지금까지 프로세스의 전체를 메모리에 넣었다. base, bound 레지스터를 사용해서 각 프로세스의 주소 공간을 배치하고 계산할 수 있었다. 여기서 우리가 주목할 부분이 스택과 힙 사이에 큰 빈공간이 있다는 것이다. 이 빈공간의 크기 만큼 메모리가 낭비되고 있었고 base, bound 레지스터를 이용한 방법이 완벽하지 않았다는 것을 깨달을 수 있다.
Generalized Base/Bounds 베이스,바운드 레지스터
메모리가 낭비되는 것을 방지하기 위해 세그먼테이션(Segmentation)이라는 아이디어가 나왔다. 이 아이디어는 간단하다. MMU에 하나의 base, bound 쌍만 있는 것이 아니라 주소 공간의 각 논리적인 부분들 마다 base, bound 쌍을 갖게 하는 것이다. 그렇게 함으로써 각 부분을 서로 떨어트려 놓더라도 계산할 수 있게 하는 것이다. 실제로 사용 중인 메모리만 할당하여 사용되지 않는 주소 공간(희소 주소 공간)이 크더라도 수용할 수 있다.
이 경우에 세개의 base,bound 레지스터 쌍이 필요하다.
각 base 레지스터는 물리적 메모리에서의 위치를 나타낸다.
bound 레지스터는 각 부분의 크기를 나타내며 하드웨어에게 유효한 바이트가 몇 개인지를 알려줘서 잘못된 엑세스인지 알려준다.
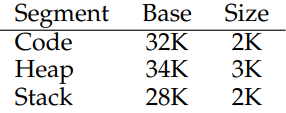
만약 가상 주소 공간 100 에서 참조가 발생하면, 하드웨어는 이 주소의 오프셋을 더해서 32KB + 100 즉 32868 에 도달한다. 그런다음 주소가 범위 내에 있는지 확인한 후 참조를 한다.
힙의 4200 에서 참조가 발생하면, 가상 주소의 힙의 시작 위치 4096을 뺀 104에 오프셋 34KB를 더해 34920을 얻는다.
힙의 끝을 넘어간 주소를 참조하려고 하면 하드웨어가 감지, 운영체제로 트랩, 프로세스가 종료될 것이다. 이것이 바로 세그먼테이션 오류(Segmentation Fault)이다.
Which Segment Are We Referring To? 세그먼트 참조 방법
하드웨어는 어떻게 오프셋을 알고 더해줄 수 있을까? 그 방법은 명시적인 접근 방법(explicit approach)으로, 가상 주소의 상위 몇 개 비트를 기준으로 주소공간을 세그먼트(부분)로 나누는 것이다. 이 기술은 VAX/VMS 시스템에서 사용되었다. 세 개의 세그먼트가 있는 우리의 예에서 두 개의 비트가 필요하다
예를 들어 상위 두 개 비트가 00이면 코드 ,01이면 힙 세그먼트로 인식한다.
힙 가상주소 4200을 예로 들면,
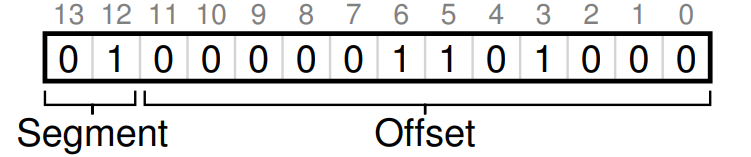
상위 두 비트가 01이기에 힙 세그먼트인 것을 알 수 있고 하위 12개 비트의 값 만큼 오프셋을 더해서 계산할 것이다. 오프셋이 바운드보다 크면 주소가 잘못된 것이다.
SEG_MASK = 0x3000, SEG_SHIFT = 12, OFFSET_MASK = 0xFFF 일 때,
// 상위 2 비트 가져오기
Segment = (VirtualAddress & SEG_MASK) >> SEG_SHIFT
// 하위 12 비트로 offset구하기
Offset = VirtualAddress & OFFSET_MASK
//offset 이 bound 를 넘는지 확인하기
if (Offset >= Bounds[Segment])
RaiseException(PROTECTION_FAULT)
else
PhysAddr = Base[Segment] + Offset
Register = AccessMemory(PhysAddr)문제점
상위 두 비트를 사용하여 세그먼트를 구별할 때 생기는 문제점이 있다.
