1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Spark의 경우 Spark 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Spark Join
Spark 에서는 왼쪽과 오른쪽 데이터셋에 있는 하나 이상의 키값을 비교하고 왼쪽 데이터 셋과 오른쪽 데이터셋의 결합 여부를 결정하는 조인 표현식의 평가 결과에 따라 두 개의 데이터셋을 조인합니다.
아래는 조인 방법 입니다.
- 내부 조인(inner join) : 왼쪽과 오른쪽에 데이터셋에 키가 있는 로우를 유지
- 외부 조인(outer join) : 왼쪽이나 오른쪽에 데이터셋에 키가 있는 로우를 유지
- 왼쪽 외부 조인(left outer join) : 왼쪽 데이터셋에 키가 있는 로우 유지
- 오른쪽 외부 조인(right outer join) : 오른쪽 데이터셋에 키가 있는 로우 유지
- 왼쪽 세미 조인(left semi join) : 왼쪽 데이터셋의 키가 오른쪽 데이터셋에 있는 경우에는 키가 일치하는 왼쪽 데이터셋만 유지
- 왼쪽 안티 조인(left anti join) : 왼쪽 데이터셋의 키가 오른쪽 데이터 셋에 없는 경우에는 키가 일치하지 않는 왼쪽 데이터셋만 유지
- 자연 조인(natural join) : 두 데이터셋에서 동일한 이름을 가진 컬럼을 암시적(implicit) 으로 결합하는 조인을 수행
- 교차 조인(cross join) 또는 카테시안 조인(Cartesian join) : 왼쪽 데이터셋의 모든 로우와 오른쪽 데이터셋의 모든 로우를 조합
3. Spark join 수행 방식
스파크가 조인을 수행하는 방식은 아래와 같이 2가지 입니다.
- 노드간 네트워크 통신 전략
- 노드별 연산 전략
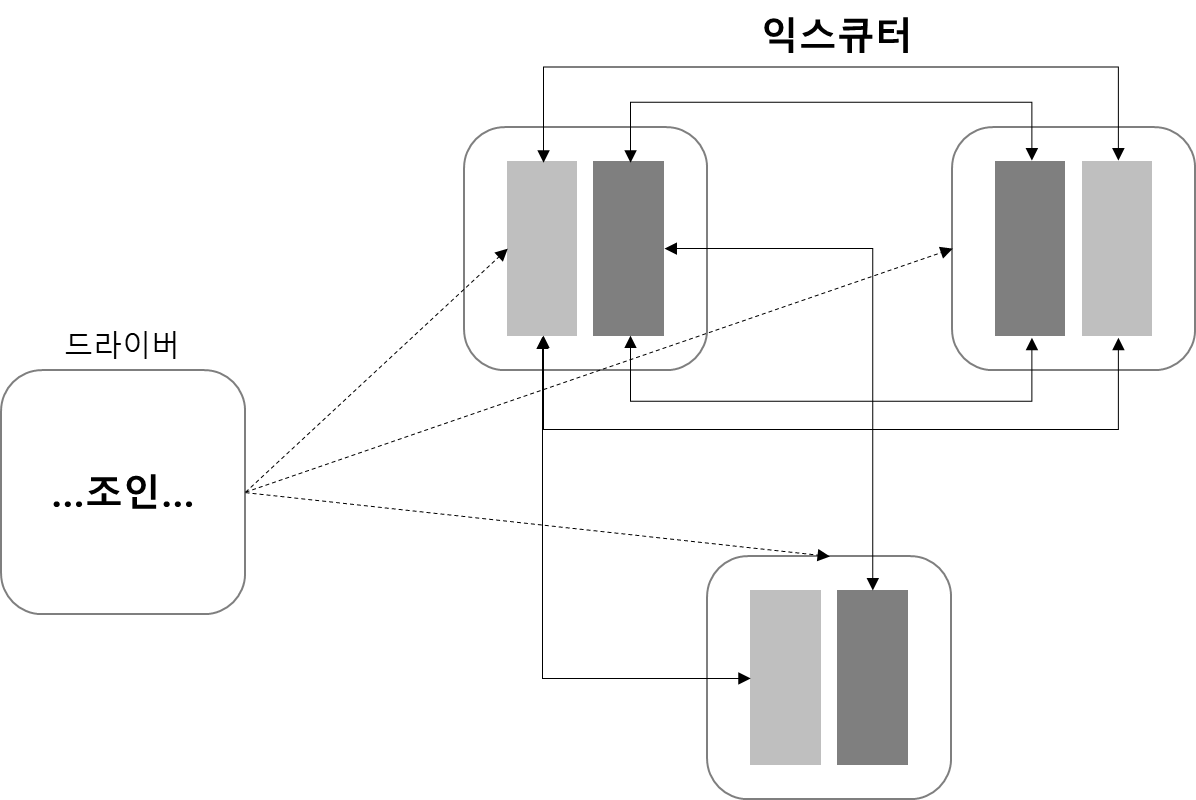
3.2. Shuffle Join
서로 큰 테이블 간에 Join 할 때 사용되는 방식입니다. 셔플 조인은 전체 노드 간 통신이 발생합니다. 그리고 조인에 사용한 특정 키나 키 집합을 어떤 노드가 가졌는지에 따라 해당 노드와 데이터를 공유합니다. 이런 통신 방식 때문에 네크워크는 복잡해지고 많은 자원을 사용합니다. 특히 데이터가 잘 나뉘어 있지 않다면 더 심해집니다.
