1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Kafka 의 경우 아파치 카프카 애플리케이션 프로그래밍 with 자바 카프카의 개념부터 스트림즈·커넥트·스프링 카프카까지 데이터 파이프라인 구축 따라하기 책을 많이 참고해 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Kafka Producer 란?
Kafka Producer 는 메시지를 생산, 발송하는 Kafka Application 입니다.
흔히들 Kafka 를 생각할 때 Broker 를 떠올리지만, 데이터를 전송하거나 생산하기 위해서는 Kafka Producer App 을 별도로 개발할 필요가 있습니다.
Kafka Producer의 주요 역할은 Properties를 가져와 기록하고 이를 적절한 Kafka Broker에 메시지를 보내는 것입니다. Producer는 파티션을 기반으로 브로커 전체에서 데이터를 직렬화, 분할, 압축 및 로드 밸런싱합니다.
Kafka Producer 를 개발할 수 있는(Kafka Producer 라이브러이가 존재하는) 언어는 아래와 같습니다.
- Java
- Scala
- Ruby
- Python
- C
- C++
- Go
3. Kafka Producer 메시지 전달 과정
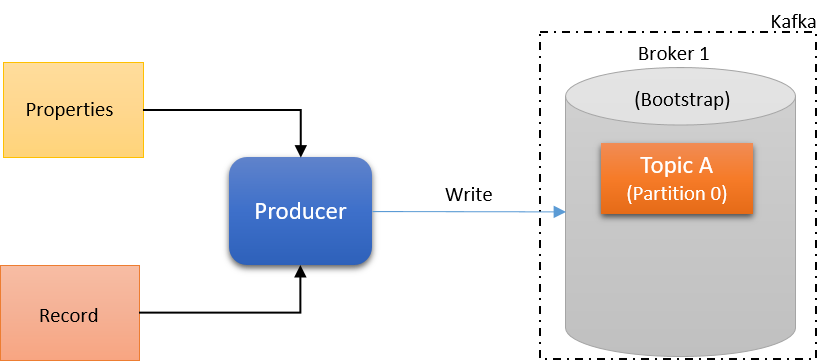
Kafka Prodcuer 는 먼저 Properties 와 Record(Value) 를 가져옵니다. 그리고 해당 Record 를 지정된 토픽으로 전송합니다.
코드로는 Producer 를 아래와 같이 작성합니다.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all"); // 메시지가 브로커에 도달했는지 확인하는 옵션 입니다. (0 : 확인하지 않습니다. 1 : leader 까지 도달했는지 확인합니다. -1(all) : follower 까지 도달했는지 확인합니다.)
props.put("retries", 0);
props.put("batch.size", 16384); // 배치 사이즈 만큼 메시지가 들어갔을 경우 브로커로 보내는 옵션입니다.
props.put("linger.ms", 1); // 설정한 시간에 도달했을 때 메시지 를 배치로 브로커로 보내는 옵션 입니다.
props.put("buffer.memory", 33554432); // 메시지를 배치로 전송하기 전 저장될 공간 사이즈
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();Kafka Producer 는 아래 5가지 단계로 메시지를 전달 합니다.
- Serialize(직렬화)
- Partition(파티션)
- Compress(압축)
- Accumulate records(메시지 배치)
- Group by broker and send (전달)

3.1 Serialize(직렬화)
이 단계에서는 Producer Record 는 Producer에 선택한 직렬화 방식대로 직렬화 됩니다. 키와 값은 Producer 에서 명시한 방법으로 직렬화됩니다. 직렬화 종류는 String Serialize, byteArray Serialize, ByteBuffer Serialize 등이 있습니다.
3.2 Partition(파티션)
이 단계에서 Producer Record를 써야 하는 Topic의 Partition을 결정합니다. 기본적으로 murmur2 알고리즘이 파티셔닝에 사용됩니다. Murmur 2 알고리즘은 전달된 키를 기반으로 고유한 해시 코드를 생성하고 적절한 파티션이 결정됩니다. 키가 전달되지 않은 경우 라운드 로빈 방식으로 파티션이 선택됩니다.
