운영체제 스케줄링 정책을 개발하기 위해서 고려해야할 사항들에 대해 알아보자
Workload Assumptions 작업부하 가정
스케줄링 정책을 개발하기 위해 프로세스에 대해 몇가지 가정을 해보자 이것을 작업 부하 Workload라고 하며 작업부하를 결정하는 것은 정책을 개발하는데 아주 중요하다.
모든 작업에 대한 가정은 다음과 같다.
1. 동일한 시간 동안 실행된다.
2. 동일한 시간에 도착한다.
3. 한 번 시작하면 반드시 끝이 난다.
4. CPU만 사용한다. (입출력 수행 X)
5. 실행시간이 알려져있다.
이 가정들은 실제로는 매우 비현실적이다. 처음부터 실제 workload를 생각하면 너무 어렵기에 간단하게 만들기 위해서 위의 가정들을 한 것이다.
이 비현실적인 가정들을 하나씩 현실적으로 바꿔가며, 우리가 선택할 수 있는 스케줄링 정책들에 대해 알아보자
Scheduling Metrics 스케줄링 지표
workload 에 대한 가정이외에도, 서로 다른 스케줄링 정책을 비교할 수 있게 해주는 스케줄링 지표 Scheduling Metric가 있다.
성능 지표 중 하나인 회전 완료 시간(turnaround time)가 있다. 회전 완료 시간은 해당 작업이 완료된 시간에서 해당 작업이 시스템에 도착한 시간을 뺀 것이다.
모든 작업이 동일한 시간에 도착한다고 가정했으므로, 이고, 가 된다.
또 다른 지표는 형평성 fairness이다. 형평성은 프로세스들의 완료 시간이 얼마나 비슷한지 비교하는 기준이다. 완료 시간이 차이가 많이 난다면 좋지 않은 스케줄러라고 볼 수 있다
성능과 형평성은 스케줄링에서 종종 상충된다. 스케줄러가 성능을 최적화 할 수 있지만, 다른 작업이 실행되지 못하도록 하여 형평성을 감소시킬 수 있다.
First In, First Out (FIFO) 선입선출
우리가 구현할 수 있는 가장 기본적인 알고리즘은 FIFO 스케줄링이다. (FCFS:First Come, First Served 라고도 알려짐)
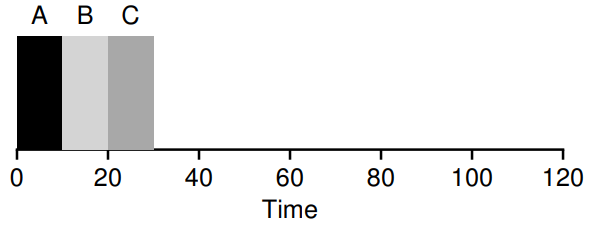
예를 들어, 시스템에 A,B,C라는 작업이 같은 시간에 도착했고(), 완료되는데 필요한 시간이 모두 10초라고 해보자
A는 0초에 도착,0초에 시작,10초에 완료된다.
B는 0초에 도착,10초에 시작,20초에 완료된다.
A는 0초에 도착,20초에 시작,30초에 완료된다.
세 작업의 평균 회전 완료 시간(turnaround time)은 이다.
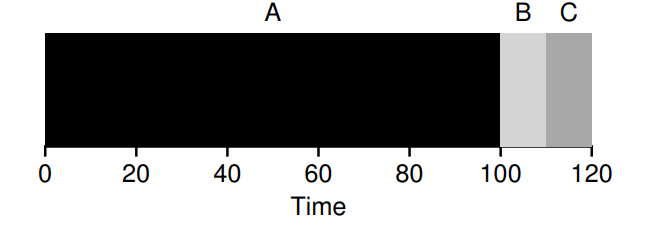
이제 가정 1을 각 작업이 동일한 시간동안 실행되지 않는다고 해보겠다. A의 실행시간을 100초로 가정하면,
A는 0초에 도착,0초에 시작,100초에 완료된다.
B는 0초에 도착,100초에 시작,110초에 완료된다.
A는 0초에 도착,110초에 시작,120초에 완료된다.
세 작업의 평균 회전 완료 시간(turnaround time)은 이다.
이렇게 FIFO에서는 시간이 많이 필요한 작업이 먼저 실행되면 빨리 끝날 수 있는 작업이 실행되지 못한다. 이런 단점을 convoy effect라고 한다.
