프로세스는 단순히 실행중인 프로그램이다. 프로그램 또한 그 자체만 놓고본다면 0과 1로 이루어진 명령어들의 집합일 뿐이다. 그리고 그 데이터들을 가져와서 프로그램을 유용한 것으로 변환 하는 것은 운영체제이다.
여러 프로그램을 동시에 실행하는 것을 상상해보라 웹브라우저와 게임, 음악 플레이어를 동시에 실행할 수 있다. 하지만 보통의 컴퓨터에서 CPU는 하나이고 CPU는 한 번에 하나의 프로그램 만을 연산 할 수 있다. 그렇다면 여러 프로그램이 동시에 실행되는 것은 어떻게 이루어지고 있는 것인가?
가상화
운영체제는 여러 프로그램을 동시에 실행시키기 위하여 마치 CPU가 여러개 있는 듯한 환상을 만든다. 이것을 가상화 virtualizing라고 한다. 가상화를 위하여 CPU는 한 프로세스를 실행후 정지하고 ,또 다른 프로세스를 실행후 정지함을 반복한다. 이렇게 프로세스의 시간을 나누는 시분할 time-sharing을 통해 여러 프로세스를 동시 실행할 수 있지만, 한 프로세스가 CPU를 사용하는 시간이 줄어들기 때문에 각각의 프로세스는 느려진다.
CPU 가상화의 구현을 위해서, 운영체제는 저수준의 장치와 고수준의 지식이 필요하다. 저수준의 장치를 메커니즘이라고 한다. 메커니즘은 필요한 기능을 구현하는 저수준의 방법이나 프로토콜이다. 예를 들어 운영체제는 시간 공유 메커니즘을 가지고있는데, 그것은 CPU에서 실행중인 프로그램을 중지하고, 다른 프로그램을 시작할 수 있는 문맥 Context 전환 메커니즘이다.
이러한 메커니즘에는 운영체제의 일부 지능이 정책(알고리즘)의 형태로 존재한다. 예를 들어 시간 공유 메커니즘에서 다른 프로그램을 실행시킬때, 어떤 프로그램을 실행시킬지에 대한 정책이다. 이것을 결정하기 위해 운영체제는 과거정보, 부하정도, 성능지표 등을 고려하여 결정한다.
많은 운영체제는 고수준의 정책을 저수준의 메커니즘으로 분리한다.
이로써, 정책은 쉽게 변경 가능해지고,
메커니즘을 생각해야하는 번거로움을 줄일 수 있다.
이것은 일반적인 소프트웨어 디자인 원칙의 한 형태인 '모듈성'이다.운영체제가 제공하는, 실행중인 프로그램의 추상화를 프로세스라고 한다. 앞에서 언급한대로, 프로세스는 단순히 실행중인 프로그램이다. 프로세스를 구성하는것이 무엇인지 이해하기 위해, 프로세스의 기계 상태를 이해해야한다.
그 중 한 가지는, 메모리이다. 프로그램의 명령어들과 데이터들은 메모리에 있으며, 따라서 프로세스가 주소를 지정할 수 있는 메모리(주소공간)은 프로세스의 일부이다.
다음은 레지스터이다. 많은 명령어가 레지스터를 읽고 업데이트 하기에 프로세스의 일부라 할 수 있다. 예를 들어 프로그램 카운터(PC)는 다음에 실행할 프로그램의 명령을 알려준다. 스택 포인터와 프레임 포인터 또한 함수 매개변수, 지역변수, 반환주소를 관리하는데 사용된다.
마지막으로, 영속적인 저장장치(하드디스크나 SSD)도 포함된다. 입출력 정보에는 프로세스가 현재 열어 놓은 파일 목록(file descripter)이 포함될 수 있다.
프로세스 API
운영체제의 인터페이스에 포함되어야 할 내용에 대해 간단히 소개한다. 운영체제가 반드시 제공해야하는 기능은 다음과 같다.
- 생성 Create
운영체제는 새로운 프로세스를 생성하기 위한 방법이 있어야 한다. 프로그램을 실행 할 때, 새로운 프로세스를 생성하기 위해 운영체제가 호출된다. - 소멸 Destroy
프로세스를 강제로 소멸 시키는 방법도 있어야 한다. 프로세스는 스스로가 완료될 때 종료되겠지만, 사용자가 프로세스를 중지시키기를 원할 경우 이를 위한 인터페이스가 필요하다. - 대기 Wait
프로세스가 실행을 멈출때 까지 기다리는 것도 필요하다. - 기타 제어 Miscellaneous Control
기타제어의 예로, 운영체제는 프로세스를 일시 중지하고 다시 시작할 수 있는 방법을 제공한다. (예를 들어 control+C를 누르면 프로그램이 종료된다. 프로그램상에 따로 구현하지 않아도 운영체제가 해주기 때문에 동작한다.) - 상태 Status
프로세스에 대한 상태 정보를 얻을 수 있는 인터페이스가있다면 유용할 것이다. 프로세스가 실행된 시간이다. 메모리 사용률과 같은 정보를 얻을 수 있다.