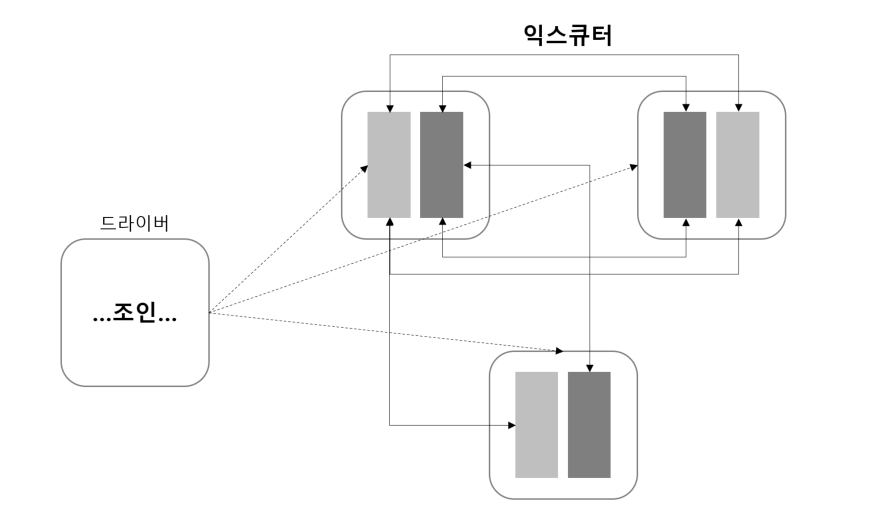
3.3. Broadcast Join
DataFrame을 클러스터의 전체 워커 노드에 복제하는 방식으로 얼핏 보기에는 자원을 많이 사용할 것처럼 보이지만 아닙니다. 물론 대규모 노드 간 통신이 발생은 하지만 첫 브로드캐스트 이후로는 노드 사이에 추가적인 통신이 발생하지 않습니다. 브로드캐스트 되는 데이터는 작은 데이터이고 큰 테이블을 익스큐터들로 분산되어 join이 수행되는 방식 입니다.
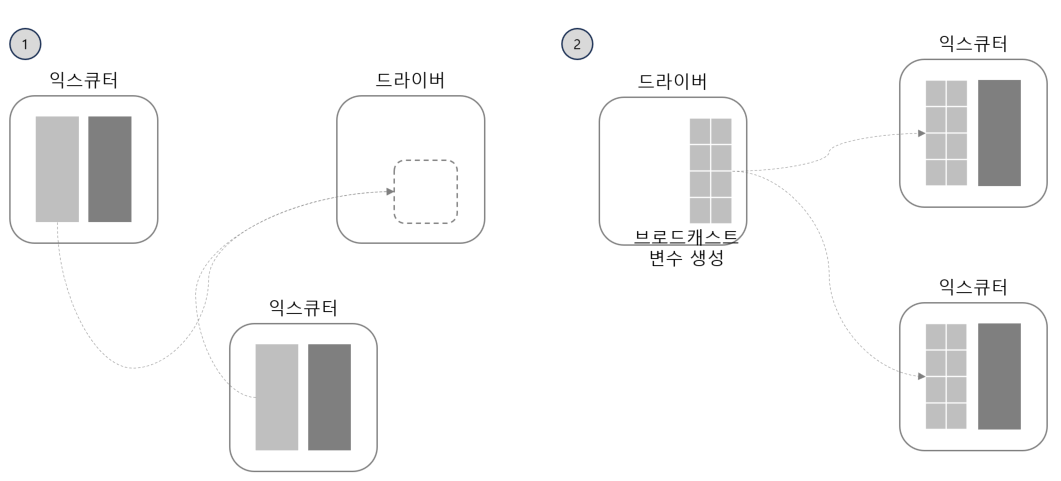
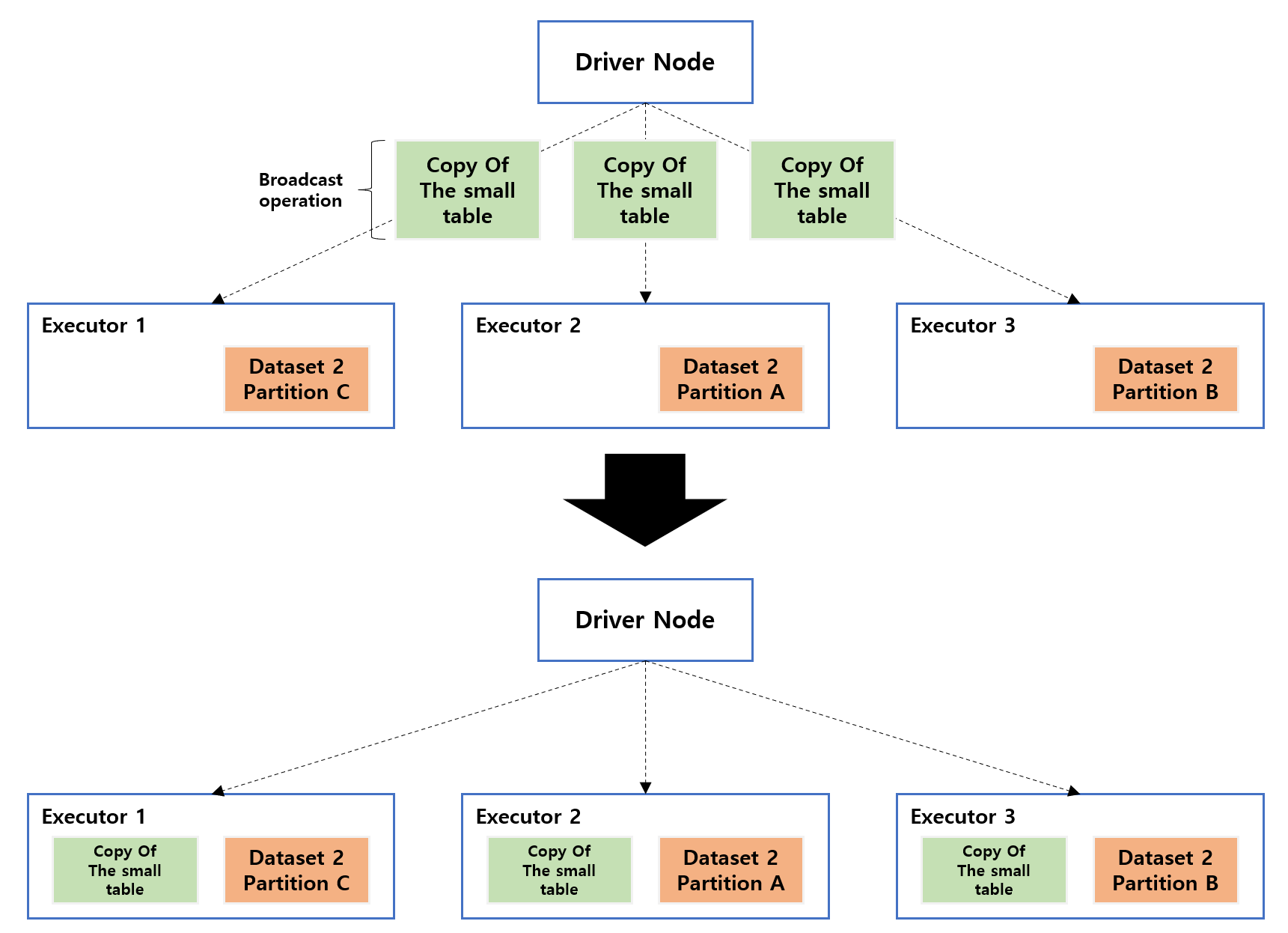
참고 : https://towardsdatascience.com/the-art-of-joining-in-spark-dcbd33d693c
당연하게도 너무 큰 데이터를 브로드캐스트 하면 고비용의 수집 연산이 발생하므로 드라이버 노드가 비정상적으로 종료될 수 있습니다.
3.4. Sort Merge Join
Sort Merge Join 조인 작업 전에 파티션 마다 join key 를 기준으로 정렬됩니다. 정렬된 두 데이터 세트를 병합하는 과정이 Sort Merge Join 입니다. Shuffle Hash Join 에 비해서 클러스터에서 데이터 이동을 최소화하는 경향이 있다고 합니다.
