 정의 함수(user-defined function)로 나뉨.
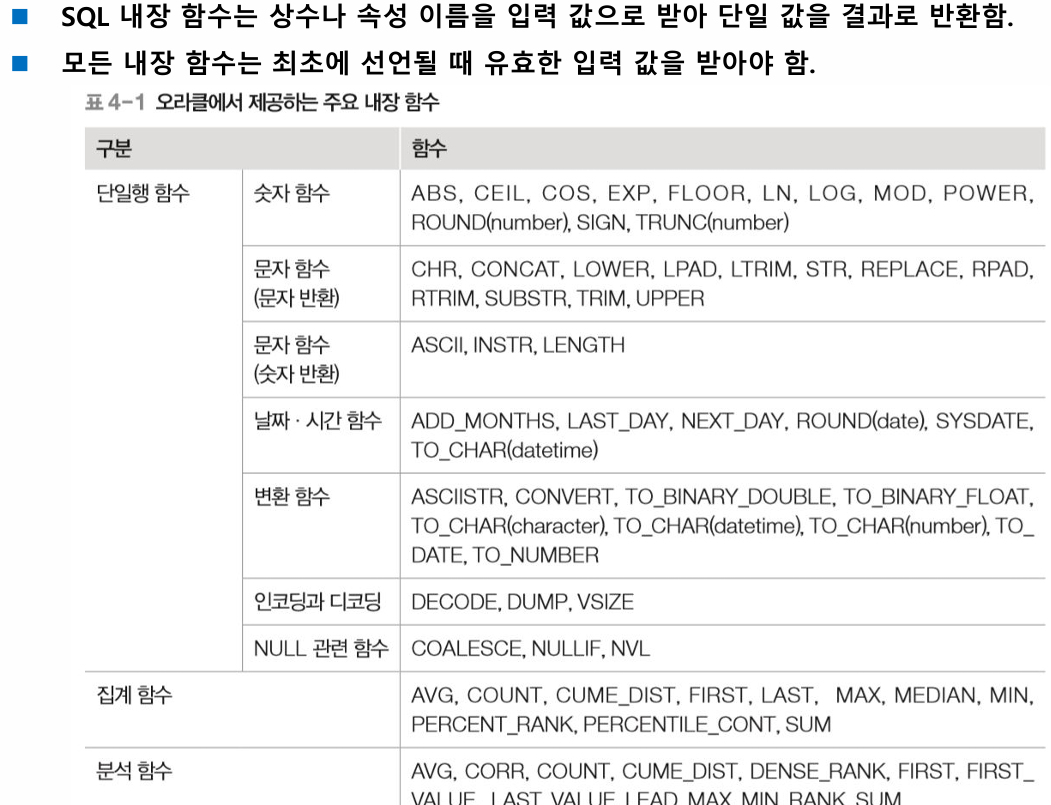
숫자함수
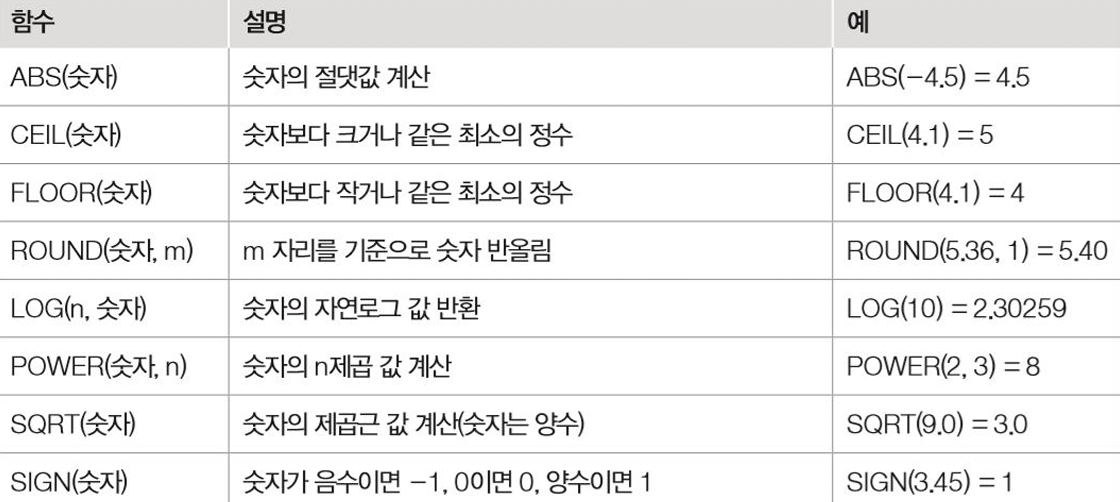

문자함수
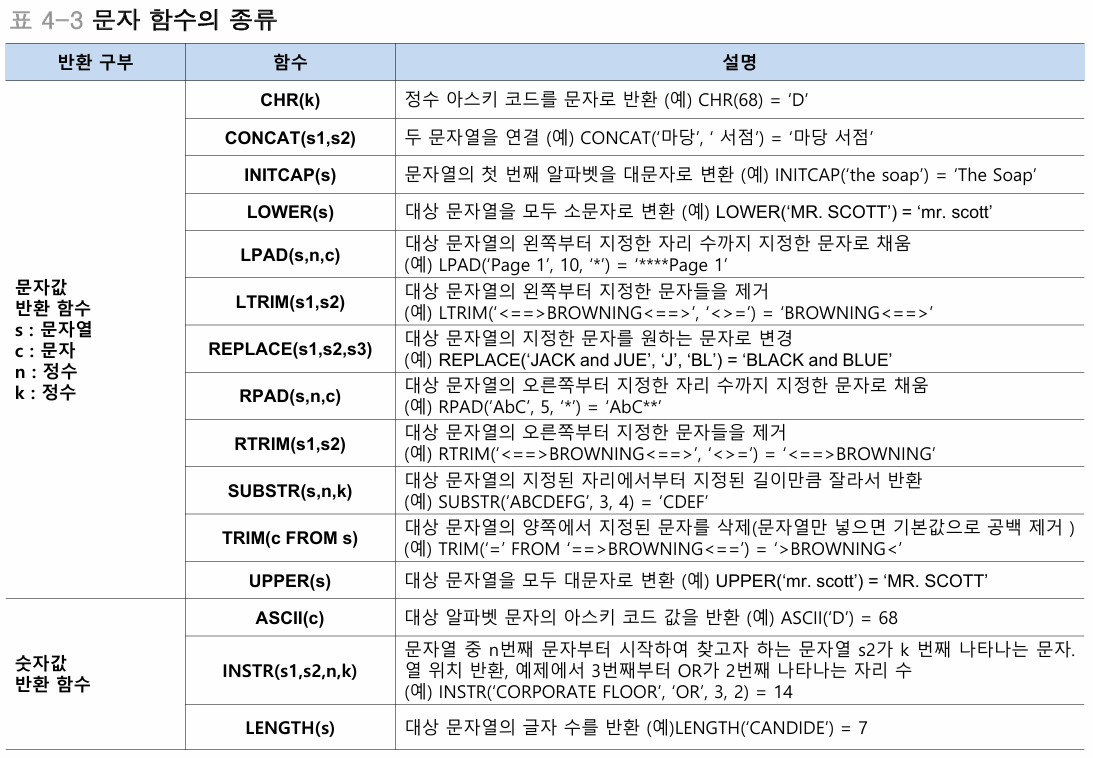
날짜,시간함수

- STSDATETIME : 오라클의 현재 날짜,시간을 반환
- SYSTIMESTAMP : 현재 날짜,시간,초 단위 시간,서버의 TIMEZONE 반환
- 예시)
- SELECT orderdate+10 FROM Orders;
- SELECT TO_CHAR(SYSDATE,'yyyy/mm/dd dy hh24:mi:ss')
2. NULL 값 처리
- NULL 이란? 아직 지정되지 않은 값! 0이나 공백('')이 아님!
- NULL 값의 산술 연산을 수행하면 결과는 NULL임
- [ + - * / ] = NULL
- [ > < = <= >= <> ] = Unknown
- [ AND OR NOT ] = True,False,Unknown
- NULL 값을 확인할 때는 '='이 아닌 'IS NULL'을 사용
- NULL 이 아님을 확일할 때는 '< >'이 아닌'IS NOT NULL'을 사용
- SELCT * FROM Mybook WHERE price IS NULL;
- NVL : NULL값을 다른 값으로 대치하여 연산하거나 출력
- SELECT NVL(phone,'연락처 없음') FROM Customer;
ROWNUM
- 내장함수는 아니지만 자주 사용되는 문법이다.