프로세스의 생성
운영체제가 프로그램을 시작하고 프로세스를 만드는 것은 실제로 어떻게 동작할까?
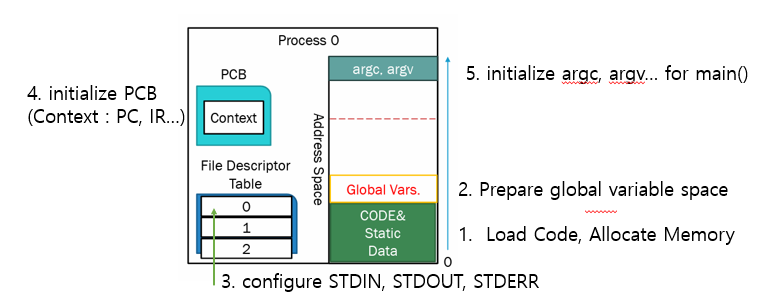
프로그램은 영속적 저장이 가능한 저장장치(HDD 나 SSD)에 저장되어 있다. 운영체제는 이 저장장치에서 프로그램에 대한 코드와 정적 데이터를 메모리로 Load 해야한다.
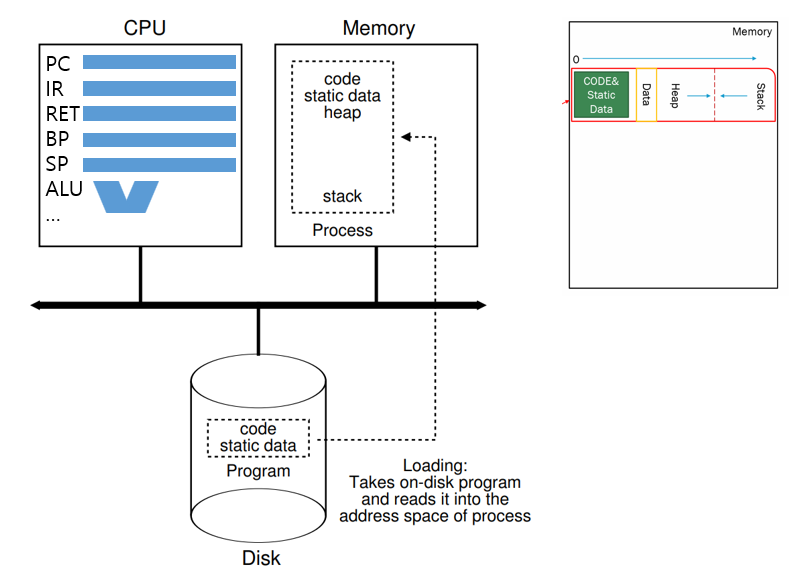
CPU를 레지스터의 값들은 프로세스에 맞춰서 재설정 된다. 대표적으로 현재 명령을 나타내는 PC(Program Counter), 명령어를 잠시 보관해두는 IR(Instruction), 함수 호출 후 돌아올 곳을 저장하는 RET(return from procedure), 지역변수와 인자(args,argv)사이의 값인 BP(Base Pointer), Stack Top 을 알려주는 SP(Stack Pointer), 함수 호출 전의 SP위치를 알려주는 FP(Frame Pointer) 등이 있다.
운영체제는 프로그램의 힙 Heap에도 일부 메모리를 할당할 수 있다. 예로 C 프로그램에서 힙은 명시적으로 요청된, 동적으로 할당된 데이터에 사용된다. 명시적으로 malloc()을 호출하여 공간을 요청하고, free()를 호출하여 해제한다. 프로그램이 malloc()라이브러리 API를 통해 메모리를 요청할 때, 운영체제는 프로세스에 메모리를 더 할당하여 호출을 충족시킨다.
운영체제는 입출력 설정과 관련된 초기화 작업도 수행할 수 있다. 예로 UNIX 프로그램에서 각 프로세스는 표준입출력 및 오류에 대한 세 개의 열린 파일 설명자가 있다. 이것을 통해 프로그램은 입출력을 할 수 있다. 데이터 지속성에 대한 부분에서 더 자세히 알아보도록 하겠다.
이렇게 데이터를 메모리로 로드하고, 스택을 생성하고, 초기화 하고, 입출력 설정등 기타 작업을 수행함으로써, 운영체제는 프로그램 실행 준비를 마쳤다. 이제 마지막 작업인 main()으로 이동을 한다. main()루틴으로 이동함으로써 운영체제는 새로운 프로세스로 CPU의 제어를 전달하고 프로그램이 실행된다.
이전의 운영체제들은 로딩 프로세스 Loading Process를 즉시 수행하였다.
프로그램이 실행되기 전에 로딩을 다 해놓는다는 말이다.
하지만, 최근의 운영체제는 프로그램 실행중에 필요할때 마다,
코드나 데이터 조각을 로드하는 방식(Lazily 방식)을 사용한다.
