
1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Spark의 경우 Spark 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Partition?
Spark 에서 Partition 이란 클러스터의 물리적 머신에 존재하는 로우의 집합을 의미합니다.
조금 더 쉽게 이해하자면 DataFrame 에서 Partition 이 1개라면 수 많은 Executor 들이 있다하더라도 병렬성은 1이 됩니다.
반대로 Partition 은 여러개 지정 돼 있더라도 Executor 가 1개라면 마찬가지로 병렬성은 1이 됩니다.
즉 Partition 은 여러 Executor 들의 병렬 작업을 위한 작업 분할 기준이 됩니다.
DataFrame 을 활용한다면, Partition 을 수동 또는 개별적으로 처리할 필요가 없습니다. 물리적 파티션에 데이터 변환용 함수를 지정하면 Spark 이 실제 처리 방법을 결정합니다. 하지만 모든 상황에 완벽하게 DataFrame 의 고수준 API 가 좋은 병렬 처리를 지원하지는 않습니다.
그렇다면 Partition 은 어떻게 나누는 게 좋을까요?
Spark 완벽 가이드에서는 아래와 같이 제시를 하고 있습니다.
" 스테이지에서 처리해야할 데이터의 양이 매우 많다면 클러스터의 CPU 코어당 최소 2~3개의 테스크를 할당할 것 "
그리고 아래 2가지의 설정을 조절할 것을 권장하는데요.
- spark.default.parallelism
YARN Cluster Mode에서 이 값은 [Executor 개수 x Core 개수]
- spark.sql.shuffle.partitions
이 값들은 조정하는 것이 궁극적인 튜닝 방법은 아닌 듯 합니다.
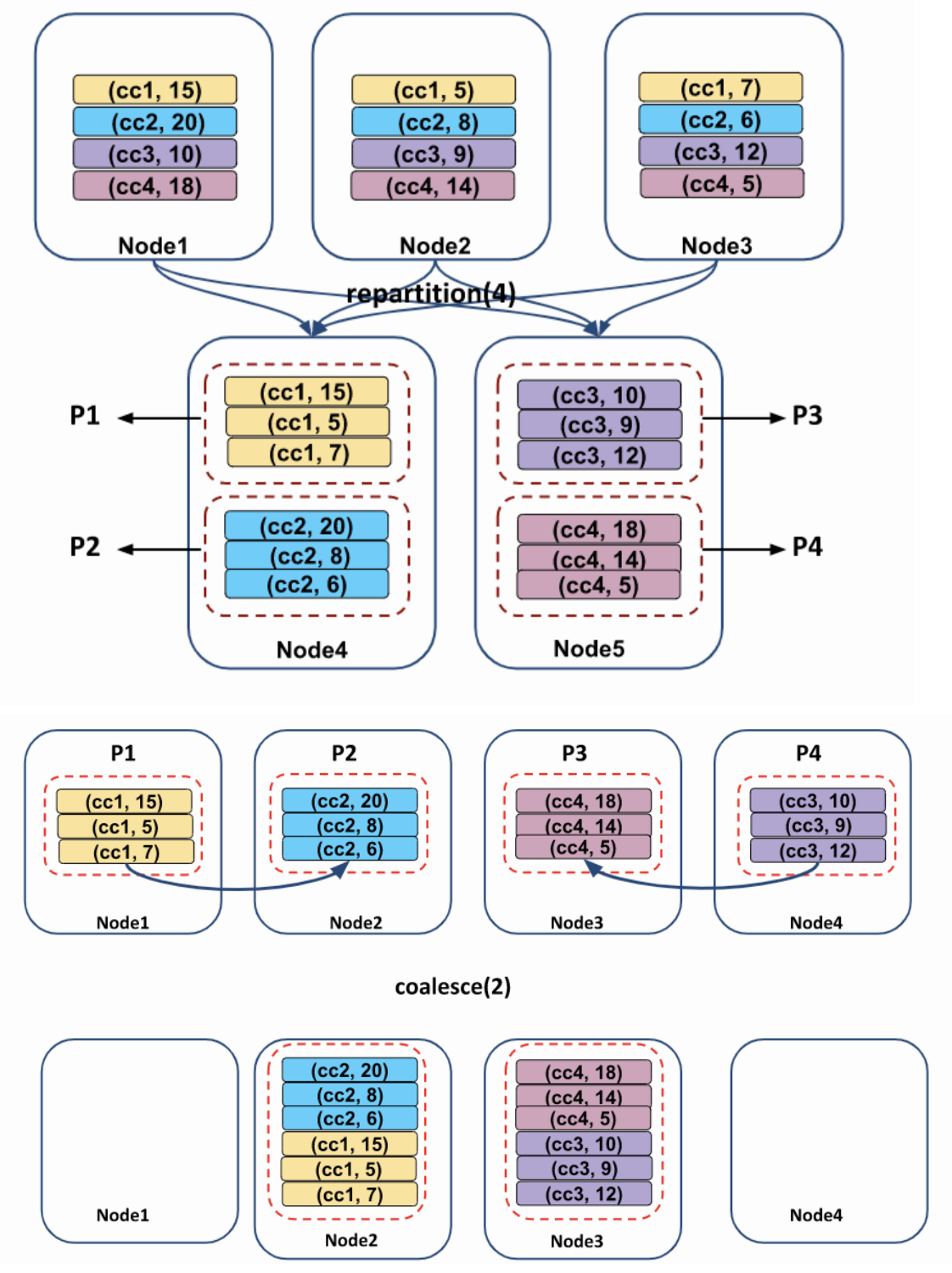
3. Repartition
자주 필터링하는 컬럼 기준으로 데이터를 분할하여 최적화를 할 수 있습니다.
이때 repartition 을 이용할 수 있습니다.
df.rdd.getNumPartitions() # df 의 현재 파티션 수
df.repartition(10) # 10 개의 파티션으로 Spark 이 알아서 파티셔닝
from pyspark.sql.functions import col
df.repartition(col("PART_COL")) # 원하는 컬럼으로 Spark 이 알아서 개수를 지정하여 파티셔닝
