컴파일러 공통 과정
컴파일러가 컴파일 하는 과정은 여러 단계로 이루어져 있으며, 컴파일러의 종류에 따라 다르다.
하지만 공통적으로 수행하는 과정이 존재한다.
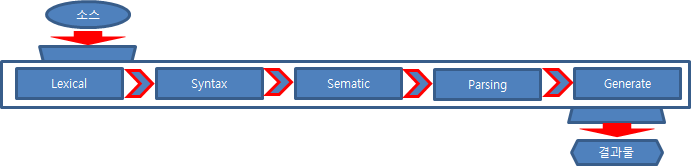
컴파일러는 어휘 분석(Lexical) → 구문 분석(Syntax) → 의미 분석(Semantic) → 파싱(Parsing) → 중간 코드 생성 (Midi Code Generation) 과정을 거친다.
컴파일러에 따라 최적화(Optimization) 과정을 거칠 수도 있으며 각 과정을 반복해서 수행하기도 한다.
각각의 단계는 다음과 같다.
어휘 분석(Lexical) 단계
입력 문장에 의미있는 최소 단위인 토큰(Token)을 만드는 과정으로 토큰 생성기에서 수행한다.
만약 사용할 수 없는 토큰을 발견하면 오류로 처리한다.
구문 분석(Syntax)
토큰의 배치가 문법에 맞게 배치하였는지 확인하며 구문 분석기에서 수행한다.
만약 배치 순서에 문제가 있으면 오류로 처리한다.
의미 분석(Semantic)
자료 형식이 논리에 맞는지 확인하며 의미 분석기에서 수행한다.
즉, 형식에 맞지 않는 값을 대입하거나 비교하는 부분이 있는지 점검하는 것이다.
파싱(Parsing)
입력 구문의 각 토큰을 번역 결과물로 만들기 위한 과정으로 파서(Parser)에서 수행한다.
파서는 다양한 형태로 표현할 수 있는데 정규화를 할 수 있을 때 파서 트리(Parser Tree)로 구현하면 효과적이다.
중간 코드 생성(Midi Code Generation)
파싱한 결과물로 목적 파일을 만드는 과정입니다.
파서(Parser)
위 파싱(Parsing) 단계를 수행하는 것으로 입력 토큰에 내재된 자료 구조를 빌드하고 문법을 검사한다.
파서는 일련의 입력 문자로부터 토큰을 만들기 위해 별도의 낱말 분석기를 이용하기도 한다.
파서가 사용하는 대표적인 자료구조로 파서 트리(Parser Tree)가 있다.
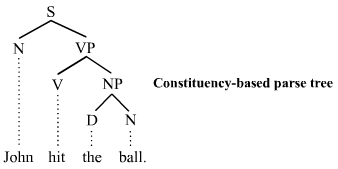
파서 트리(Parser Tree)
파스 트리(parse tree)는 파싱 트리(parsing tree), 어원 트리(derivation tree), 구체적인 구문 트리(concrete syntax tree) 라고도 하며, 올바른 문장에 대해 트리 구조로 나타낸 것을 말한다.
파서 트리 중 하나
파서의 종류
파서는 크게 두 가지 방식이 존재한다.
- 하향식 파서(top-down parser): 구문의 상위 구조로부터 일치하는 부분을 찾는 방식
- 상향식 파서(bottom-up parser): 낮은 수준에서 점차 높은 수준으로 차는 방식
또한 2가지 파생(Derivation) 유형이 존재한다. 파생은 문법이 입력 문자열을 조정하는 순서이다.
- LL parser: 하향식 파서로, 문법의 규칙을 입력과 일치시키기 위해 왼쪽에서부터 파싱을 해서 좌측유도(Leftmost Derivation) 방식으로 동작한다.
- LR parser: 상향식 파서로, 왼쪽에서 파싱을해서 우측유도(Rightmost Derivation) 방식으로 동작한다.
이외에도 다양한 파서가 존재한다.
토큰의 정규화
파서 트리를 만들기 전에는 토큰의 정규화가 필요하다.
정규화는 같은 종류의 표현을 묶어 간소화 하는 과정이다.
정규화 표현은 다양하게 존재하지만 대표적인 정규화 표현으로는 배커스-나우어 형식(Backers Naur Form, BNF)가 있다.
BNF
BNF 표기법은 Backus Naur Form의 약자로 존 배커스와 나우르가 만든 표기법으로 문맥 자유 문법을 나타내기 위해 만들어진 표기법이다.
<기호> ::= <표현식>단말 표현과 비단말 표현 및 기호를 이용하여 문장 생성 과정을 유도한다.
- 단말 표현: 더 이상 유도할 수 없는 표현(ex> 1, 2, …, +, -, *, / 등)
- 비단말 표현: 유도가 가능한 표현으로
<digit>처럼<>를 이용하여 표현한다.
예를 들어 16진수를 표기하는 BNF 표기법은 아래와 같다.
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<hex_letter> ::= A | B | C | D | E | F
<hex> ::= <digit> | <hex_letter>연산자
-
|or을 의미0 | 1 | 2(0 or 1 or 2)
-
-: 뺄셈의 의미로 항목 제거의 의미로도 해석할 수 있다.<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 <pre-half-digit> ::= 0 | 1 | 2 | 3 | 4 <post-half-digit> ::= <digit> - <half-digit> <post-half-digit> ::= 5 | 6 | 7 | 8 | 9 -
*: 0개 이상<string> ::= <character>* // 문자열을 빈 문자열(문자열이 0개)도 포함하므로 문자열이 0개 이상이다. -
+: 1개 이상<integer> ::= <digit>+ // 정수는 1개 이상의 숫자로 이루어져있다. -
?: Optional<oct-digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 <oct> ::= 0?<oct-digit // 8진수 표기법은 헷갈리지 않게 04 와 같이 표기하지만, 0이 없다고 해서 8진수가 아니라고 말할 수는 없을 것이다.
참고자료
https://ko.wikipedia.org/wiki/%EA%B5%AC%EB%AC%B8_%EB%B6%84%EC%84%9D
https://ehpub.co.kr/9-3-%ec%88%98%ec%8b%9d-%ed%8c%8c%ec%84%9c-%ed%8a%b8%eb%a6%acnumeric-parser-tree/
https://www.techtarget.com/searchapparchitecture/definition/parser
https://gusdnd852.tistory.com/316?category=746565
https://perfectacle.github.io/2018/08/15/bnf/
