들어가며
오늘 이야기는 딥러닝과 신경망에 대한 이야기이다.
학습 목표
- 딥러닝과 머신러닝의 차이를 설명할 수 있다.
- 딥러닝은 특히 데이터를 '표현'하는 것을 목표로 하며, '표현 학습'이라고 이야기할 수 있는 본질을 이해한다.
- 연결주의를 계승하여 채택한 신경망 모델의 본질을 함수 차원에서 이해한다.
- 선형성이 무엇인지 설명할 수 있다
학습 내용
- Deep Learning == Representation Learning ?
- 조금 더 파고들어보자, 딥러닝을 관통하는 철학 속으로
- 이번에는 '신경망', 그 본질에 대하여
- 현시대 AI: 어디까지 왔나, 그리고 어디를 향해 가는가
Deep Learning == Representation Learning? (1) Deep Learning
인공지능, 머신러닝, 딥러닝 정의
- 인공지능: 기계가 자체 규칙 시스템을 구축하는 과학을 말함
- 머신러닝: 데이터를 통해 스스로 학습하는 방법론을 말함
- 딥러닝: 뇌의 신경 구조로부터 영감을 받아 신경망 형태로 설계된 딥러닝의 목표는, '합성된 함수를 학습시켜서 풍부하면서도 유용한 '내재적 표현'을 찾아내는 machine을 구축하는 것'이다.
- Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions
- internal representation 즉 '내재적 표현'은 딥러닝에서 중요하게 여겨지는 개념이다.
Deep Learning == Representation Learning ? (2) Representation Learning

https://www.pngflow.com/ko/free-transparent-png-hnagg
우리 눈에 꽃의 이미지가 보인다. 우리는 이 데이터를 다양한 방법으로 표현할 수 있다.
- 분자 형태
가공되지 않은, 데이터 형태 그대로의 표현 - 이미지
분자 형태 데이터보다는 조금 가공된 형태.('시각적 표현') - 표
해당 데이터의 특징을 각 열에 나타내고, 해당 열마다 가지는 값을 표 형식으로 나타낸다. - 카테고리
머신러닝에서 주로 '예측하고자 하는 값'으로 사용되기도 함. 사람의 개입이 매우 강하게 들어간다.
위 네 가지 표현 방법은 아무 관련이 없어 보일 수 있지만, 사실은 계층적(Hierarchical)인 관계를 가지고 있다.
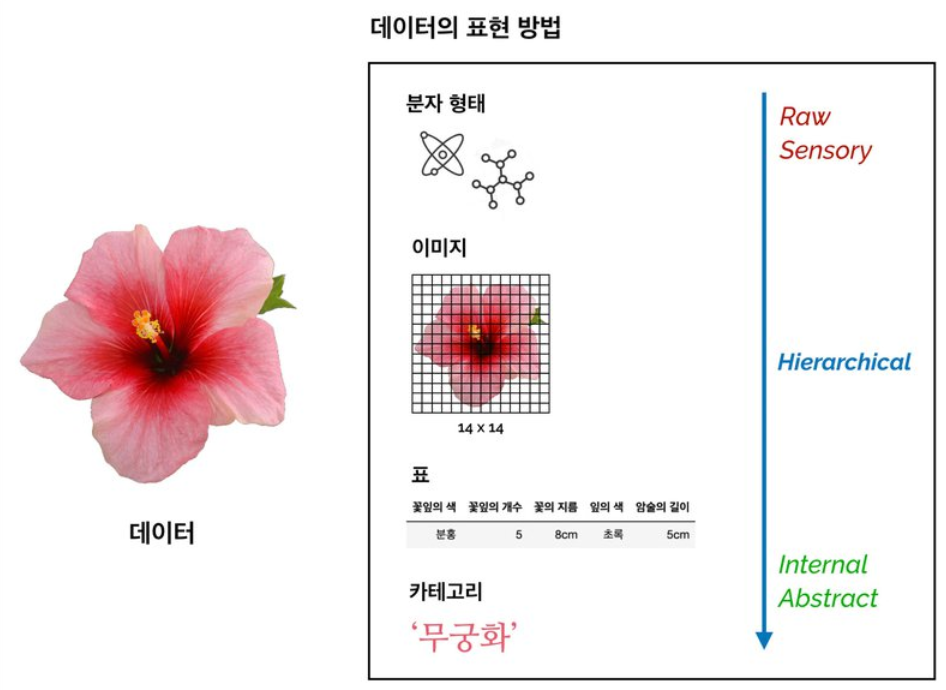
분자/이미지의 표현은 Raw, Sensory한 표현이고, 표와 카테고리는 Abstract, Internal한 표현들이다.