df.repartition(5, col("PART_COL")) # 원하는 컬럼을 원하는 개수만큼 파티셔닝그러나 repartition 메소드는 호출 시 반드시 전체 데이터에서 Shuffle 이 발생하게 되므로 반드시 현재 파티션 보다 많이 만들 필요가 있거나, 파티션 컬럼 기준을 만들 필요가 있을 경우에만 사용합니다.
DataFrame 과 RDD 모두 해당 메소드가 있습니다.
4. Coalesce
전체 데이터를 Shuffle 없이 병합하는 경우에 사용합니다.
동일한 워커에 존재하는 파티션을 합치는 메소드 입니다.
주로 Write 시 하나의 파일로 만들 때 사용하는 경우에 저는 활용하고 있습니다.
df.repartition(5).coalesce(1)DataFrame 과 RDD 모두 해당 메소드가 있습니다.
아래와 같이 Repartition 과 다르게 Coalesce 는 Shuffle 과정이 없습니다.
5. HashPartitioner & RangePartitioner
저수준 API 인 RDD 로 내려와서 Partitioning 방식을 지정할 수도 있습니다.
pyspark 에서는 HashPartitioner 와 RangePartitioner 를 찾기가 어렵습니다.
예제는 아래와 같습니다.
val df = spark.read.option("header", "true").option("sep",",").csv("test/*.csv)
val rdd = df.coalesce(10).rdd
import org.apache.spark.HashPartitioner
val keyedRdd = rdd.keyBy(row => row(6).toInt.toDouble)
keyedRdd.partitionBy(new HashPartitioner(10)).take(10)6. 맺음말
full scan 을 해야할 경우에는 사실 파티셔닝의 의미가 없지 않을까 하는 생각도 듭니다.
예를 들어 Spark Streaming 에서 데이터를 가져와서 저장을 해야하는 경우는 Partitioning 이 큰 의미가 없지 싶습니다.
이 부분은 조금 짧은 생각인 듯 합니다. Full Scan 을 하더라도 foreachPartition 을 통해 병렬 처리가 가능한 부분을 생각하지 못하고 말했습니다.
그러나 분석 이벤트가 발생했을 때에는 조건들이 발생하기 때문에 Partitioning 이 상당히 도움이 많이 될 듯 합니다.
기 개발 된 로직에서 Partition 을 튜닝하여 속도 향상을 도모해 볼 필요가 있을 듯 합니다.

많은 것을 배웠습니다, 감사합니다.