스케줄러의 또 하나의 비교 기준인 Fairness(형평성)을 중점으로 비례 배분 proportional share 스케줄러에 대해 알아보자 형평성을 고려하면 전환 시간과 응답 시간을 최적화 하는 대신 각 작업이 CPU 시간의 특정 비율을 확보하도록 보장할 수 있다. 과거의 복권(lottery) 스케줄링은 일정 간격마다 복권을 뽑아 다음 프로세스를 결정했다. 시간이 많이 필요한 프로세스는 복권을 더 줬다. 우리는 어떤 방법을 사용해야지 CPU를 형평성 있게 분배할 수 있을까?
Tickets Represent Your Share 점유율을 나타내는 티켓
복권 스케줄링의 기본 개념은 티켓이다. 티켓은 프로세스가 받아야하는 자원의 비율을 나타낸다. 프로세스가 가진 티켓의 비율은 해당 시스템 자원의 점유율을 나타낸다.
예를 들어 프로세스 A,B 는 각각 티켓 75,25개를 가지고 있다. 따라서 우리가 원하는 것은 A가 CPU의 75%를 점유하고, B가 나머지 25%를 점유하는 것이다.
복권 스케줄링은 주기적 또는 확률적으로 복권을 연다. 0부터 99까지 100개의 티켓중 무엇이 선택되냐에 따라 다음 프로세스의 실행이 결정된다. 이는 확률적으로 결정되기에 원하는 비율이 되지 않을 수 있지만 오래 수행하여 원하는 확률에 수렴하게 할 수 있다.
Ticket Mechanisms 티켓 메커니즘
복권 스케줄링은 티켓을 관리할 수 있는 메커니즘을 제공한다.
첫 번째는 ticket currency,티켓을 통화(화폐)처럼 사용하는 것이다.
통화는 티켓을 가진 사용자가 자신의 작업에서 티켓을 원하는 대로 할당할 수 있게 한다. 그런 다음 시스템은 해당 통화를 글로벌 값으로 자동 변환한다.
예를 들어 사용자 A,B가 각각 100개의 티켓을 받았다고 가정해보자
A 는 A1,A2의 두 개의 작업을 실행하고 각각 1000개의 티켓 중 500개씩 할당한다.
B는 B1의 한 작업을 실행하고 10개의 티켓을 할당한다. 그러면 시스템은 A의 할당을 50개의 글로벌 통화로 변환하고 B의 할당을 100개의 글로벌 통화로 변환한다.
그런다음 A 100개, B 100개 총 200개의 글로벌 통화에 대한 복권이 진행된다.
두 번째는 ticket transfer,티켓을 전송하는 방법이다. 예를 들어 어떤 프로세스가 티켓이 너무 많아 바쁜 프로세스에게 티켓을 넘겨 주는 것이다. 이것은 클라이언트-서버 메커니즘에서 유용하다. 보통 서버가 바쁘므로 서버에게 티켓을 넘기고 작업이 끝나면 다시 돌려준다.
세 번째는 ticket inflation, 인플레이션을 사용하여 프로세스가 소유하는 티켓 수를 일시적으로 조절할 수 있다. 이것은 프로세스간 경쟁이 없어야 작동한다. 본인에게 티켓을 많이 줘서 시스템을 장악할 수 있기 때문이다.
Implementation 구현
복권 스케줄링은 구현이 단순하다. 필요한 것은 당첨을 위한 난수 생성기, 프로세스 추적하는 데이터 구조(목록같은 것), 총 티켓 수 이다.
예를 들어 프로세스 목록에 티켓을 가진 프로세스 A,B,C가 있다고 해보자 스케줄링을 위해 총 티켓수(400개)에서 랜덤한 숫자를 정해야한다. 300이라고 가정하면 목록을 순회하며 당첨자를 찾기 위해 카운터를 사용한다.
// used to track if we’ve found the winner yet
int counter = 0;
// call some random number generator to
// get a value >= 0 and <= (totaltickets - 1)
int winner = getrandom(0, totaltickets);
// use this to walk through the list of jobs
node_t *current = head;
while (current) {
counter = counter + current->tickets;
if (counter > winner)
break; // found the winner
current = current->next;
}
// ’current’ is the winner: schedule it...
코드는 프로세스 목록을 순회하며 각 티켓 값을 카운터에 추가한다. 이때 카운터 값이 당첨자 보다 커지면 현재 목록 요소가 당첨자이다. 예를 들어 A를 지나면 100, B를 지나면 150, C를 지나면 400이므로 300을 넘어 C가 당첨자이다. 이 프로세스를 효율적으로 만들기 위해 티켓이 많은 순으로 정렬하는 것이 좋다.