✔ 데이터의 내재된 표현, 데이터로부터 좋은 표현을 추출한다는 것의 의미
데이터 내재된 표현이란, 해당 데이터가 담는 정보의 총체, 혹은 함의를 나타내는 표현을 말한다.
이런 맥락에서 데이터로부터 표현을 추출해낸다는 것은 데이터 안에 내재되어 있는, 추상적인 표현을 추출한다는 것을 의미한다.
딥러닝을 관통하는 철학 (1) 행동주의
행동주의는 심리학을 과학적으로 접근하고자 하는 시도를 가진 분야로, 철저하게 경험적이고 실증적으로 인간의 내면을 접근하고자 하였다.
따라서 무의식과 같이 관찰될 수 없는 것을 배제하였으며, 인간의 행동은 자극으로부터 직접적으로 만들어진다고 주장하였다.
'자극 -> 행동'의 흐름에 따라, 인간의 지능 및 내면은 살아가면서 받는 자극으로 형성되는 후천적인 것이라고 주장하였다.
딥러닝을 관통하는 철학 (2) 인지주의
인지주의는 '자극 -> 행동'의 관계만 설명하던 행동주의에 대해 반발하며 자극 -> (정보처리) -> 행동의 관점을 제시하였다.
인간의 행동이 단순히 자극으로부터 만들어진다는 주장으로 인간의 '의식'을 부정했던 행동주의와 달리, 인지주의는 인간이 자극을 받은 후 내면에서 정리를 처리하고 가공하는 의식이 존재함을 주장하였다.
즉, 인지심리학은 인간의 마음을 일종의 정보처리 쳬계로 보고 접근하고, 이에 따라 인간의 뇌가 정보를 처리하는 과정에 관심을 신경과학이라는 새로운 분야를 만들어낸다.
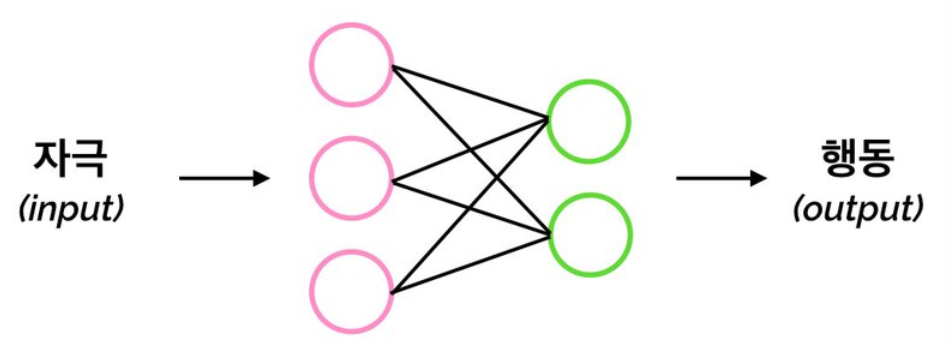
딥러닝을 관통하는 철학 (3) 연결주의
연결주의: 정보처리는 뇌에 있는 수많은 뉴런의 연결고리를 통해 이루어진다
연결주의는 몇 백억 개의 뉴런이 연결되어 있는 뇌의 형태처럼, 수많은 신호들이 연결된 일련의 과정에 따라 정보가 처리된다고 본다.
- 연결주의는 자극으로부터 반응을 하기까지의 과정에서 뉴런과 같이 연결되어 있는 모형이 정보를 처리해 나간다고 설명한다.
- 연결주의의 지능체는 처음에는 '백지' 상태이며, 다수의 사례를 주고 '경험'함으로써 스스로 천천히 '학습'해간다.
- 즉, 학습된 내용은 연결된 뉴런 자체에 저장되어 있으며, 외부에서 자극을 받음에 따라 그 연결 형태가 바뀌면서 학습된 내용이 바뀌어간다.
신경망의 본질 (1) 개요
'신경망', 그 본질에 대하여
딥러닝은 데이터를 입력받으면 일련의 정보처리 과정을 통해 여러 가지 방법으로 데이터를 표현하다가 원하는 형태로 출력하는 것을 목표로 한다는 것을 알았습니다.
그림으로 나타내면 다음과 같죠.

특히 여기서 딥러닝은 연결주의 모형에 따라, 블랙박스에 해당하는 모형을 뇌와 닮은 신경망으로 채택하였다.