- 오라클에서 내부적으로 생성되는 가상 컬럼으로 SQL 조회 결과의 순번을 나타냄
- 자료를 일부분만 확인하여 처리할 때 유용함

2. 부속질의
- 하나의 SQL 문 안에 다른 SQL 문이 중첨된 질의
- 보통 데이터가 대량일 때 데이터를 모두 합쳐서 연산하는 조인보다 필요한 데이터만 찾아서 공급해주는 부속질의가 성능이 더 좋음
- 주질의와 부속질의로 구성됨
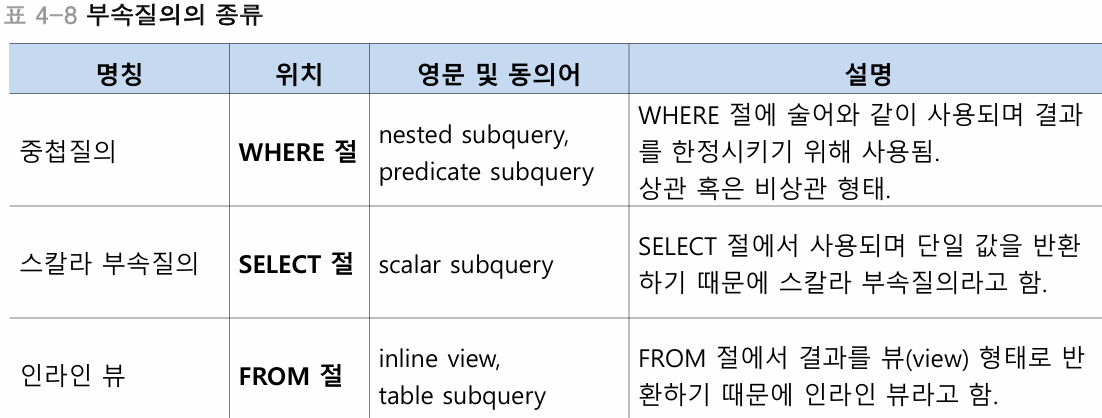
중첩질의 - WHERE 부속질의
- WHERE 절은 보통 데이터를 선택하는 조건, 술어와 같이 사용된다. 그래서 중첩질의를 술어 부속질의라고도 함
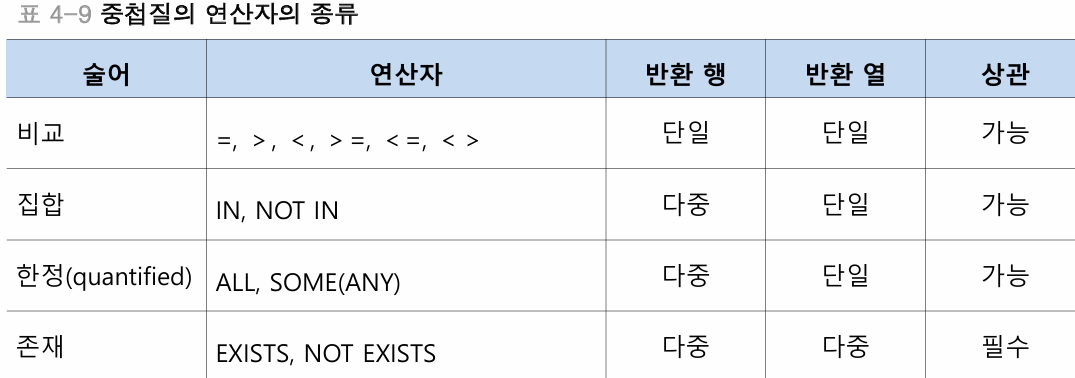
- 비교 연산자는 부속질의가 반드시 단일 행, 단일 열을 반환해야하며, 아닐경우 질의 처리 불가
- IN,NOT IN 주질의 속성값이 부속질의의 집합에 있는지 확인하는 역할
- ALL,SOME,ANY (부속질의) 로 써서 모든 또는 최소한 하나라도 해당될 시 참이된다.
