OS가 메모리에서 어떤 페이지를 swap out 할 지 어떻게 정할 수 있을까?
캐시 관리
먼저 살펴볼 것이 있다. 메모리는 시스템의 일부만 보유하기에 사실상 시스템의 가상 메모리 페이지에 대한 캐시로 볼 수 있다. 여기서 우리의 목표는 디스크에서 페이지를 가져오는(cache miss) 횟수를 최소화 하는 것이다. 즉 메모리에서 페이지가 발견되는(cache hit) 횟수를 최대화해야한다.
캐시 히트와 미스의 수를 알면 평균 메모리 엑세스 시간(AMAT:average memory access time)를 줄일 수 있다.
은 메모리 엑세스 비용, 는 디스크 엑세스 비용, 는 cache miss 확률(0.0~0.1)이다. 데이터를 메모리에서 엑세스하는 비용은 항상 지불해야 하지만, miss의 경우 추가로 디스크에서 데이터를 가져오는 비용도 지불해야한다.
예를 들어, 256바이트 페이지의 4KB 가상 주소 공간을 생각해보자 4비트 VPN, 8비트 offset
여기서 프로세스는 16개 가상 페이지에 엑세스할 수 있다. 프로세스는 다음과 같은 가상 주소(메모리 참조)를 만든다.
[0x000, 0x100, 0x200, 0x300, 0x400, 0x500, 0x600, 0x700, 0x800, 0x900]
이 가상 주소들은 주소 공간의 첫 번째 열개의 페이지 각각의 첫번째 바이트를 나타낸다.
가상 페이지 3을 제외한 페이지가 메모리에 있다면,
[hit, hit, hit, miss, hit, hit, hit, hit, hit, hit]
이 100ns 이고 가 10ms 이면, AMAT는 100ns + 0.1 *10ms = 약 1ms 이다.
만약 히트 비율이 99.9%이면, AMAT는 10.1ms로 100배 빠르다.
다양한 정책
Optimal
Belady의 Optimal 정책에 대해 알아보자 이 정책은 교체를 하는 시점에, 메모리의 page중 가장 나중에 사용될 page를 교체를 하여 가장 적은 miss가 발생하도록 한다.
캐시(메모리)에 3개의 페이지가 올 수 있다고 할 때,
0, 1, 2, 0, 1, 3, 0, 3, 1, 2, 1의 순서로 페이지 요청한다고 가정해보자
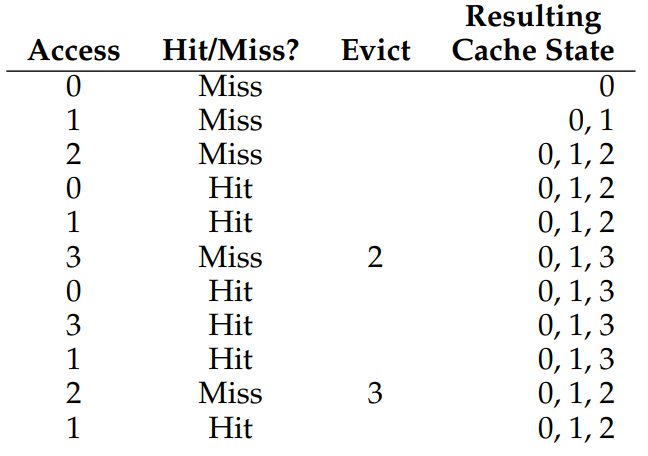
처음의 0, 1, 2 엑세스는 캐시가 빈 상태에서 시작하기에 miss이다. 이런 미스는 cold-start miss (또는 compulsory miss)라고 한다. 다음 0, 1의 엑세스는 hit이지만 다음의 3 엑세스에서 캐시가 다 찼기에 페이지 교환이 이루어져야한다. 2가 가장 늦게 엑세스 되기에 페이지 2를 제거하여 3을 추가한다.
6번의 hit 와 5번의 miss가 생기므로 54.5%의 hit rate이 나온다. 필연적인 처음 세 miss를 무시한다면, 85.7%의 hit rate이 나온다. 하지만, 우리가 스케줄링 정책을 개발할 때 미래를 할 수 없기에 이런 방식의 접근은 구현이 어렵다.
FIFO
first in, first out 정책을 살펴보자 말 그대로 먼저 들어온 것이 먼저 나가는 것이다.