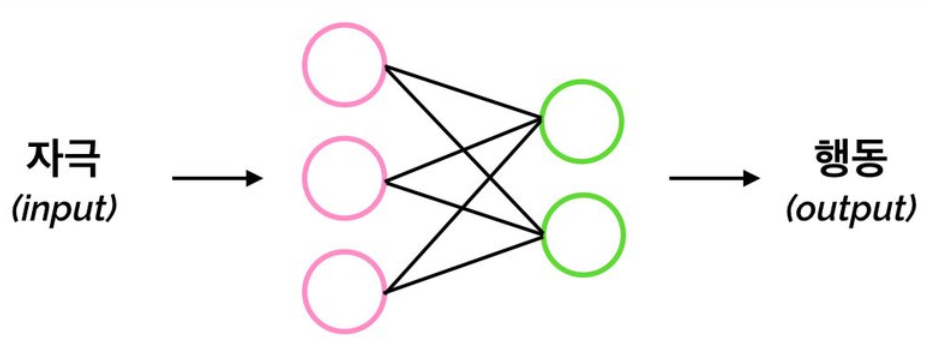
어떤 입력을 받으면 신경망 내부에서 처리 과정을 거쳐 출력을 만들어낸다.
이 형태는 우리가 배워온 함수와 같다!
신경망의 본질 (2) 수학과 프로그래밍의 "함수"
수학에서의 함수와 프로그래밍에서의 함수, 다르지 않다.
프로그래밍과 수학 모두 그 본질이 다르지 않다.
두 가지 다 아래와 같이 입력, 내부 연산, 출력이라는 형태를 가진다.

신경망의 본질 (3) 함수의 역할 - 상
함수의 본질을 이해했다면, 이번에는 함수의 역할을 다양하게 이해해보자.
1. 함수의 역할 첫 번째, Relation: x와 y의 관계를 나타낼 수 있는 도구
y가 x의 함수라는 말은,
- y는 x의 변화에 종속적이다. 즉 x가 변하면 그 변화하는 정도에 따라 y가 변하게 된다.
- x의 변화량에 따른 y의 변화량은 x와 y 간 함수의 형태로 결정된다.
함수는 x,y 사이에 매우 강한 종속적 관계를 가지게 한다.
2. 함수의 역할 두 번째, Transformation: x를 변환해 주는 도구
함수의 역할 두 번째는 x를 변환해 주는 도구라고 할 수 있다.
함수를 Transformation의 관점에서 볼 때, 우리가 필수적으로 이해해야 하는 개념은 바로 Linear Transformation이다.
- 2차원 평면에서의 Transformation은 축(grid)을 '옮기는(move)' 역할을 한다. 어떤 변환을 하냐에 따라 수직과 수평이었던 2차원 축을 옮길수도, 휘게 할 수도, 꼬이게 할 수도 있다.
- Tranformation 중 특히 Linear Transformation이 되려면 두 가지 조건을 만족해야 한다.
- 변환된 축은 여전히 '직선' 형태를 띄어야 한다. 즉, 휘거나 구부러지면 안된다.
- 변환 후에도 원점(origin)은 이동하지 않아야 한다. 즉, 원점은 그대로여야 한다.
신경망의 본질 (4) 함수의 역할 - 하
3. 함수의 역할 세 번째, Mapping: x의 공간에서 y의 공간으로 매핑해주는 도구
마지막으로 함수를 x공간에서 y공간으로 매핑(Mapping) 해주는 도구라는 관점에서 접근해보자.
-
스칼라: '크기'만 가지고 '방향'은 가지지 않는 양이다. 주로 단 하나의 숫자로 표현한다.
위키백과- 스칼라 -
벡터: '크기'와 '방향'을 두 가지 가지는 양이다. 주로 여러 개의 숫자로 표현되며, 좌표 상에서 길이와 방향을 가지는 화살표로 표현한다.
위키백과- 벡터
✓ One-to-One
✓ Many-to-One
✓ Many-to-Many
신경망의 본질 (5) 함수와 모델
우리가 배운 함수와, 앞으로 다룰 '모델'이라는 함수가 다른 점
함수와 모델의 차이점
지금까지 우리가 알고 있는 친숙한 형태의 함수와, 앞으로 받아들일 '신경망', 혹은 신경망 외의 '머신러닝 모델' 등 형태의 함수가 어떻게 다른지 생각해보자.(머신러닝/딥러닝에서 데이터를 입력받아 원하는 값을 예측하거나, 원하는 형태로 데이터를 표현하여 출력하는 모든 모든 함수를 '모델'이라고 칭한다.)