An Example 예시
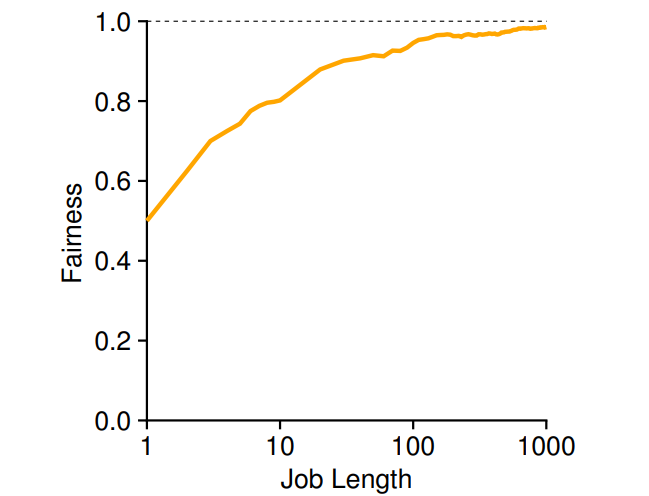
이제 복권 스케줄링을 형평성 관점에서 보자 두 프로세스 A,B는 같은 수의 티켓(100개)와 동일한 실행 시간을 가진다. 형평성을 정량화하기 위해 지표 F를 정의하자 이것은 첫 번째 작업이 완료된 시간을 두 번째 작업이 완료된 시간으로 나눈 것이다. 예를 들어 A가 10 B가 20 걸렸다면 F==0.5이다. A,B가 거의 동시에 끝났다면 F는 1에 가까울 것이다. 따라서 우리의 목표는 F를 1로 만드는 것이다.
아래 그래프는 작업 길이에 따른 형평성을 나타낸다. 작업 길이가 길어질수록 형평성이 늘어난다.
How To Assign Tickets? 복권 할당 방법
한 가지 접근 방식은 사용자가 가장 잘 안다고 가정하는 것이다. 이 경우, 각 사용자에게 일부 티켓이 주어지고 사용자가 원하는대로 프로세스에 티켓을 할당할 수 있다. 하지만 정답은 없다. 열린결말이다..
Stride Scheduling
무작위로 뽑는 방식은 짧은 시간동안에서는 형평성을 제공하지 못할 수 있다. 그래서 나온것이 Stride 스케줄링이다.
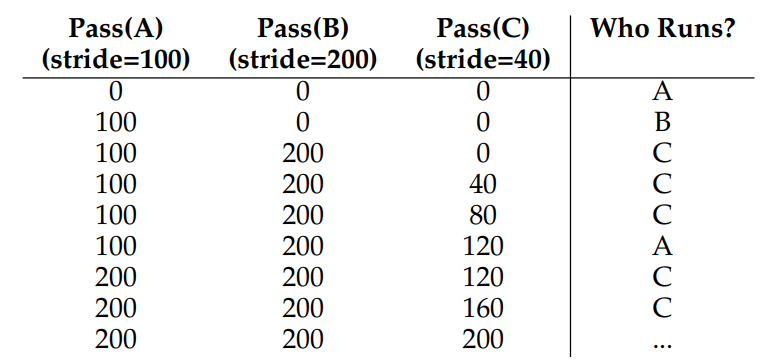
각 프로세스는 티켓 수에 반비례하는 Stride를 갖는다. 예를 들어 프로세스 A,B,C가 티켓 100,50,250개를 할당받았다고 하자, 각 티켓 수로 어떤 큰 수를 나누면 Stride값이 된다. 예를 들어 10,000을 큰 값이라고 하면 Stride는 각각 100,200,40이다. 프로세스가 실행될 때마다 스트라이드 만큼 카운터를 증가시켜 전역 진행 상황을 추적한다.
그 다음 스케줄러는 stride와 pass를 사용하여 다음 프로세스를 정한다. 가장 낮은 pass 값의 프로세스를 정하고 프로세스를 실행하면 pass 카운터를 stride 만큼 증가시킨다.
curr = remove_min(queue); // 최소 통과 클라이언트 선택
schedule(curr); // 양자에 대해 실행
curr->pass += curr->stride; // 스트라이드를 사용하여 통과 업데이트
insert(queue, curr); // curr를 대기열에 반환
위의 A,B,C에서 pass 값이 모두 낮으니 A,B,C 순서로 실행된다고 해보자 A가 실행되면 A의 pass 값이 100이 된다. B는 200, C는 40이 된다. 그 다음은 가장 낮은 pass 값인 C를 실행하며 pass값을 80으로 업데이트한다. 또, C-120, A-200, C-160, C-200 이제 모든 프로세스의 pass값이 같아지며 이 과정을 반복한다.