Shortest Job First (SJF) 최단 작업 구성
FIFO의 단점을 해결하는 방법인 Shortest Job First(SJF) 가 있다. SJF는 가장 짧은 작업 순으로 진행하는 방법이다.
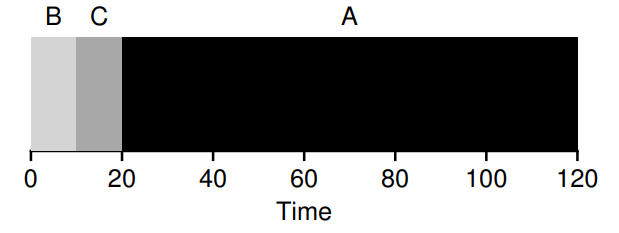
위의 예제를 다시 살펴보자 SJF 는 B,C,A 순으로 실행시키므로
B는 0초에 도착,0초에 시작,10초에 완료된다.
C는 0초에 도착,10초에 시작,20초에 완료된다.
A는 0초에 도착,20초에 시작,120초에 완료된다.
세 작업의 평균 회전 완료 시간(turnaround time)은 이다.
FIFO에 비해 두 배 이상의 개선을 이루어낸 것이다.
SFJ는 모든 작업이 동시에 도착할 때, 최적의 알고리즘 일것이지만, 이 가정은 비현실적이다.
가정 2를 모든 작업은 언제든지 도착할 수있다고 해보겠다. 이제 어떤 문제가 발생할까?
B와 C는 A보다 조금만 늦게 도착해도 A의 실행을 기다려야한다.
B와 C의 도착시간을 10초라고 한다면, 세 작업의 평균 회전 완료 시간(turnaround time)은 이다.
PREEMPTIVE SCHEDULERS 선점적 스케줄러
과거의 일괄처리 컴퓨팅, 비선점적 스케줄러는 새 작업을 실행할지 여부를 고려하기 전에 각 작업을 완료할 때까지 실행했다.
하지만 현대의 선점적 스케줄러는 다른 작업을 실행하기 위해 하나의 프로세스를 중지시킨다.
이는 스케줄러가 이전의 메커니즘을 사용한다는 것이고, 특히 컨텍스트 전환을 할 수 있다는 것이다.Shortest Time-to-Completion First (STCF) 완료까지 최단 시간 우선
가정 2를 변경하여 생긴 문제는 가정 3을 변경하여 해결할 수 있다. 가정 3을 작업 중간에 중단 시킬 수 있다고 변경해보자 그렇다면 B와 C가 도착하기 전에 A를 실행시키다가 A를 중단,B와 C를 실행시키면 된다. 이전에 알게된 타이머 인터럽트와 컨텍스트 전환을 생각하면, 스케줄러는 분명 이를 할 수 있다.
SJF에 선점 기능을 추가한 STCF 또는 PSJF(Preemptive Shortest Job First) 가 있다. STCF는 시스템에 새로운 작업이 들어 올 때 마다,남은 작업 중 남은 시간이 가장 적은 작업을 결정하고 해당 작업을 예약한다.
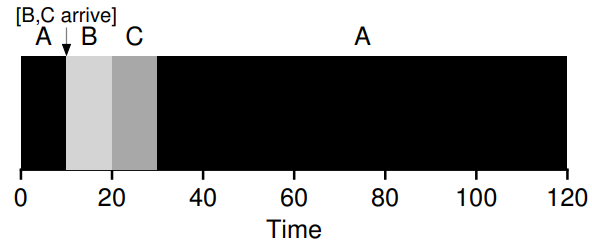
STCF 스케줄러를 사용했을때, 세 작업의 평균 회전 완료 시간(turnaround time)은 이다.
A New Metric: Response Time 새로운지표:응답시간
과거의 일괄처리 시스템(batching system)에서는 STCF가 좋은 방법이 될 수도 있다. STCF는 완벽한 정책처럼 보이지만 아직 비현실적인 가정이 남아있다.
현대의 컴퓨터는 시분할 기법을 사용하며, 여러개의 프로그램을 동시에 작동시킨다. 사용자들은 터미널로부터 상호작용을 원하며 성능을 요구한다. 이에 따라 사용자의 요구에 따른 응답시간이 중요하게 되었고 이는 새로운 지표가 되었다.
