AI Agent 시스템에서 Tools(도구) 는 보통 LLM 내부에 직접 내장되지 않고, 외부 기능을 호출할 수 있는 인터페이스로 정의됩니다.
이때 LLM이 어떤 도구를 쓸 수 있는지 알게 하려면, 시스템 프롬프트에 아래와 같이 텍스트 기반 사양(description) 으로 전달합니다:
도구 이름(name)
도구 설명(description)
입력/출력 포맷(schema)
즉, 모델은 텍스트로 주어진 도구 설명을 이해하고, 필요할 때 함수 호출 형식으로 출력을 내보냅니다.
그 후 에이전트 오케스트레이터가 해당 호출을 해석해서 실제 API나 코드를 실행하고 결과를 모델에 다시 피드백합니다.
채팅 템플릿(chat templates)에서 도구(tool) 는 단순 로깅 기능이 아니라,
LLM이 스스로 처리하기 어려운 작업(예: 웹 검색, 계산, 데이터베이스 질의, API 호출 등)을 외부 시스템에 위임(offload) 하기 위해 사용됨.
즉, LLM이 "function_call" 또는 "tool invocation" 형태로 요청을 만들면,
→ 오케스트레이터가 이를 실행
→ 결과를 다시 대화 맥락(context)에 삽입하여
→ 모델이 최종 응답을 생성합니다.
Thought–Action–Observation (TAO) cycle 은 에이전트 아키텍처의 기본 패턴으로, 보통 아래 흐름을 따릅니다:
Thought (생각)
→ 모델이 현재 상태를 분석하고 어떤 행동을 할지 계획합니다.
Action (행동)
→ 모델이 실제 도구 호출(API, 계산, 검색 등)을 실행합니다.
Observation (관찰)
→ 행동의 결과(피드백, API 응답, 계산 값 등) 를 캡처하여 모델의 다음 단계 입력으로 제공합니다.
즉, Observation 단계는 Action 단계의 결과를 받아, 이후 새로운 Thought(생각)로 연결해주는 핵심 고리입니다.
LLM이 autoregressive(자동 회귀적) 이라는 말은,
텍스트를 생성할 때 이전까지 나온 토큰들을 조건(context) 으로 삼아 다음 토큰의 확률 분포를 예측하는 방식을 뜻합니다.
즉:
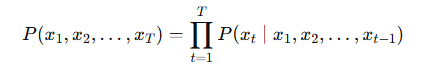

한 번에 전체 문장을 뱉는 게 아니라,
토큰 단위로 순차적으로 생성하는 구조입니다.
그래서 "predict the next word"라는 설명이 흔히 따라붙습니다.
현대의 대규모 언어 모델(LLM: Large Language Model)은 거의 모두 Transformer 아키텍처 기반으로 만들어집니다.
대표적으로 GPT, BERT, LLaMA, PaLM, Mistral, Claude 모두 Transformer 계열이에요.
Self-Attention 메커니즘 덕분에 긴 문맥을 효율적으로 처리할 수 있고, 병렬 연산이 가능해 대규모 학습에 적합합니다.
에이전트(Agent)는 보통 두 가지 큰 축으로 설명됩니다:
Brain (뇌) - LLM 같은 AI 모델
추론(reasoning), 계획(planning), 의사결정(decision making) 을 담당
Body (신체) - 도구(tools), API, 액션 모듈 등 실제 세상과 상호작용하는 능력
예: 웹 검색, 계산기, DB 질의, 파일 조작 등
즉, 뇌가 “무엇을 해야 하는지”를 생각하면, 신체가 “실제로 실행”합니다.
ReAct (Reason + Act) 접근 방식은 LLM 기반 에이전트 설계 패턴으로, 모델이 단순히 답변만 내는 게 아니라:
Reason (생각)
내부적으로 “step by step” 추론을 합니다.
문제를 하위 단계(sub-tasks)로 쪼개고 논리적으로 해결 경로를 설계합니다.
Act (행동)
필요할 경우 도구 호출(API, 계산기, 검색 등)을 실행합니다.
이후 Observation(관찰) 을 통해 결과를 받아 다시 Reason 단계로 돌아갑니다.
이 과정을 반복하면서 더 정확하고 설명 가능한 문제 해결을 하도록 합니다.
AI Agent 주기(보통 Thought → Action → Observation 루프)에서:
Thought (생각) 🧠
지금까지의 관찰(Observation)을 바탕으로 다음에 무엇을 할지 계획/결정합니다.
즉, “이제 검색을 해야 할까?”, “계산을 실행해야 할까?”, “최종 답변을 내릴까?” 같은 의사결정을 내립니다.
Action (행동)
Thought 단계에서 결정한 구체적인 실행(도구 호출, API, 계산 등) 을 실제로 수행합니다.
Observation (관찰)
Action의 결과(피드백, 검색 응답, 계산 결과 등)를 캡처합니다.
→ 따라서, “다음 단계 결정(Next step deciding)”의 책임은 Thought 단계입니다.
구조화된 출력(Structured Output) 은 도구가 결과를 단순한 텍스트가 아니라 정해진 포맷(JSON, key-value, schema 기반 등) 으로 반환하도록 설계하는 것을 말합니다.
예:
{
"title": "오늘 날씨",
"temperature": 27,
"condition": "맑음"
}이렇게 주면, 에이전트는 "27"이 온도임을 명확히 이해하고 다음 추론에 활용할 수 있습니다.
역할
파싱 용이성 → LLM이 자유 텍스트보다 쉽게 구조화된 데이터를 처리
정확성 향상 → 필요한 값만 추출 가능
연속적 사용 → 다른 도구나 DB 입력으로 연결하기 쉬움
AI Agent 루프(Thought → Action → Observation)에서 Thought(생각) 은:
외부로 드러나지 않는 내부 과정입니다.
모델이 받은 입력과 관찰 결과를 바탕으로,
“지금 어떤 도구를 쓸까?”
“문제를 어떻게 단계별로 나눌까?”
“다음에 취할 최적의 행동은 무엇일까?”
같은 추론(reasoning) + 계획(planning) 을 수행합니다.
즉, Thought = 에이전트의 머릿속에서 일어나는 내부 사고 과정 입니다.
