1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Spark의 경우 Spark 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. 이벤트 시간과 처리 시간
-
이벤트 시간 : (이벤트가 실제로 발생한 시간), 이벤트 시간은 데이터에 기록되어 있는 시간 입니다. 대부분의 경우 이벤트가 실제로 일어난 시간을 의미합니다. 이벤트 시간은 이벤트를 다른 이벤트와 비교하는 더 강력한 방법을 제공하기 때문에 사용해야 합니ㅏㄷ. 이 때 지연되거나 무작위로 도착하는 이벤트를 해결해야 한다는 문제점이 있습니다. 따라서 스트림 처리 시스템은 지연되거나 무작위로 도착한 데이터를 반드시 제어할 수 있어야 합니다.
-
처리 시간 : (이벤트가 시스템에 도착한 시간), 처리 시간은 스트림 처리 시스템이 데이터를 실제로 수신한 시간입니다. 처리 시간은 세부 구현과 관련된 내용이므로 이벤트 시간보다 덜 중요합니다. 처리 시간은 이벤트 시간처럼 외부 시스템에서 제공하는 것이 아니라 스트리밍 시스템이 제공하는 속성이므로 순서가 뒤섞이지 않습니다.
3. 상태 기반 처리
상태 기반 처리는 오랜 시간에 걸쳐 중간 처리 정보 (상태)를 사용하거나 갱신하는 경우에만 필요합니다. 상태 기반 처리는 이벤트 시간을 사용하거나 키에 대한 집계를 사용하는 상황에서 일어납니다. 이때 집계키가 반드시 이벤트 시간과 연관성을 가져야 하는 것은 아닙니다.
스파크는 상태 기반 연산에 필요한 복잡한 처리를 대신합니다. 예를 들어 그룹화를 지정하면 구조적 스트리밍이 사용자를 대신해 정보를 유지하고 갱신합니다. 사용자는 단순하게 로직만 정의하면 됩니다. 스파크는 상태 기반 연산에 필요한 중간 상태 정보를 상태 저장소에 저장합니다. 스파크는 상태 저장소의 구현체인 인메모리 상태 저장소를 제공합니다. 인메모리 상태 저장소는 중간 상태를 체크포인트 디렉터리에 저장해 내고장성을 보장합니다.
4. 워터마크로 지연 데이터 제어
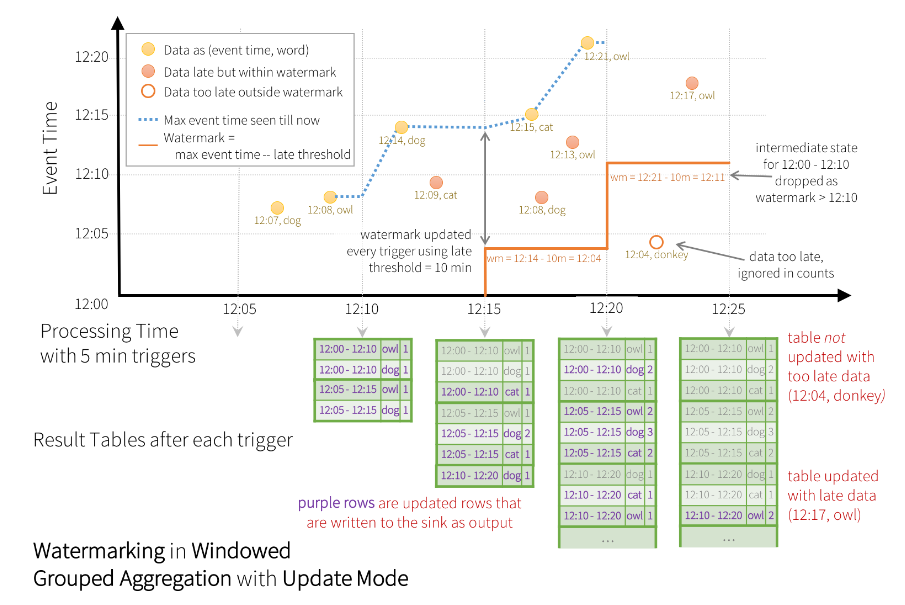
Spark 의 Watermark 는 시간 제한을 설정할 수 있는 스트리밍 시스템의 기능입니다. 늦게 들어온 이벤트를 어디까지 처리할지 시간을 제한할 수 있습니다.
- 모바일 장비의 로그를 처리하는 어플리케이션에서 업로드 지연의 경우
- kafka 에서 1번 배치만에 모든 데이터를 받지 못했을 경우
이럴 경우 Watermark 를 지정해 지연된 과거 데이터 까지 처리할 수 있습니다.
watermark 는 특정 시간 이후에 처리에서 제외할 이벤트나 이벤트 집합에 대한 시간 기준입니다.