응답시간은 작업이 시스템에 도착한 시점에서 처음으로 예약된 시간으로 정의한다.
세 작업 A,B,C가 각각 0,10,10초에 도착했다면, 각각의 응답시간은 0,0,10초이다. (평균은 3.33)
이것은 마우스를 움직인지 5초만에 반응하고, 키보드 타이핑이 10초 뒤에 입력되는 것과 같다.
Round Robin (RR)
응답 시간을 줄이기 위해 Round Robin(RR) 스케줄링을 사용할 수 있다. RR은 작업을 정해진 시간 만큼 실행한 뒤 다음 작업으로 전환한다. 그래서 RR은 시간분할이라고도 불린다. 이 시간조각의 길이는 타이머 인터럽트의 배수여야한다. 예를 들어 타이머가 10초이면, 시간 조각은 10,20... 이여야한다.
예를 들어 세 작업 A,B,C가 동시에 도착하고 각각 5초간 실행하려고 한다면, SJF는 각 작업을 완료할때까지 실행 시킬 것이고, RR은 시간조각이 1초 일때 1초 마다 작업을 전환할 것이다.
SFJ의 평균 응답시간은 , RR의 평균 응답시간은 이다.
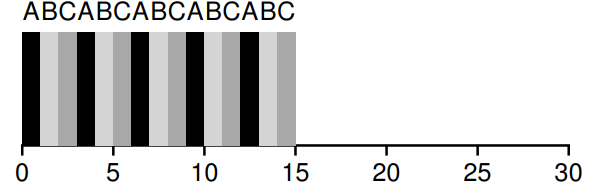
시간 조각이 짧을 수록 이 작아지므로 응답 시간 지표에서 RR의 성능이 향상된다. 하지만 시간 조각을 너무 짧게 만들면 컨텍스트 전환 비용이 커지는 문제가 생긴다. RR의 성능을 향상시키려다가 전체 성능을 저하시키는 상황이 생길 수 있는 것이다.
시간 조각을 사용하는 RR은 응답시간이 유일한 지표일 때 훌륭했다. 그렇다면 회전 완료 시간은 어떻게 될까?
A는 0초 도착, 13초 완료 / B는 0초 도착, 14초 완료 / C는 0초 도착, 15초 완료이므로 로 매우 나쁘다.
우리의 가정은 이제 두 개 남았다. 작업이 입출력을 하지 않고 CPU만 사용한다는 것과, 작업의 실행시간이 알려져 있다는 것이다.
Incorporating I/O 입출력 통합
작업은 CPU에서만 작동되며 입출력을 하지 않는다는 가정을 없애보자
스케줄러는 입출력을 할 때에는 CPU를 사용하지 않으므로 스케줄러는 CPU를 차단해야한다. 또, 입출력 완료시 프로세스를 준비 상태로 이동시켜야한다.
이것을 이해하기 위해 예를 들자, 50ms의 CPU시간이 필요한 작업 A,B가 있다. 여기서 A는 10ms의 실행마다 10ms 소요되는 I/O요청을 발생시킨다. 이때, 작업B는 A가 끝나기를 기다릴 수 있지만, A가 CPU를 포기할 때, 실행될 수 있다.
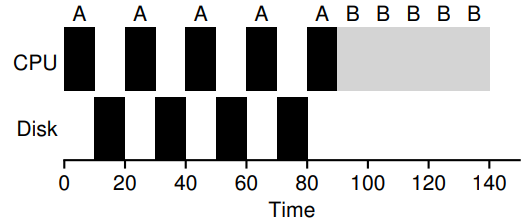
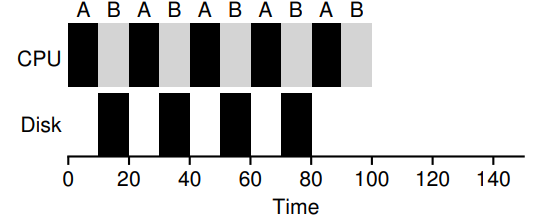
이제 남은 가정은 하나이다. 모든 작업의 수행시간을 알고 있다는 것이다. 하지만 실제로 작업의 수행시간을 미리 알 수는 없다. 프로세스가 만들어졌을 때,OS에게 이 프로세스의 수행시간을 알려주면 좋겠지만 항상 그럴 수는 없다.
이 문제를 해결하기 위한 스케줄링 방법은 다음에 알아보자