수학에서 다루는 함수는 그 형태가 고정되어 있는 경우가 대부분이다. 하지만, 머신러닝 혹은 딥러닝에서 다루어야 하는 함수는 정확히 단 하나로 정해져있는 함수도 아닐뿐더러, 그 함수가 이차 함수인지, 삼차 함수인지, 혹은 신경망 형태로 나타날지조차 알지 못한다.
우리에게 주어진 것이라곤 데이터 뿐이다.
머신러닝과 딥러닝은 '완벽한 함수'를 찾는 수학 문제를 푸는 것이 아니라, '그나마 가장 잘 근사할 수 있는 함수'에 조금씩 가까워지도록 시도하는 것에 가깝다.
그나마 나은 함수를 찾기 위해
우리가 '그나마 가장 잘 근사할 수 있는 함수'를 찾기 위해 할 일은 두 가지이다.
1. 먼저, 모델을 어떤 함수로 나타낼 것인지를 정해야 한다.
여러 모델 중 어떤 함수를 채택하느냐는 모델의 최종 성능에 굉장히 중요한 영향을 미친다.
어떤 데이터에 대한 문제를 풀기 위해 '이러한 형태의 함수가 유리할 것'이라고 판단하고 함수 공간을 정하는 것을 Inductive Bias 혹은 Prior를 가정한다고 한다.
Inductive Bias란 데이터를 설명할 수 있는 최적의 함수가 특정한 함수 공간 존재할 것이라는 가설을 말한다.
✔ Inductive Bias가 중요한 이유는 우리가 학습시킬 모델이 세상의 모든 데이터를 볼 수 없기 때문이다. 모델이 학습하는 과정에서 보지 못한 데이터에 대해서도 예측을 잘 하려면, 일반적인 패턴을 잘 반영할 수 있는 형태의 모델이어야 한다. 그렇기에 어떤 문제를 풀고자 할 때 알맞은 함수 형태로 모델을 선택하는 것은 그 데이터에 대한 도메인 지식을 가지고 있는 사람의 몫이며, 더 좋은 모델을 찾기 위해서는 그 데이터에 알맞은 함수 공간, 즉 Inductive Bias를 잘 설정하는 것이 중요하다.
2. 모델의 함수 형태를 정했다면, 해당 함수 공간 안에서 최적의 함수를 찾아나간다.
모델을 어떤 함수로 형태로 사용할 것인지 정했다면, 그 후로는 그 함수 공간 안에서 찾을 수 있는 최적의 함수로 학습을 해 나간다.
이 단계가 보통 머신러닝/딥러닝에서 말하는 '모델 학습'에 해당한다.
머신러닝 모델을 '학습'시킨다는 것은, 처음에는 데이터를 입력받아 전혀 엉뚱한 값을 내뱉던 모델을, 점점 정답에 해당하는 값을 출력할 수 있도록 '보정'해나가는 과정이라고도 할 수 있다.
데이터를 잘 표현/예측할 수 있는 모델(함수)를 찾아내기 위한 두 가지 단계는 무엇인가?
1. 첫 번째는, 모델을 어떤 함수로 형태로 나타낼 것인지 함수 공간을 정하는 단계이다. 이 과정에서 Inductive Bias가 발생한다.
2. 함수 공간을 정했다면 그 안에서 최적의 함수를 찾아 학습한다. 신경망의 경우 경사하강법과 같은 방법으로 점차 최적의 함수로 학습될 수 있다.
Inductive Bias란 무엇인가?
- Inductive Bias란, 데이터를 설명할 수 있는 최적의 함수가 특정한 함수 공간에 존재할 것이라는 가설을 말한다.
- 모든 데이터는 그 데이터가 무엇이냐에 따라 잘 표현/예측할 수 있는 함수의 형태가 다르다. 데이터에 대한 도메인 지식을 활용하면 데이터를 가장 잘 표현할 수 있는 함수는 어떤 형태일 것이라는 가설을 세울 수 있습니다. 더 좋은 모델을 만들기 위해서는 좋은 Inductive Bias가 필요하다.
AI의 현재와 미래 (1) 머신러닝과 딥러닝
머신러닝과 딥러닝은 어떻게 다른가?
- 머신러닝은 주어진 데이터로부터 패턴을 학습해서 원하는 값을 예측하는 데에 방점이 있다면,
- 딥러닝은 입력된 데이터에 내재되어 있는 표현 그 자체를 나타내도록 학습하는 것이 목표이다.