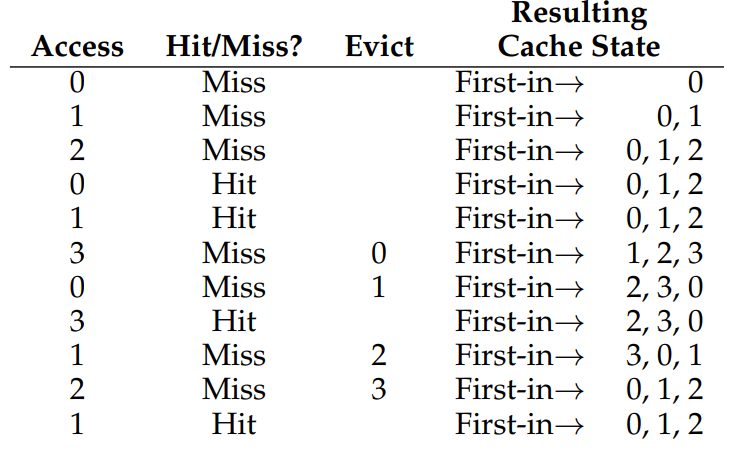
36.4% hit rate, 필수 miss를 제외하면, 57.1%의 hit rate이 나온다.
Random
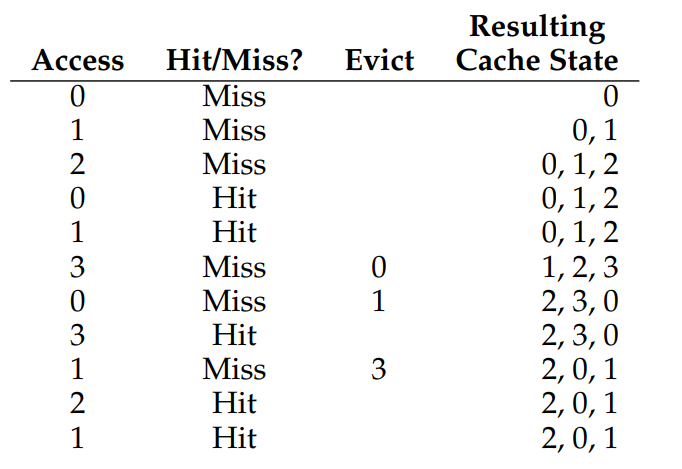
랜덤하게 교체하는 방식이다. Random의 성능은 운에 따라 달라진다.
LRU
앞선 FIFO와 Random 정책은 중요한 페이지를 제거할 수 있다. 이 문제를 해결하기 위해 우리는 최근에 엑세스한 페이지는 다시 엑세스할 가능성이 높다고 간주할 것이다. 이 정책은 지역성 원리(principle of locality)에 기반한다. 그래서 우리는 최근에 적게 사용한 페이지를 교체하는 Least-Recently Used (LRU) 정책을 사용한다. (비슷한 것으로 가장 적게 사용한 페이지를 교체하는 Least-Frequently-Used (LFU)도 있다.)
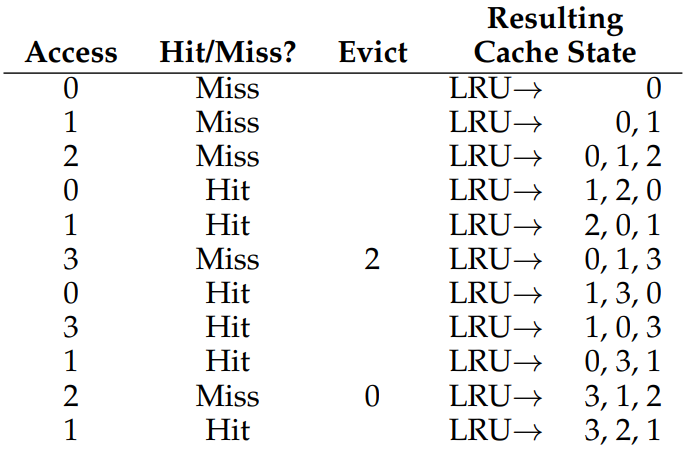
예시에서 LRU는 Optimal과 hit rate 이 같다!
참고로 반대의 원리인 MFU와 MRU도 있지만 지역성을 무시하기에 보통 잘 작동하지 않는다.