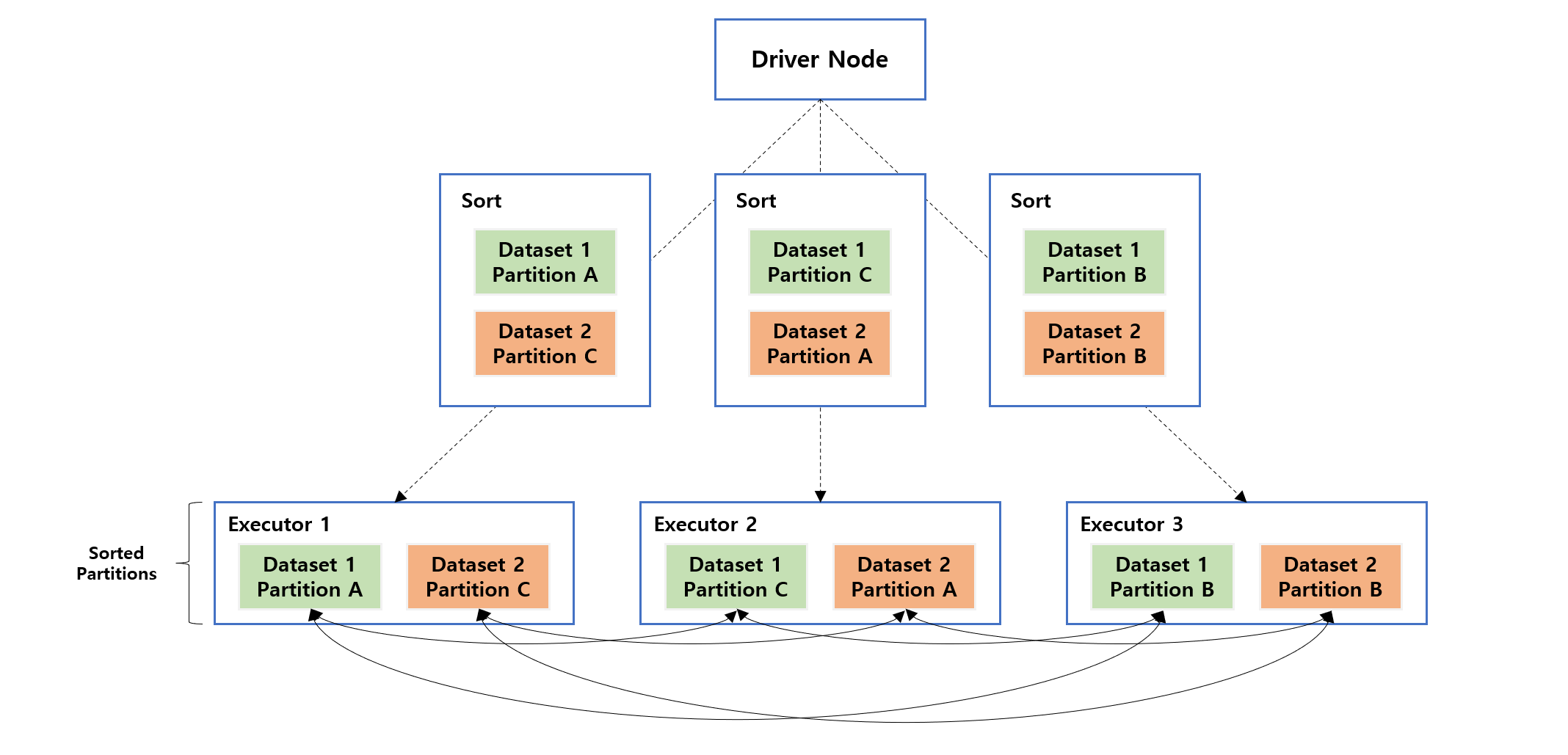
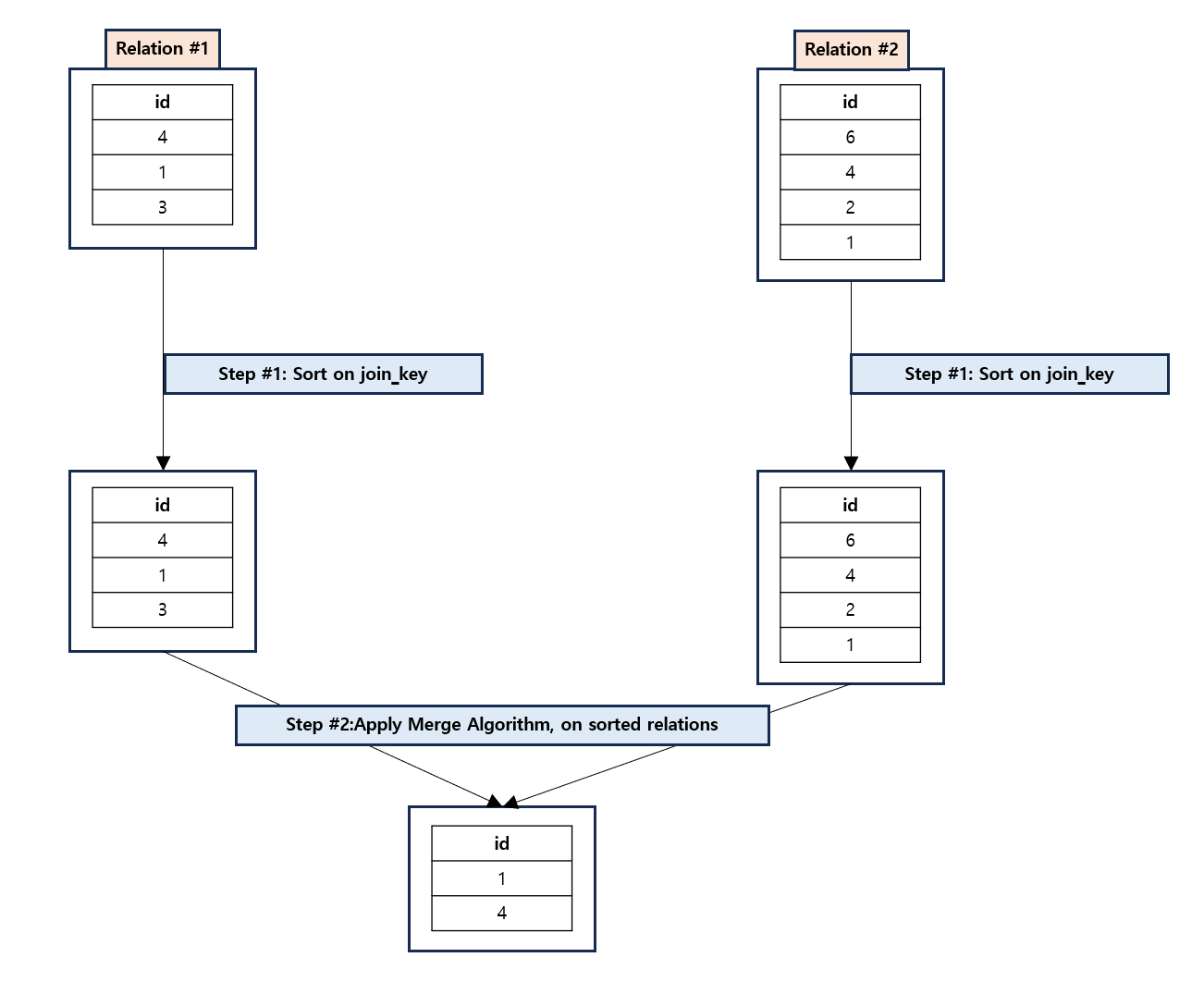
참고 : https://towardsdatascience.com/the-art-of-joining-in-spark-dcbd33d693c
3.5. Hash Join
hash join 은 먼저 더 작은 Relation의 join key 를 기반으로 해시 테이블을 생성한 다음 해시된 join key 감과 일치하도록 더 큰 Relation을 반복하면서 수행됩니다.
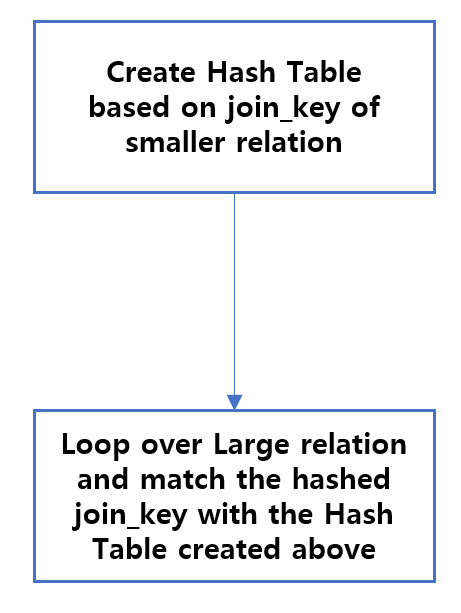
참고 : https://towardsdatascience.com/the-art-of-joining-in-spark-c0e7b4572bcf
3.6. Broadcast Hash Join
Broadcast hash join 은 작은 테이블을 각 Node 별로 복사하여 Partition 별로 Join 을 맺는 방식 입니다.