- EXISTS, NOT EXISTS : 데이터의 존재 유무를 확인한다.
스칼라 부속질의 - SELECT 부속질의
- 부속질의의 결과 값을 단일 행, 단일 열의 스칼라 값으로 반환함.
- 원칙적으로 스칼라 값이 들어갈 수 있는 모든 곳에 사용가능하며, 일반적으로 SELECT 문과 UPDATE SET 절에 사용됨
인라인 뷰 - FROM 부속질의
- 테이블 이름 대신 인라인 뷰 부속질의를 사용하면 보통의 테이블과 같은 형태로 사용할 수 있음.
- 부속질의결과 반환되는 데이터는 다중행, 다중열이어도 상관없음.
- 다만 가상의 테이블인 뷰형태로 제공되어 상관부속질의로 사용될 수는없음.
3. 뷰
- 하나 이상의 테이블을 합하여 만든 가상의 테이블.
- 장점
- 편리성, 재사용성
자주 사용되는 복잡한 질의를 뷰로 미리 정의해 놓을 수 있음 - 보안성
각 사용자 별로 필요한 데이터만 선별하여 보여줄 수 있고 중요한 질의의 경우 질의 내용을 암호화 할 수 있음 - 논리적 데이터 독립성 제공
개념 스키마의 DB구조가 변하여도 외부 스키마에 영향을 주지 않도록 하는 논리적 데이터 독립성 제공
- 편리성, 재사용성
- 특징
- 원본 데이터 값에 따라 같이 변함
- 독립적인 인덱스 생성이 어려움
- 삽입, 삭제, 갱신 연산에 많은 제약이 따름
뷰의 생성
- CREATE VIEW <뷰이름(속성)> AS SELECT문
- 예시)
- SELECT * FROM Book (이것도 뷰임 , 저장을 안할 뿐)
- CREATE VIEW vw_Book AS SELECT * FROM Book
뷰의 수정
- CREATE OR REPLACE VIEW <뷰이름(속성)> AS SELECT문
- 예시)
- CREATE OR REPLACE VIEW vw_Customer(custid,name,address) AS SELECT custid,name,address FROM Customer
뷰의 수정
- DROP VIEW 뷰이름
- 예시) DROP VIEW vw_Customer;
4. 인덱스
데이터 베이스의 물리적 저장
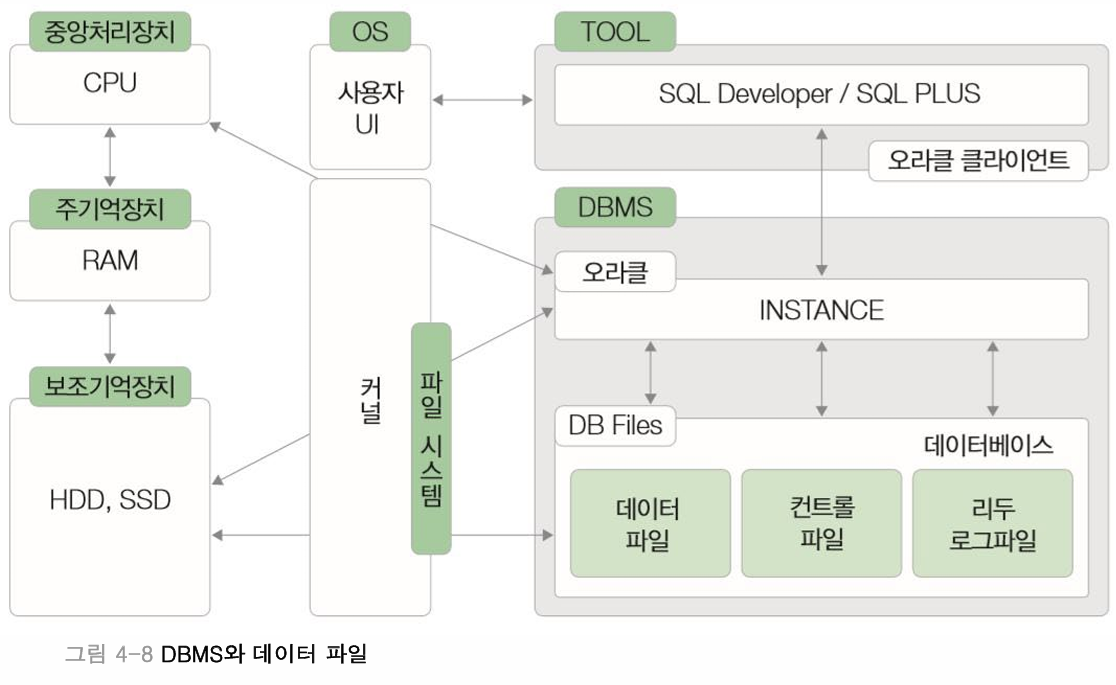
- 데이터가 저장되는 곳은 HDD,SDD,메모리 등
- 엑세스 시간 = 탐색시간 + 회전지연시간 + 데이터 전송시간

- 디스크의 데이터에 접근하는 시간은 오래걸린다. 그래서 DB에서 정보를 가져오는 횟수를 최소로 하는 것이 좋다. 데이터를 쉽고 빠르게 찾기위해 인덱스의 도움을 받을 수 있다.