Workload Examples
몇가지 workload, 즉 프로세스의 특징을 고려해 필요한 자원을 가정하여 우리가 알아본 정책들이 얼마나 잘 작동하는지 살펴보자
첫 번째 workload는 지역성이 없다는 것이다. 지역성은 엑세스된 페이지와 같은 집합 내의 페이지가 다음에 엑세스될 확률이 높다는 것이다. 우리는 다음에 참조할 페이지를 임의로 선택하여 총 100개의 페이지에 엑세스 한다. 캐시크기를 1부터 100 까지 변화시켜가며 어떻게 작동하는지 살펴보자
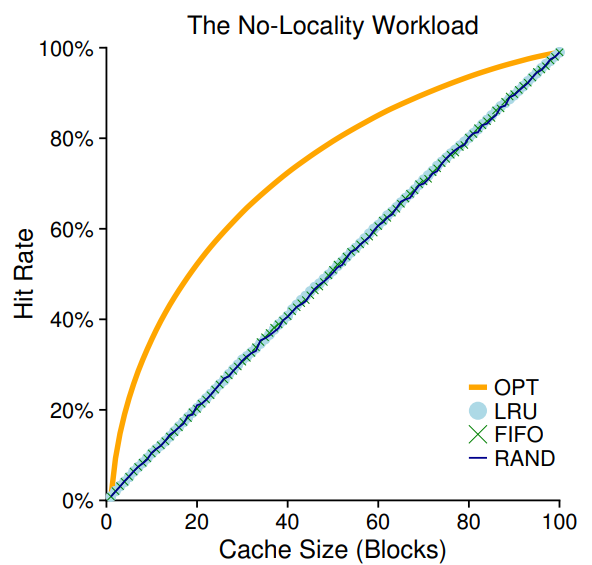
그래프는 우리가 알아본 정책들을 나타낸다. x축은 캐시 크기, y축은 hit rate 이다.
우리는 이 그래프에서 다음의 사실들을 알 수 있다.
- workload에 지역성이 없어도 큰 차이가 나지 않는다.
- 캐시가 커질 수록 hit rate이 커진다. (stack property)
- 캐시가 충분히 큰 경우 어떤 정책을 사용하든 상관 없다.
stack property란, 캐시사이즈를 늘렸을 때 늘리기 전의 내용이 늘린 후에도 들어있는 것이다.
optimal, LRU정책의 경우 stack property를 만족하기 때문에 캐시 사이즈가 늘어나면 hit ratio가 좋아진다.
반면, FIFO의 경우 stack property를 만족하지 않기 때문에 캐시사이즈를 늘렸을 때 오히려 성능이 나빠지기도 한다. (Belady's anomaly)
두 번째 workload는 80-20 이다. 참조의 80%는 20%의 페이지에서 이루어지고 , 나머지 참조인 20%는 80%의 페이지에서 이루어진다. 20% 페이지에서 참조가 많이 일어나는 상황을 가정한 것이다.
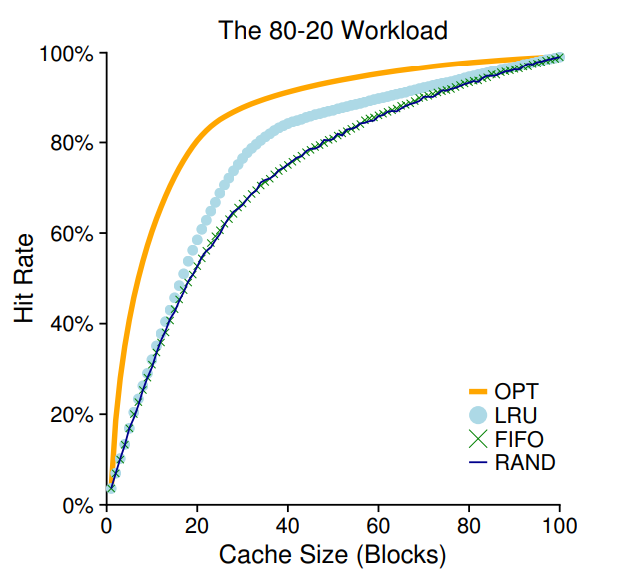
이 상황에서 LRU가 특히 더 잘 작동한다.
세 번째 workload는 looping sequential이다. 0부터 49까지 50개의 페이지를 총 10,000번 접근할 때까지 반복한다. 이 작업부하는 데이터베이스 같은 프로그램에서 나타난다.
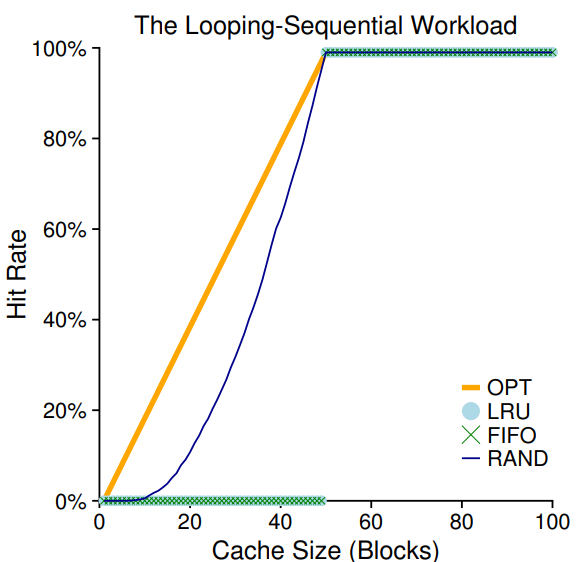
이 상황에서 LRU,FIFO는 최악의 결과를 보여준다. 캐시 크기가 40미만일때는 hit rate이 0%이고 50 이상일 때는 100%가 된다. Random 방법은 최적의 결과는 아니지만 어느정도의 성능을 보여준다. 이는 Random의 속성인 극단적인 경우가 없다는 것을 보여준다.