이를 자세히 알기 위해서는 페이지 Page와 스왑 Swap에 대해 알아야한다.프로세스 상태
프로세스는 다음과 같은 세 가지 상태중 하나에 있을 수 있다.
- 실행 Running
프로세스는 프로세서에서 실행된다. 즉, 명령을 실행 중인 것이다. - 준비 Ready
프로세스는 실행 준비가 되어 있지만, 운영체제가 실행하지 않는 상태이다. - 차단 Blocked
프로세스는 다른 이벤트가 발생할 때까지 준비 상태가 되지 않을 수 있다.
예로 프로세스가 디스크에 I/O요청을 하면 차단되어 다른 프로세스가 프로세서를 사용할 수 있다.
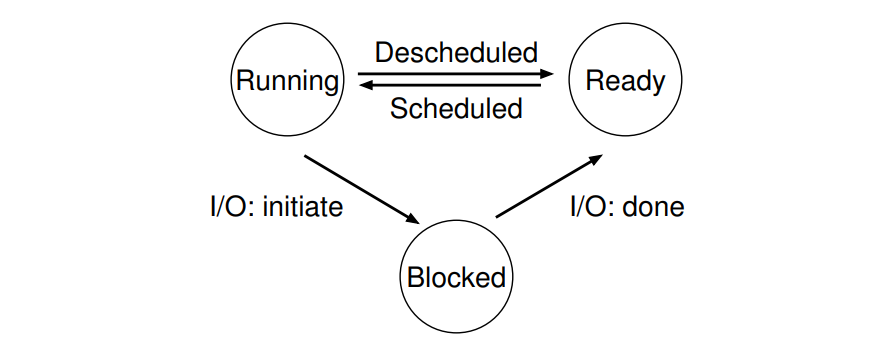
프로세스는 운영체제에 따라 상태가 변경될 수 있다. 준비에서 실행으로 이동하면 프로세스는 스케줄링 된것을 의미하며, 반대는 비스케줄링 된 것이다. 한 번 프로세스가 차단되면(I/O 시작), 운영체제는 이벤트(I/O 완료)가 발생할 때까지 그 상태를 유지한다. 그 후에 프로세스는 준비상태가 되며 다시 실행된다. 아래 사진은 두 개의 프로세스가 실행중 일 때의 상태 추적이다.

데이터 구조
운영체제 또한 하나의 프로그램이며, 관련 정보를 추적하는 핵심 데이터 구조가 있다.
예를 들어, 각 프로세스의 상태를 추적하기 위해 운영체제는 프로세스 목록을 유지하고 프로세스들을 추적할 것이다. 차단된 프로세스는 준비 생태로 이동하기 위해 운영체제가 추적할 것이다.
프로세스에 대한 정보를 저장하는 구조를 프로세스 제어 블록(PCB:Process Controll Block)(프로세스 기술자)라고 한다. 이것은 각 프로세스에 대한 정보를 포함하는 C 구조체에 대해 얘기하는 방식이다.
아래 코드는 xv6커널에서 각 프로세스에 대해 추적해야하는 정보 유형을 보여준다. 운영체제가 프로세스에 대해 추적하는 정보 몇 가지가 있다.
레지스터 context는 중지된 프로세스의 레지스터 내용이다. 프로세스가 중지되면 해당 레지스터가 이 메모리 위치에 저장된다. 이 값들을 실제 레지스터에 다시 넣음으로써, 프로세스 실행을 계속 할 수 있다. 이것을 context 전환이라고 한다.
또, 프로세스가 있을 수 있는 상태에 실행,준비,차단 이외에도 다른 것들이 있을 수 있다.
// 프로세스를 중지하고 이후에 다시 시작하기 위해 xv6가 저장하고 복원할 레지스터
struct context {
int eip; // 인스트럭션 포인터
int esp; // 스택 포인터
int ebx; // 베이스 레지스터
int ecx; // 카운터 레지스터
int edx; // 데이터 레지스터
int esi; // 소스 인덱스 레지스터
int edi; // 대상 인덱스 레지스터
int ebp; // 베이스 포인터 레지스터
};
// 프로세스가 존재할 수 있는 다양한 상태
enum proc_state { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// 각 프로세스에 대한 xv6가 추적하는 정보
// 레지스터 컨텍스트와 상태를 포함
struct proc {
char *mem; // 프로세스 메모리의 시작
uint sz; // 프로세스 메모리의 크기
char *kstack; // 이 프로세스에 대한 커널 스택의 맨 아래
enum proc_state state; // 프로세스 상태
int pid; // 프로세스 ID
struct proc *parent; // 부모 프로세스
void *chan; // 0이 아닌 경우, chan에서 슬립 중
int killed; // 0이 아닌 경우, 죽음 상태
struct file *ofile[NOFILE]; // 오픈된 파일들
struct inode *cwd; // 현재 디렉토리
struct context context; // 여기서 프로세스를 실행하려고 전환합니다
struct trapframe *tf; // 현재 인터럽트에 대한 트랩 프레임
};