지연 도착 현상은 네트워크 지연이나 장비의 연결 실패 또는 다른 여러 가지 원인으로 인해 발생할 수 있습니다. 하지만 Dstream API 는 지연 데이터를 제어하는 명확한 방법을 제공하지 않습니다.
운영 환경에서는 특정 시간에 발생한 이벤트가 시스템에 늦게 도착하는 경우가 있습니다. 이때 원래 속해야 하는 윈도우 처리용 배치가 이미 시작되었다면 다른 윈도우 처리용 배치에서 이벤트가 처리 됩니다. 구조적 스트리밍에는 이런 현상에 대한 해결책이 있습니다.
이벤트 시간과 상태 기반 처리를 사용하면 특정 윈도우의 상태나 데이터셋이 처리 윈도우에서 분리됩니다. 이는 더 많은 이벤트가 유입될수록 구조적 스트리밍이 더 많은 정보를 이용해 윈도우를 계속 갱심함을 의미 합니다.
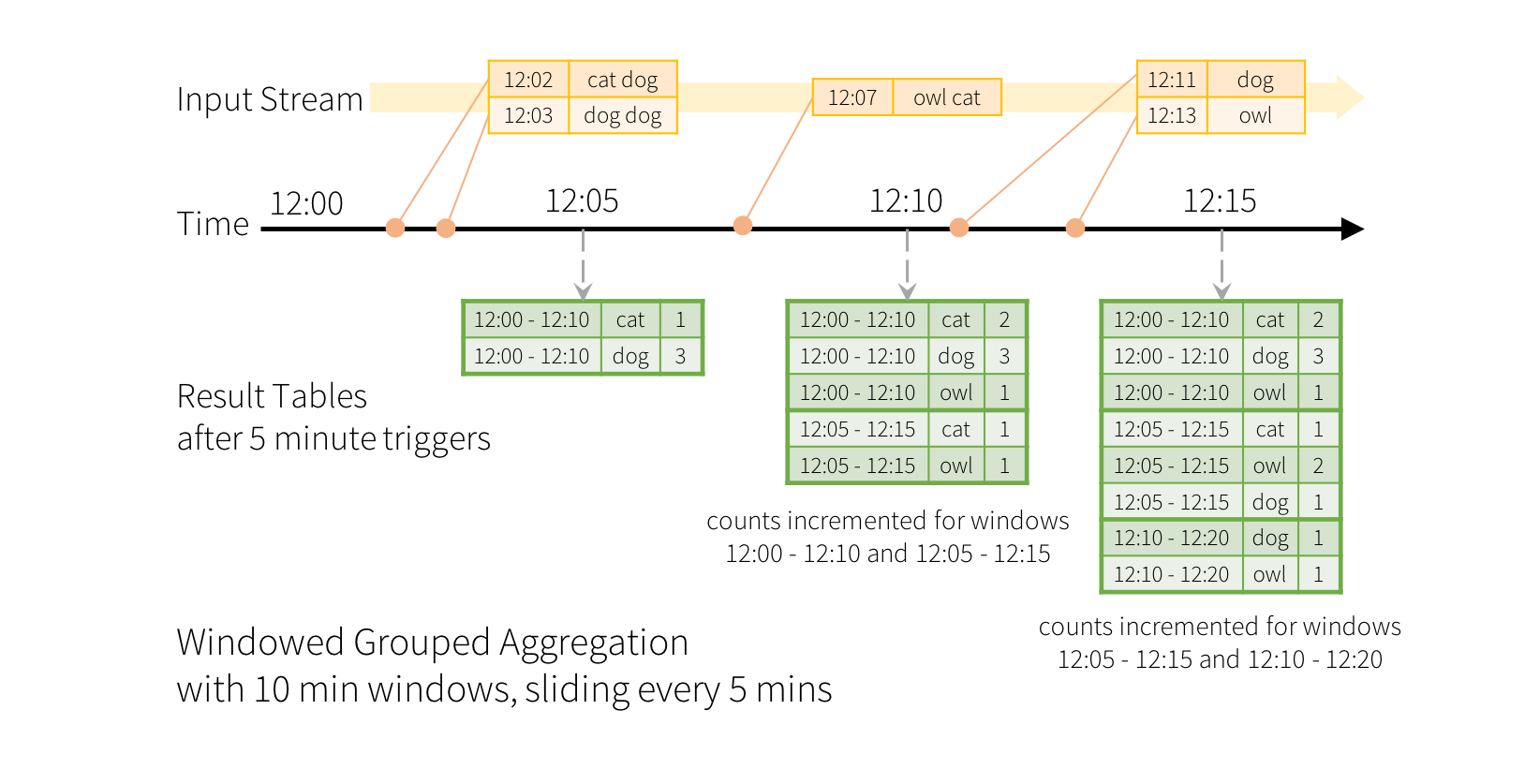
먼저 스트림 데이터를 처리한다는 것은 시간의 흐름, 이벤트에 따라 처리 하는 것입니다.