알고리즘 구현
LRU와 FIFO는 중요한 페이지를 버릴 수 있지만, 간단하다.
LRU를 구현하려면 많은 작업이 필요하다. 각 페이지를 엑세스 할 때마다. 그 페이지를 목록의 가장 앞으로 이동시켜야한다.
이에 비해 FIFO는 (첫번째) 페이지가 제거될 때나 새로운 페이지가 (마지막에)추가될 때에만 페이지 목록에 엑세스한다.
정책을 구현하기 위해 최근,마지막에 사용된 페이지를 추적/계산을 해야한다. 이 비용이 커진다면 더이상 간단한 정책이 아닐 것이다.
이를 위해 하드위에 지원을 추가할 수 있다. 예를 들어 각 페이지 엑세스마다 시간 필드를 업데이트하고 시간 필드를 스캔하여 최근 또는 마지막에 사용된 페이지를 알아낼 수 있다. 하지만 이를 위해 배열 전체를 스캔하는 것은 지나치게 비용이 많이 든다.
이 문제는 use bit 또는 reference bit라고 불리는 하드웨어 지원을 통해 해결할 수 있다. 각 페이지는 하나의 use bit이 있으며, 참조시 1로 설정된다. 하드웨어는 bit를 0으로 설정하지 않고 os에게 맡긴다.
clock algorithm
이 알고리즘은 LRU를 근사하는 방법이다.
시스템의 페이지들이 원형 목록에 있다고 가정해보자 특정 페이지를 가리키는 시계바늘이 있다. 교체가 발생할 때 가리켜진 페이지의 use bit를 확인해서 1이면(최근에 사용되었다는 뜻이므로 교체 부적합) 0으로 설정한 뒤 use bit가 0인 것을 찾을 때 까지 다음 페이지로 이동한다. 아래 그래프는 80-20 workload에서 clock alrorithm 이다.
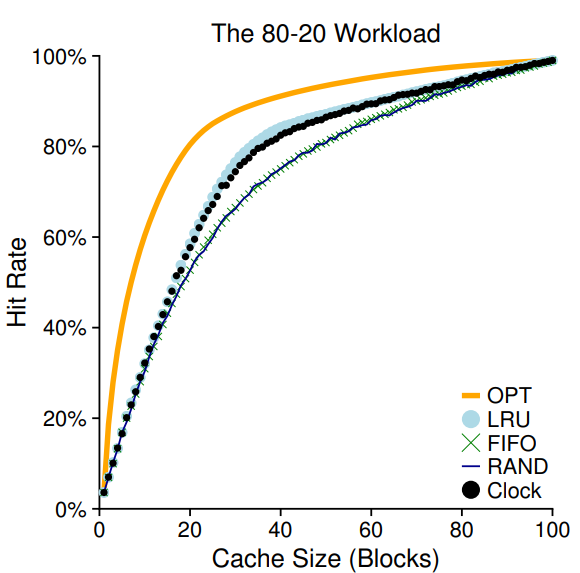
clock 알고리즘에서 페이지가 메모리에 있는 동안 수정되었는지 여부를 고려해볼 수 있다. 페이지가 수정되었다면 디스크에 새로 써야하기에 교체에 비용이 많이든다. 따라서 깨끗한 페이지를 제거하는 것이 효율적이다. 이를 지원하기 위해 dirty bit가 추가되어야한다.
Other VM Policies
Page Switching 이 VM 하위 시스템이 사용하는 유일한 정책은아니다. 페이징에서 OS는 프로세스가 page를 요청할 때 메모리로 load한다. 이와 다르게, os가 사용될 것이라고 예상한 것을 미리 가져오는 prefetching 방법이있다.
또,delayed write를 통해 저장을 한꺼번에 할 수도 있다.
Thrashing
메모리가 과다하게 할당되어 프로세스의 메모리 요구가 사용가능한 메모리를 초과하는 경우 시스템은 지속적으로 페이징되며, 이를 Thrashing이라고 한다.
초기 os에는 이를 처리하기 위한 메커니즘이 있었다. 예를 들어 프로세스의 하위 집합을 실행하지 않는 것이다. 그래서 줄어든 작업이 메모리에 맞게 실행할 수 있다. 이를 admission control(입장 제어)라고 한다.
현재 시스템은 더 엄격한 방식을 취한다. 예를 들어 Linux 일부 버전은 메모리 과다 할당시 out-of-memory killer를 실행시킨다. 이 daemon은 메모리를 많이 쓰는 프로세스를 종료시킨다. 하지만 이렇게 프로세스를 종료시키면 어떤 문제가 발생할지 모른다.