Stride 스케줄링에서 새로운 프로세스가 들어올 때나 pass 값이 0인 상황에서는 한 프로세스가 CPU를 독점할 수도 있다.
The Linux Completely Fair Scheduler (CFS) 리눅스 방법
리눅스에서는 좀 다른 방식으로 형평성을 만족시킨다. 그것은 Completely Fair Scheduler(CFS) 스케줄링이다. CFS 는 스케줄링 결정을 하는데 매우 적은 시간을 소요하고 싶다. 이것은 설계와 데이터 구조의 훌륭함으로 이루어진다.
Basic Operation 기본 작동
앞선 스케줄러들은 고정된 시간조각을 기반으로 하고 있지만 CFS는 모든 프로세스에게 CPU를 공정하게 나눈다. 이것을 가상 실행 시간(virtual runtime-vruntime)이라고 하는 간단한 카운팅 기반 기술을 사용하여 수행한다.
각 프로세스가 실행될 때마다 vruntime이 누적된다. 기본적으로는 각 프로세스의 vruntime이 실제 시간에 비례하여 동일하게 증가한다. 스케줄링 결정을 하기 위해서 가장 낮은 vruntime을 가진 프로세스를 선택한다.
하지만 시간 조각이 없는 스케줄러가 현재 프로세스를 멈추고 다음 프로세스를 실행할 시점을 어떻게 알 수 있을까? CFS는 다양한 매개변수를 통해 이를 관리한다.
첫 번째는 sched latency,예정된 지연 시간이다. CFS는 이 값을 사용하여 프로세스의 동작 시간을 결정한다. 일반적인 지연 시간 값은 48ms이다. CFS는 이 값을 실행중인 프로세스의 수로 나누어 시간 조각을 결정한다. 예를 들어 4개의 프로세스는 12ms씩 실행된다.
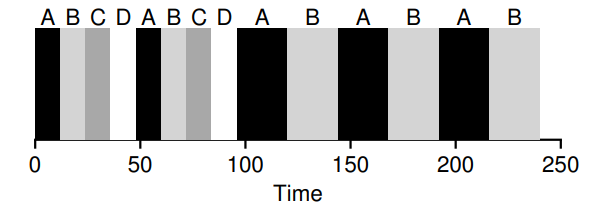
또, 여기에 min granularity, 최소 정밀도라는 다른 매개변수를 추가한다. CFS는 프로세스의 시간 조각을 이 값보다 작게 설정하지 않아 컨텍스트 스위칭에 많은 자원을 쓰지 않게 한다. 예를 들어 각 시간 조각이 4.8ms로 결정되었다면 최소 정밀도로 인해 6ms로 설정된다. 이렇게하면 형평성은 떨어지지만 효율이 좋아진다.
CFS는 주기적 타이머 인터럽트를 사용해서 고정 시간 간격에서만 결정을 내릴 수 있다. 이 인터럽트는 자주 발생하며(예로 1ms), CFS에게 현재 작업을 확인하는 기회를 제공한다. 프로세스의 시간조각이 타이머 인터럽트의 완벽한 배수가 아니어도 괜찮다. CFS는 vruntime을 정확하게 추적하므로 장기적으로 CPU 이상적인 공유에 가까워질 것이다.
Weighting (Niceness) 가중치
CFS는 프로세스 우선 순위를 조절하여 CPU의 더 높은 비중을 할당할 수 있게 한다. 이것은 프로세스의 nice 수준이라는 UNIX 메커니즘을 통해 수행한다.
nice 매개변수는 프로세스에 대해 -20 부터 19 까지 설정할 수 있으며 기본값은 0이다. nice 값이 낮을 수록 우선순위가 높다.
CFS는 각 프로세스의 nice값에 따라 가중치를 매핑한다. 다음과 같이 정의된 가중치 배열을 사용한다.
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};이런 가중치를 사용하여 각 프로세스의 유효한 시간 조각을 계산할 수 있다.
우선 순위 차이를 고려하기 위해 사용되는 공식은 다음과 같다.
n개의 프로세스를 가정하면,
예를 들어 A,B 두 프로세스에서 A의 nice 값은 -5 B의 nice 값은 기본 0이다. 따라서 테이블에서 weightA는 3121이고, weightB는 1024이다.각 시간조각을 계산해보면, 대략 A의 시간조각은 sched latency의 , 즉 36ms 이고 B가 그 나머지 12ms이다.