위의 그림에서와 같이 이벤트가 발생하고 시간마다 집계를 하여 데이터를 볼 수 있습니다.
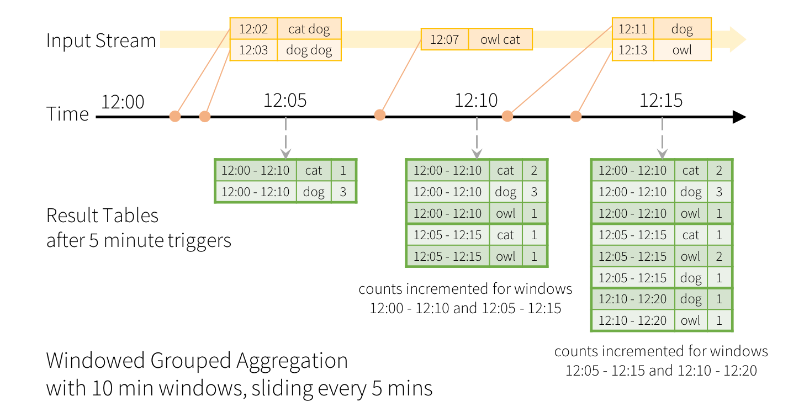
그러나 위와 같이 시스템상 또는 기타 문제로 데이터의 지연이 발생하면 이전의 데이터가 정확하지 않으므로 업데이트를 해줘야합니다.
이 때 Spark 에서는 이전 데이터들을 보관하여 정확한 데이터를 위해 업데이트 해줄 수 있습니다.
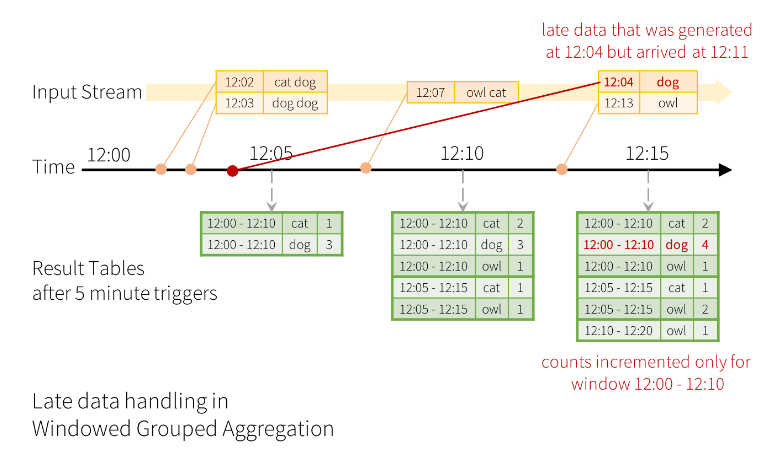
그러나 보관 주기를 지정하지 않으면 당연하게도 시스템에 악영향을 미칠 수 있는데, 이 때 Spark 에서는 보관 주기를 설정할 withWatermark() 메소드를 제공하고 있습니다.
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()위와 같이 워터마크를 10분으로 설정하게 되면 10분 이전의 데이터들은 더이상 저장해두지 않습니다.
5. 중복 제거
불안한 네트워크 환경에서 메시지를 생성하는 IoT 애플리케이션과 같이 메시지를 여러번 받는 경우에는 반드시 중복제거가 필요합니다.
중복 제거는 여러 레코드를 반드시 한 번에 처리 해야하므로 처리 시스템에 부하를 발생시키지만 매우 중요한 기능입니다.
아래와 같이 dropDuplicates 를 활용하여 중복을 제거할 수 있습니다.
wihtEventTime \
.withWatermark("timestamp", "10 minutes") \
.dropDuplicates("id", "timestamp") \
...6. 맺음말
스트리밍 처리에 대해서 단순히 밀려오는 데이터를 저장한다라고 생각하기 보다는 더욱 정교하게 작성하기 위해 중복제거, 지연 데이터 처리등 다양한 옵션들을 생각해야 함을 배울 수 있었습니다.