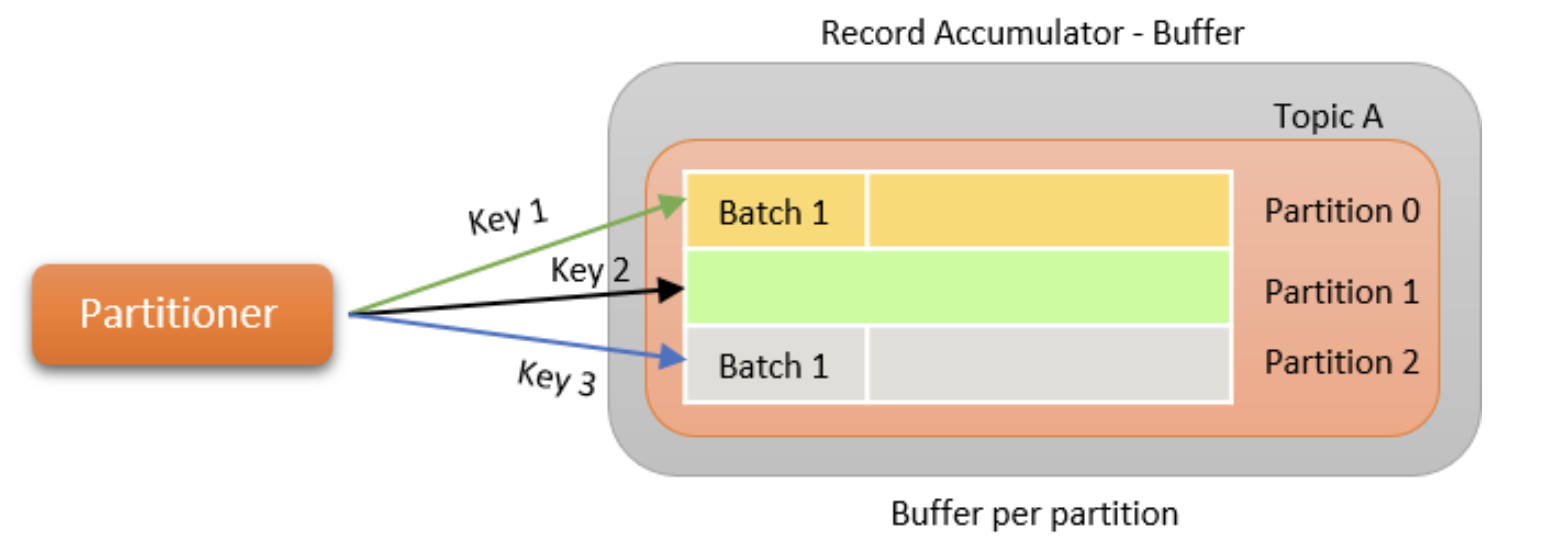
동일한 키를 레코드 세트에 전달함으로써 Kafka는 주어진 수의 파티션에 대해 수신된 순서대로 동일한 파티션에 메시지가 기록되도록 보장합니다. 수신된 메시지의 순서를 유지하려면 메시지에 적절한 키를 사용하는 것이 중요합니다. 사용자 정의 파티셔너를 Producer에게 전달하여 메시지를 써야 하는 파티션을 제어할 수도 있습니다.
3.3 Compression(압축)
이 단계에서는 Producer Record 가 Accumulator Producer 에 기록되기 전에 압축됩니다. 기본적으로 Kafka Producer 에서는 압축이 활성화되어 있지 않습니다. 지원되는 압축 유형은 아래와 같습니다.

압축을 사용하면 Producer에서 Broker 로의 전송은 물론 복제 중에도 더 빠른 전송이 가능합니다. 압축은 더 나은 처리량, 짧은 대기 시간 및 더 나은 디스크 활용도를 제공합니다.
3.4 Record accumulator
이 단계에서는 Record가 Topic의 Partition당 Buffer에 누적됩니다. Record는 Producer Batch Size 속성에 따라 배치로 그룹화됩니다. Topic의 각 파티션은 별도의 Accmulator/Buffer를 갖습니다.