-
상위 두 비트로 만들 수 있는 수의 경우의 수 하나가 낭비되게 된다.(경우의 수=4 , 세그먼트 수=3) 이 낭비를 없애기 위해 코드를 힙과 같은 세그먼트에 두는 시스템을 선택할 수 있다.
-
상위 비트를 사용하여 세그먼트를 선택하는 것은 가상 주소 공간의 사용을 제한한다. 예를 들어 16KB의 주소 공간은 네 개로 나뉘어져 각각 4KB의 크기를 갖게 되고 그 이상으로 확장할 수 없다.
세그먼트를 구별하는 다른 (암시적인) 방법도 있다. 예를 들어 주소가 PC에서 생성된 경우 코드 세그먼트, 스택 포인터에서 온경우는 스택 세그먼트, 그 외는 힙 세그먼트로 구별하는 식이다.
What About The Stack? 스택에 대하여
스택은 거꾸로(큰 주소에서 작은 주소로)자란다. 따라서 스택을 참조하여 주소값을 계산할 때는 다른 방법이 필요하다. 따라서 하드웨어는 단순히 base, bound 값 뿐 만 아니라 어느 방향으로 성장하는 지 알아야한다. 추가 비트를 둬서 1과 0으로 표시할 수 있다.

예를 들어 가상 주소 15KB(15360)의 가상 주소는 11 1100 0000 0000으로 상위 두 비트로 스택 인 것을 알고, 나머지로 offset이 3KB인 것을 알 수 있다.
스택의 주소를 올바르게 계산하기 위해서 offset-최대 크기(3KB-4KB)를 하여 -1KB의 음의 offset을 구한다. 그리고 base와 더해 (-1KB+28KB) 27KB의 물리적 주소를 얻을 수 있다. 바운드 체크는 음의 offset의 절댓값이 세그먼트의 현재 크기보다 작은지 확인하면 된다.
Support for Sharing 공유 기능
같은 프로그램(예:메모장)을 동시에 실행 시키는 것을 생각해 보라, 다른 데이터가 쓰이고 있지만 같은 기능을 사용한다. 이럴 때, 메모리를 절약하기 위해 주소 공간 간에 메모리 세그먼트를 공유하는 것이 유용하다.
하지만 만약, 같은 코드 영역을 공유하는 프로세스 A와 B에서, A가 코드를 변경한다면 B의 작동에 문제가 생길것이다. 이 문제를 위해 보호 비트(protection bits)를 추가하여 프로그램의 세그먼트를 읽기,쓰기,실행 가능 여부를 나타낸다. 코드 세그먼트를 읽기 전용으로 설정하면 프로세스 간에 공유할 수 있으며 손상없이 엑세스가 가능하다.
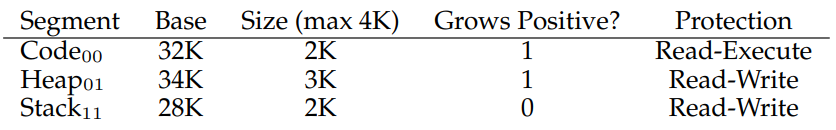
보호 비트를 사용하면 하드웨어 알고리즘도 변경되어야한다. 하드웨어는 특정 엑세스 허용 여부를 확인하여 잘못된 접근에 예외를 발생시켜야한다.
Fine-grained vs Coarse-grained Segmentation
지금 까지의 예제는 세그먼트 몇개만 있는 시스템이었다. 이러한 세그멘테이션을 coarse-grained segmentation(거친 분할) 이라하며 주소 공간을 비교적 큰,거친 부분으로 나누는 것이다. 그러나 일부 초기 시스템은 더 작고 많은 세그먼트로 나눌 수 있었다. 이를 fine-grained segmentation(미세 분할)이라고 한다. 많은 세그먼트를 지원하기위해 메모리에 세그먼트 테이블을 저장한다. 이 방법은 미세 구분된 세그먼트로 운영체제가 어떤 세그먼트가 가용한지 더 잘 파악할 수 있어 메모리 효율적 운용이 가능하다는 아이디어였다.
세그먼트를 잘게 나누면 검색 비용이 늘어날 수 있지만, 나누는게 더 유리하다면 그리해야할 것이다. 세그먼트를 나타내는 비트를 두 개가 아니라 세 개로 설정하면 세그먼트를 8개 까지 나눌 수 있고, 오히려, 코드와 힙 세그먼트를 합치면 비트 하나면 표시할 수 있을 것이다.
OS Support
세그멘테이션으로 효율적인 메모리 운영을 할 수 있었다. 하지만 여기서 OS는 무엇을 해야할까?