CFS가 vruntime을 계산하는 공식도 있다.
실제 실행 시간을 가중치의 역수를 곱해구한다. 위의 예제에서 A의 vruntime은 B의 것의 속도로 누적될 것이다.
가중체 테이블의 훌륭한 점은 nice 값의 차이가 일정할 때 CPU 비율이 보존된다는 것이다.
예를 들어, A의 nice가 5이고 B의 nice가 0이라면 CFS는 이전과 동일한 비율로 진행할 것이다.
Using Red-Black Trees 레드-블랙 트리 사용
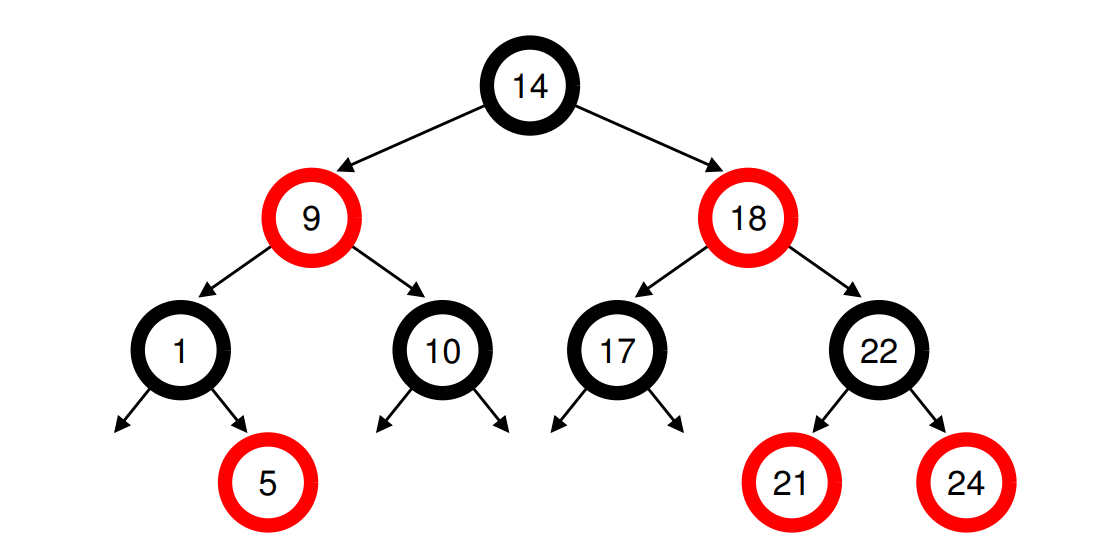
CFS의 주요 초점 중 하나는 효율성이다. 다음 프로세스를 빨리 정하는 것이다. 목록과 같은 간단한 데이터 구조는 확장되지 않는다. 현대 시스템은 매우 많은(몇 천개) 프로세스로 구성되어 있으며, 몇 밀리초마다 목록을 검색하는 것을 낭비이다. 따라서 CFS는 프로세스를 레드-블랙 트리에 보관한다.
레드-블랙 트리는 단순한 이진 트리와 달리 균형이 잡혀있어, 낮은 깊이를 유지하므로 연산이 로그 시간,비선형을 유지한다. CFS는 모든 프로세스를 이 구조에 넣지 않고 실행중인(run),실행할(ready) 프로세스만 넣는다.
예를 들어, 10개의 프로세스가 있고 이들의 vruntime 값이 1,5,9,10,14,18,17,2,1,22,24 이다.
다음 프로세스를 찾기 위해 첫번째 요소를 제거하기만 하면 된다. 여기서 대부분의 작업은 O(logn)의 시간이 걸리므로 선형,O(n)보다 효율적이다.
Dealing With I/O And Sleeping Processes 입출력과 슬립 프로세스 처리
다음에 실행할 가장 낮은 vruntime을 선택하는 것의 문제는 장기간 슬립 상태에 있는 프로세스에서 발생한다. 연속으로 실행되는 프로세스 A와 슬립 상태(예를 들어 10초)에 있는 프로세스 B를 생각해보라 B가 깨어나면 vruntime은 A보다 10초 뒤에 있으므로 CPU를 그동안 독점하게 된다.
이것을 해결하기 위해 vruntime을 변경한다. B가 깨어나면 vruntime을 트리에서 찾은 최소 값으로 변경한다. 이를 통해 기아상태를 방지한다. 하지만 CPU의 형평성이 깨질 수 있다.