Kafka producer record accumulator
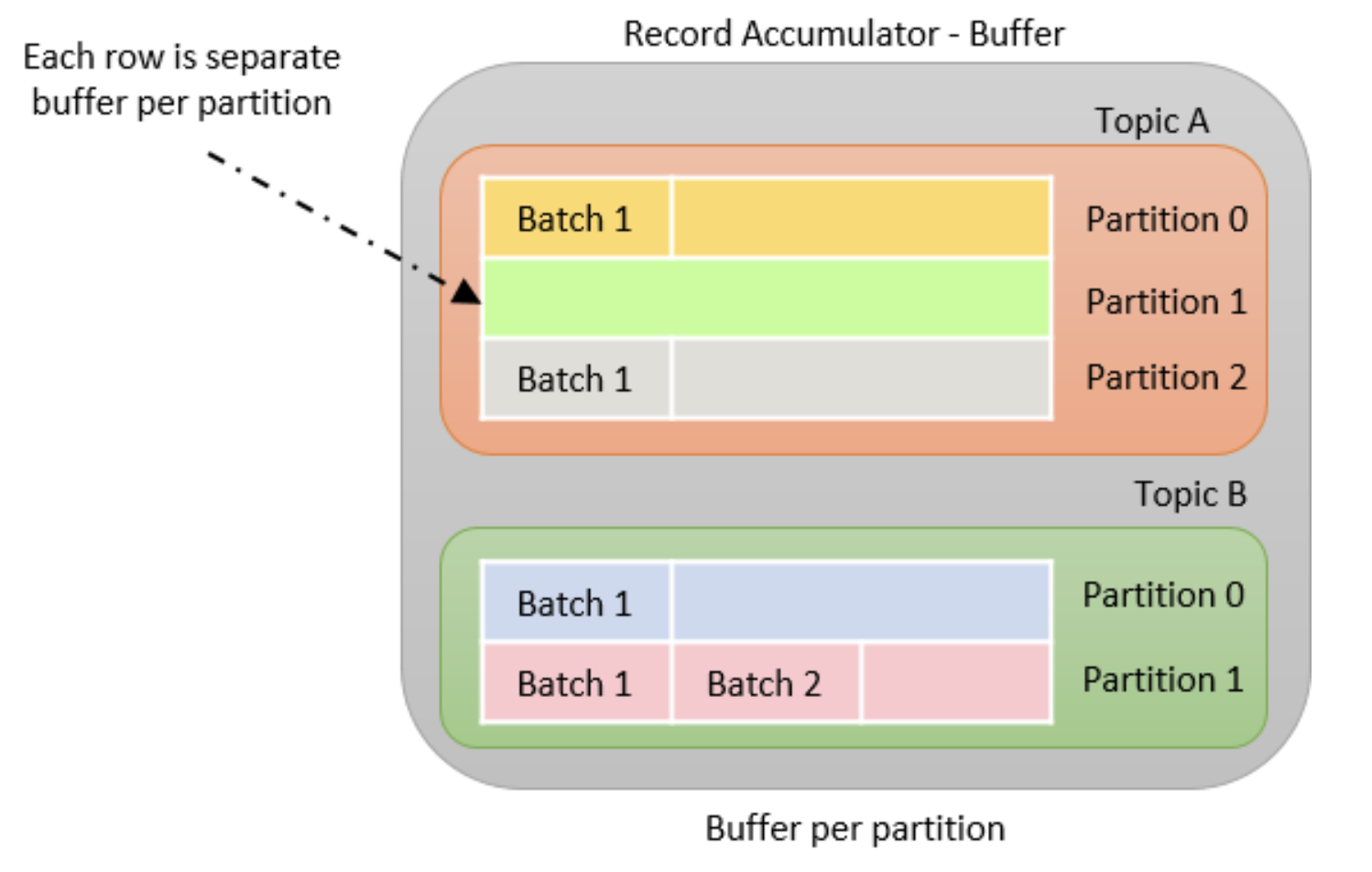
3.5 Sender thread(전송)
이 단계에서는 Record Acuumulator의 Partition Batch가 전송될 Broker 별로 그룹화됩니다. Batch의 Record는 batch.size 및 linger.ms 속성을 기반으로 Broker 로 전송됩니다. 레코드는 정의된 배치 크기에 도달하거나 정의된 지연 시간에 도달한 경우 두 가지 조건에 따라 Producer 가 전송합니다.