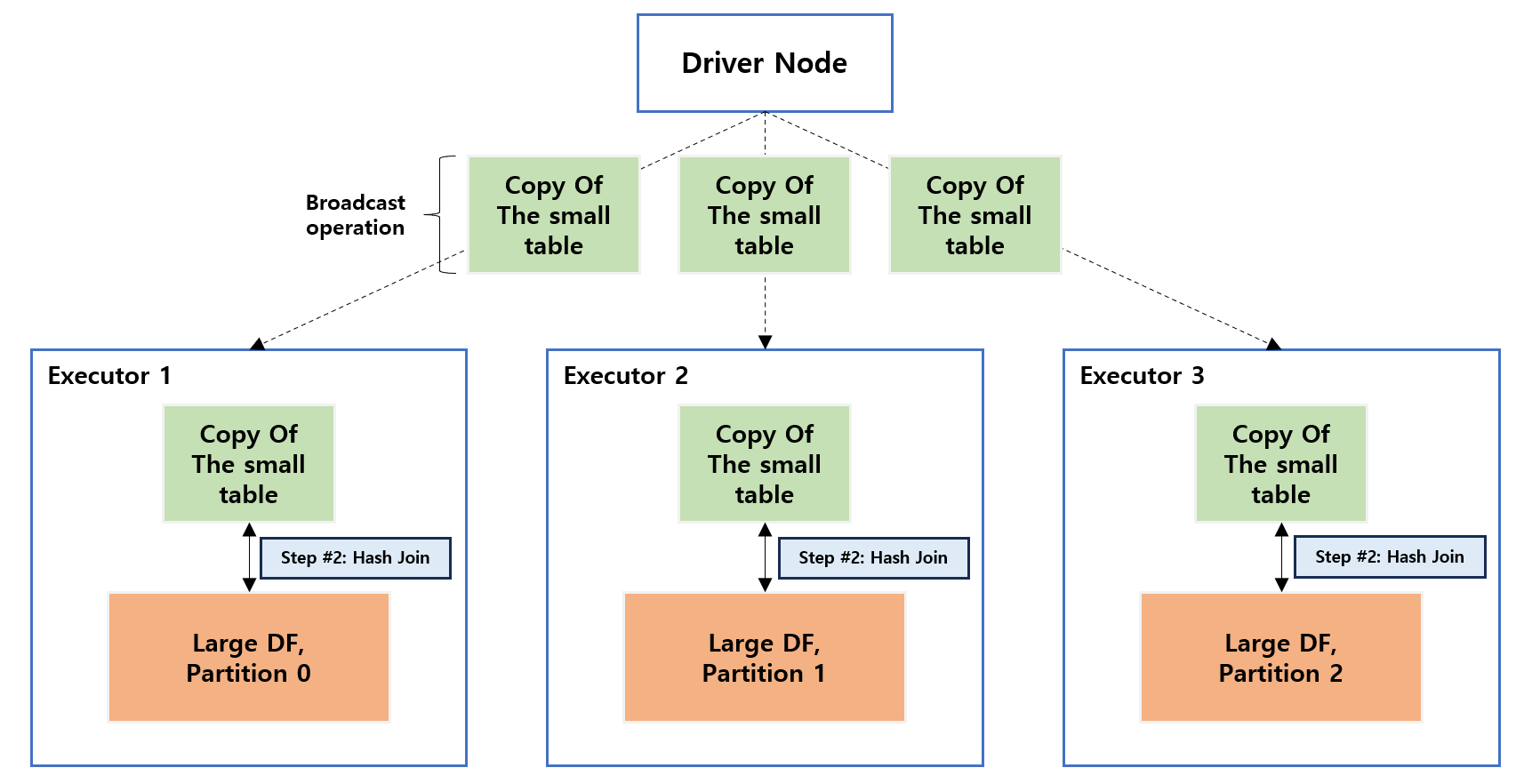
참고 : https://towardsdatascience.com/the-art-of-joining-in-spark-c0e7b4572bcf
3.7. Shuffle Hash Join
동일한 Executor 노드에서 동일한 Join key 값으로 데이터를 이동한 후 Hash Join 을 수행합니다. 조인 조건을 Join key로 사용하면 Executor 간에 데이터가 섞이고 마지막 단계에서 동일한 키의 데이터가 동일한 Executor 에 존재할 것임을 알기 때문에 데이터가 Hash Join 을 사용하여 결합됩니다.
테이블이 상대적으로 큰 경우 Broadcast 를 사용하면 드라이버 및 실행기 측 메모리 문제가 발생할 수 있습니다. 이 경우 Shuffle Hash Join 이 사용 됩니다. Shuffling 과 Hashing 이 모두 포함되므로 비용이 많이 드는 조인입니다. 또한 Hash 테이블을 유지하기 위한 메모리와 계산이 필요합니다.