첫 번째, context switching 에서 OS는 무엇을 해야할까? 세그먼트 레지스터 값에 따라 주소공간을 계산하기에 세그먼트 레지스터는 저장되고 복원되어야한다. OS는 프로세스가 다시 실행되기 전에 이 레지스터를 올바르게 설정해야한다.
두 번째, 세그먼트 크기가 바뀔 때, 예를 들어 malloc()을 호출하여 객체를 할당할 때,
일부 경우는 기존 힙이 요청을 처리할 수 있으며 객체에 대한 free space를 찾아 호출자에게 포인터를 반환한다.
다른 경우에 힙 세그먼트가 성장해야 할 수도 있다.
이 경우에 메모리 할당 라이브러리는 힙을 성장시키기 위해 system call을 수행한다. (전통적인 UNIX sbrk() system call) 그러면 OS는 더 큰 세그먼트로 업데이트(세그먼트 크기 레지스터 업데이트)하고 라이브러리에 성공을 알릴 것이다. 여기서 물리적 메모리가 부족하거나 너무 많은 메모리를 독점하고 있다고 판단하면, OS가 요청을 거부할 수도 있다.
세 번째, 물리적 메모리의 빈 공간을 관리한다. 새로운 주소 공간이 생성될 때, OS는 그 세그먼트에 대한 물리적 메모리 공간을 찾을 수 있어야 한다. 각 프로세스는 여러 개의 세그먼트가 있고 그것들의 크기도 제각각이다.
발생하는 일반적인 문제는 작고 많은 빈공간이 많아져 세그먼트 할당에 어려움이 생기는 경우이다. 이것을 외부 단편화(external fragmentation)라고 한다.
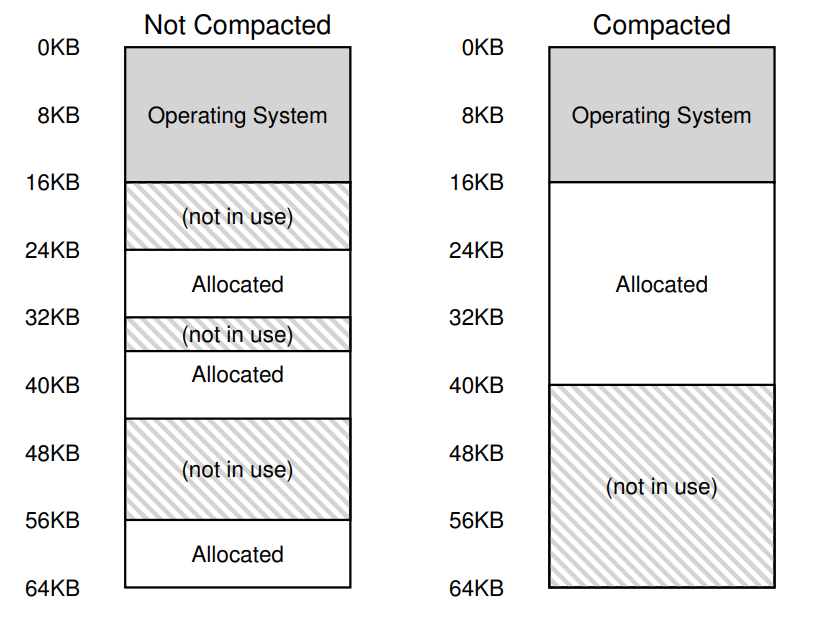
분명 여유 공간이 있지만 다 떨어져 있어서 사용할 수 없다.
해결책 중 하나는 물리적 메모리를 재배치 하여 메모리를 압축하는 것이다. OS는 실행중인 프로세스를 중지하고 물리적 메모리를 재배치하여 새로운 큰 빈 영역을 얻는다. 하지만 이 압축은 비용이 많이 드는데, 세그먼트를 복사하는 것은 메모리 집중적이며, 많은 프로세서 시간을 쓴다. 재 배치된 구조에서 기존의 세그먼트들의 확장이 안될 수 있고 또, 재 배치를 해야 할 수 있다.
다른 방법은 자유리스트(free-list) 관리 알고리즘을 사용하는 것이다. 메모리를 할당할 때 나중에 문제가 안생기도록 잘 할당하자는 것이다. 이에 대한 것은 다음 포스팅에서 알아본다. 여러 알고리즘 들이 있지만 외부 단편화는 최소화 될 뿐 없어지지 않을 것이다.