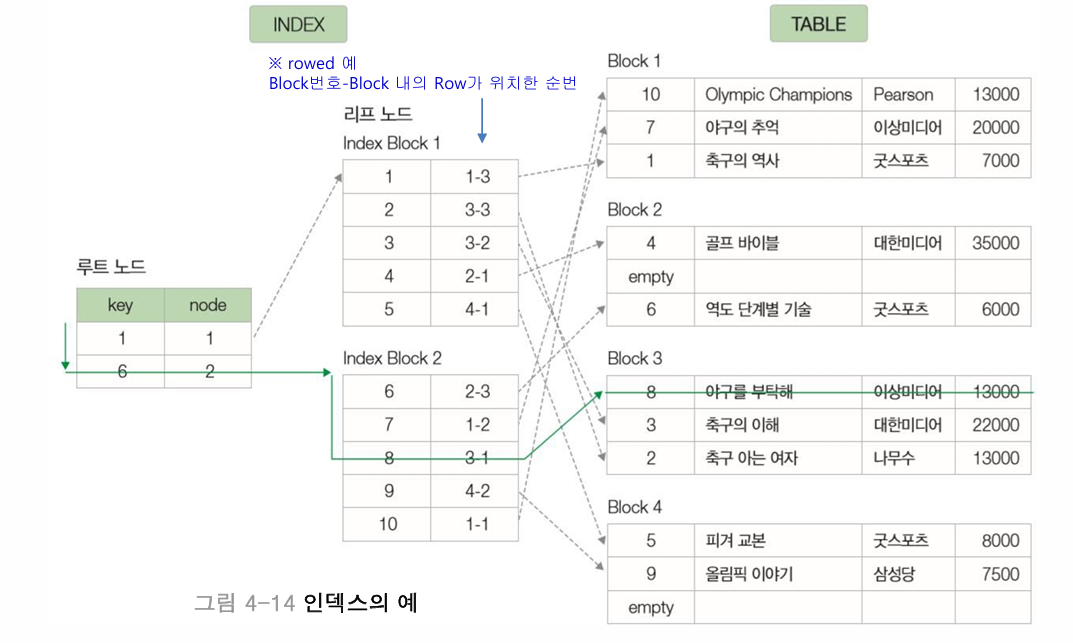
인덱스(index)와 B-Tree
-
데이터를 쉽고 빠르게 찾을 수 있도록 만든 데이터 구조
-
특징
- 인덱스는 테이블에서 한 개 이상의 속성을 이용하여 생성
- 빠른 검색, 효율적인 레코드 접근
- 순서대로 정렬된 속성과 데이터 위치만 보유하므로 테이블 보다 작은 공간 차지
- 저장된 값들은 테이블의 부분 집합
- 일반적으로 B-Tree의 구조를 가짐
- 데이터의 변경이 발생하면 인덱스의 재구성이 필요함
-
인덱스의 생성
- CREATE INDEX <인덱스이름> ON <테이블이름>;
-
인덱스의 재구성
- ALTER INDEX <인덱스이름> REBUILD
-
인덱스의 삭제
- DROP INDEX <인덱스이름>