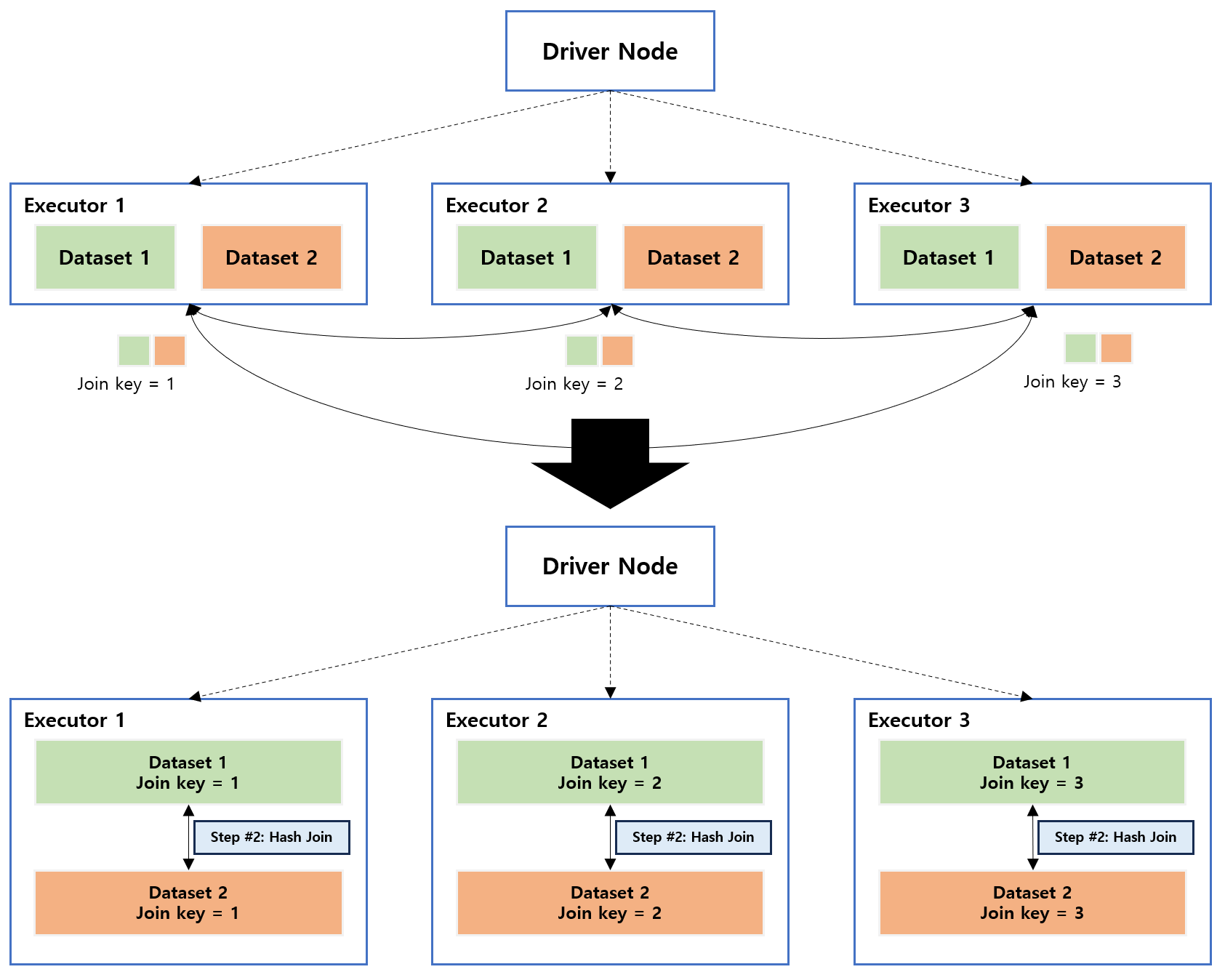
참고 : https://towardsdatascience.com/the-art-of-joining-in-spark-c0e7b4572bcf
3.8. Shuffle Sort Merge Join
데이터를 Shuffle 하여 동일한 Executor 와 동일한 Join key 를 일치시킨 다음 Sort Merge Join 작업을 수행합니다.
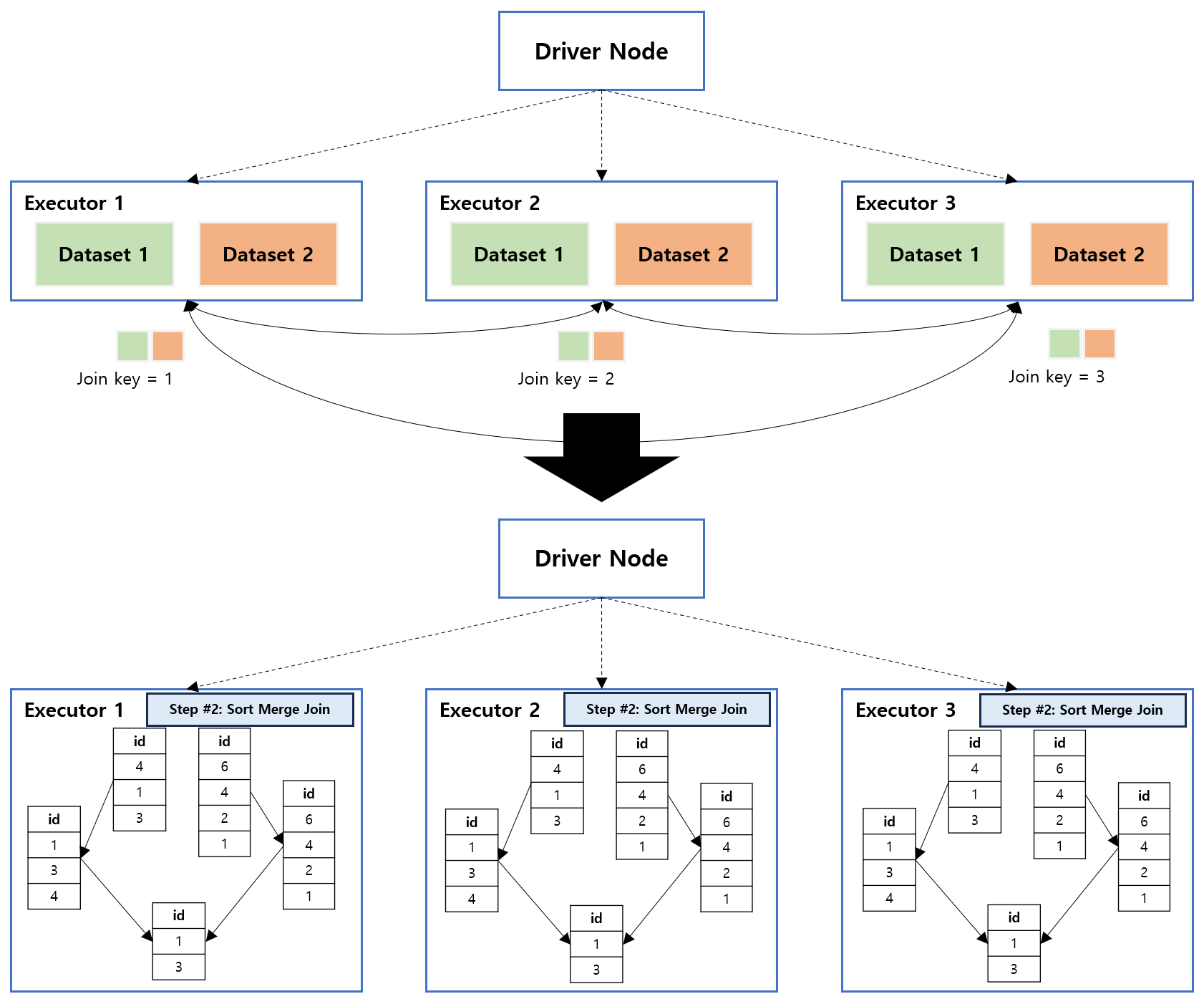
참고 : https://towardsdatascience.com/the-art-of-joining-in-spark-c0e7b4572bcf
3.9. Cartesian Product Join
Shuffle and Replication Nested Loop Join 이기도 하며 데이터 셋이 Broadcast 되지 않는다는 점을 제외하면 Broadcast Nested Loop Join 과 매우 유사하게 동작합니다.
대규모 데이터셋과의 Join 의 경우 성능이 매우 나빠질 수 있으므로 피해야 할 join 유형 입니다.
3.10. Broadcast Nested Loop Join
가장 작은 데이터셋이 모든 Executor 에 Broadcast 되고 두 데이터 사이에 Nested Loop Join 이 수행 되는 방식 입니다.
4. SQL Optimizer & Hint
Spark 에서도 SQL Optimizer 가 있습니다. 이 Optimizer 를 통해 우리가 join 을 어떤 방식으로 수행할 지 자동으로 Spark 이 지정을 하는데요. 아주 작은 테이블 사이에서 조인의 경우 Spark 가 조인 방식을 결정하도록 내버려두는 것이 제일 좋다고 합니다. 필요한 경우 브로드캐스트 조인을 강제로 지정할 수 있습니다.