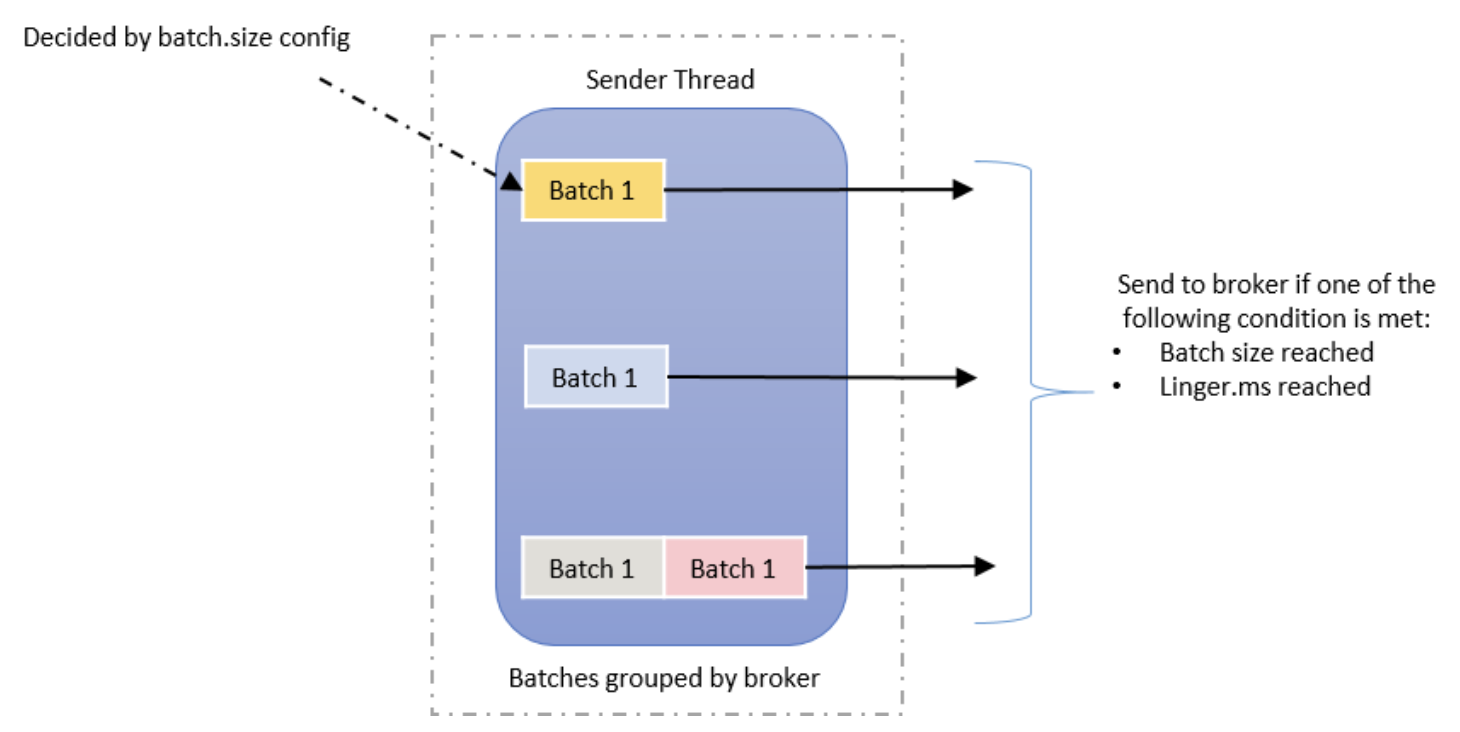
4. Kafka Producer Record
Kafka에 작성해야 하는 메시지를 Producer Record 라고 합니다. Producer Record 에는 작성해야 하는 Topic 의 이름과 레코드의 값이 있어야 합니다. 파티션, timestamp, key와 같은 다른 필드는 선택 사항입니다.
Kafka 에서 생산 소비되는 메시지 구조는 아래와 같이 구성 됩니다.
- 토픽 (Topic)
- 토픽 중 특정 파티션 위치 (Partition)
- 메시지 생성 시간 (Timestamp)
- 메시지 키 (Key)
- 메시지 값 (Value)

5. Kafka Producer Load Balancing
Kafka Producer 는 라우팅 계층 없이 Partition 의 Leader인 Broker 에 직접 데이터를 보냅니다. Producer 가 이를 수행할 수 있도록 모든 Kafka 노드는 어느 서버가 살아 있고 Topic Partition 의 Leader 가 어디에 있는지에 대한 메타데이터 요청에 언제든지 응답하여 Producer 가 요청을 적절하게 전달할 수 있도록 할 수 있습니다.
클라이언트는 메시지를 전송할 Partition 을 제어합니다. Random Load Balancing 을 구현하여 무작위로 수행할 수도 있고 의미론적 분할 기능을 통해 수행할 수도 있습니다. 우리는 사용자가 분할할 키를 지정하고 이를 사용하여 파티션에 해시하도록 함으로써 의미론적 파티셔닝을 위한 인터페이스를 노출합니다(필요한 경우 파티션 기능을 재정의하는 옵션도 있습니다). 예를 들어 선택한 키가 사용자 ID인 경우 해당 사용자에 대한 모든 데이터는 동일한 파티션으로 전송됩니다. 이를 통해 Consumer 는 자신의 Consumption 에 대해 지역성을 가정할 수 있습니다. 이러한 파티셔닝 스타일은 Consumer 의 지역 구분 처리를 허용하도록 명시적으로 설계되었습니다.
6. 맺음말
kafka Producer 가 메시지를 생산하는 과정을 확인할 수 있었습니다. 프로젝트 때 Kafka Producer 를 개발하며 해당 Producer API 를 만져볼 기회가 있었지만, 원리를 찾아보며 이해를 하니 더 필요한 튜닝 값들이 있고 이를 적용해볼 수도 있지 않을까 생각할 수 있게 됐습니다.