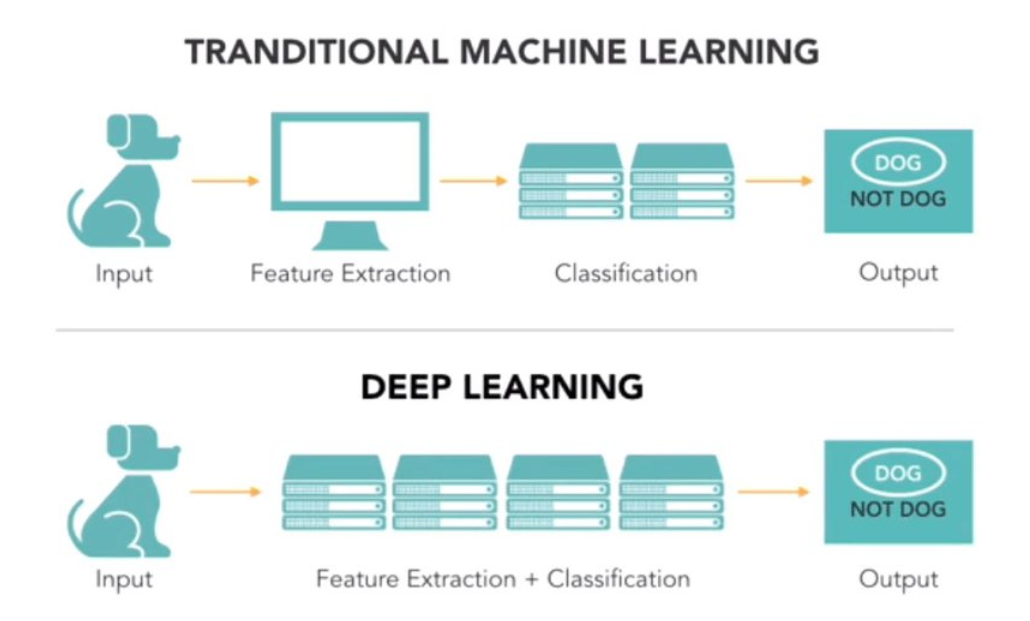
기존의 머신러닝은 사람이 직접 feature를 가공해주어야 했다. 왜냐하면 전통적인 머신러닝 모델들은 주로 '표' 형태로 된 정형 데이터를 처리하도록 설계되었기 때문이다.
한편, 딥러닝은 모델의 복잡성을 늘려 사람이 개입하는 피처 엔지니어링을 최소화하고자 한다. 이미지라면 2차월 배열을 그대로 신경망에 입력하면, 알아서 그 안에 있는 특징/표현을 학습하게 한다.
- linear model: 직선의 형태로 정의되는 러닝 모델. 이는 가장 단순한 러닝 모델에 해당한다.
- 퍼셉트론: 선형 함수와 그 결과를 비선형 함수 활성화 함수까지 거치는 합성 함수라고 할 수 있다.
- 다층 퍼셉트론: 퍼셉트론은 세 개의 층으로 이루어진다. 입력 벡터가 자리잡는 층을 input layer, 최종 출력값이 자리잡는 층을 output layer, 입력층과 출력층 사이에 위치하는 모든 층을 은닉층(hidden layer)라고 한다. 이떄 퍼셉트론을 기본 빌딩 블록으로 하여, 이런 패턴에 따라 2차원적으로 연결되어 구성되는 인공신경망의 일종을 특별히 다층 퍼셉트론(MLP: multi-layer perceptron)이라고 한다.
- 심층 신경망: 다층 퍼셉트론에서 은닉층의 개수가 많아질수록 인공신경망이 '깊어졌다(deep)'고 부르며, 이렇게 충분히 깊어진 인공신경망을 러닝 모델로 사용하는 머신러닝 패러다임을 바로 딥러닝(Deep Learning)이라고 한다. 이때 딥러닝을 위해 사용하는 충분히 깊은 인공신경망을 심층 신경망(DNN:Deep neural network)이라고 한다.
- 딥러닝의 강점: '요인 표현 학습' 능력을 가지고 있으며, 이는 원본 데이터로부터 최적의 성능을 발휘하는 데 사용될 수 있는 요인 표현 방법을 스스로 학습하고, 이를 기반으로 최적의 성능을 발휘하는 가중치를 더욱 효과적으로 찾는 능력을 말한다.
- 딥러닝의 약점: 딥러닝 모델이 효과적으로 학습하기 위해서는 굉장히 많은 데이터가 필요하며, 학습 연산량이 매우 높아 학습 시간이 오래 걸린다는 것이 약점이다.