Spark 에서는 Hint 를 작성할 수 가 있는데요. 이는 강제성이 없으므로 SQL Optimizer 가 무시할 수 있습니다.
SELECT /*+ MAPJOIN(graduateProgram) */
*
FROM A
JOIN B
ON A.COL1 = B.COL15. Shuffle 을 피하는 방법
-
Known partitioner : 양쪽 RDD가 명시적인 파티셔너를 가진다.
-
broadcast hash join : 한 쪽 데이터셋이 메모리에 들어갈 만큼 작을 때 사용하여 Shuffle 을 줄입니다.
-
Partial manual broadcast hash join : 소수의 키에 데이터가 크게 몰려 있어서 메모리에 올릴 수 없는 경우, 몰려있는 키만 빼고 일반 키들만으로 broadcast join을 하는 방법도 고려해볼 수 있습니다. 각각 키별로 필터링하여 broadcast join 과 일반적인 join 을 나눠서 수행하고 union 으로 합치는 방법 입니다. 이 방법은 다루기 힘든 심하게 skewed 된 데이터를 다룰 대 고려해볼 수 있습니다.
참고 : (Salting) https://mesh.dev/20220130-dev-notes-008-salting-method-and-examples/
6. 맺음말
대용량 데이터를 Join 할 때 어떻게 할 것인지를 판단하여 join 전략을 세울 수 있지만, 대부분 SQL Optimizer에게 맡기는 것이 좋을 듯 합니다. 그러나 Data Skewed 를 처리하는 방법은 SQL Optimizer 에 맡길 수 없는 부분이기 때문에 Salting 을 고려해봐야 할 듯 합니다.
