정보처리기사 실기 정리 - 3. 데이터 입출력 구현
Chapter01 논리 데이터 저장소 확인 (중요도: ★★★)
◆ 데이터 모델(Data Model)
: 현실 세계의 정보를 인간과 컴퓨터가 이해할 수 있도록 추상화하여 표현한 모델
◆ 데이터 모델 절차(요개논물)
: 요구사항 분석 → 개념적 설계 → 논리적 설계 → 물리적 설계
◆ 논리 데이터 모델링
: 업무의 모습을 모델링 표기법으로 형상화하여 사람이 이해하기 쉽게 표현하는 프로세스
- 개념적 모델링 과정에서 얻은 개념적 구조를 컴퓨터가 이해하고 처리할 수 있는 컴퓨터 세계의 환경에 맞도록 변환하는 과정
- 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계를 이용하여 현실 세계를 표현한다. - 단순히 데이터 모델이라고 하면 논리적 데이터 모델을 의미한다.
- 특정 DBMS는 특정 논리적 데이터 모델 하나만 선정하여 사용한다.
- 데이터 간의 관계를 어떻게 표현하느냐에 따라 관계 모델, 계층 모델, 네트워크 모델로 구분한다.
◆ 논리적 데이터 모델링 종류
- 관계 데이터 모델: 테이블 형태, 1:1, 1:N, N:M
- 계층 데이터 모델: 트리 형태(상하 관계), 1:N
- 네트워크 데이터 모델: 그래프 형태, N:M
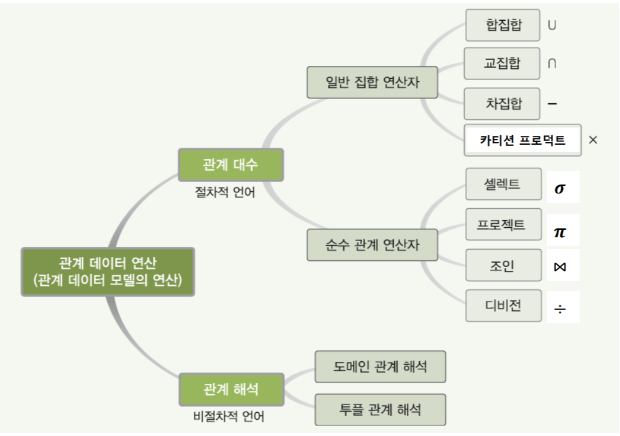
◆ 관계 대수
: 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적 정형 언어 (정보 검색 유도 기술 절차적 정형언어)
◆ 관계 대수 연산자 종류
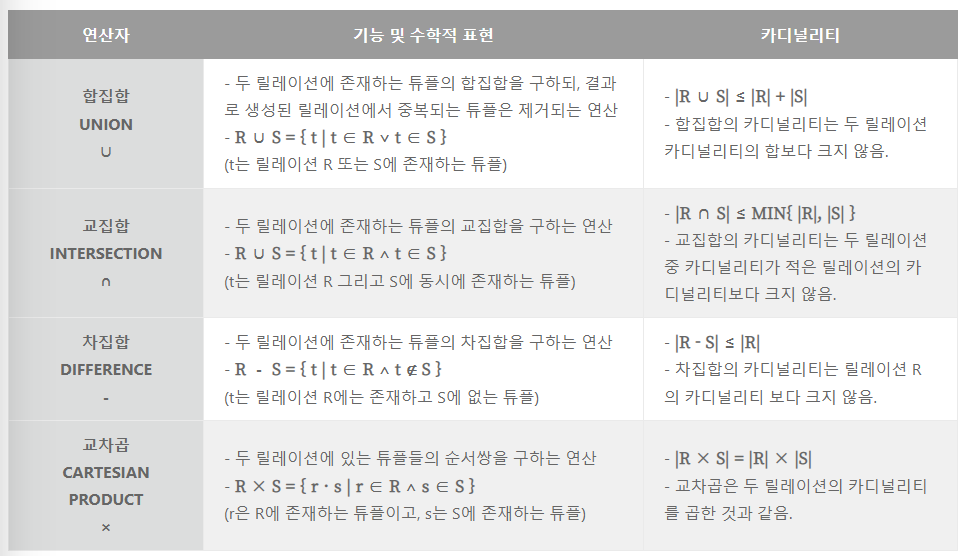
일반 집합 연산자(합교차카)
- 합집합(Union): ∪
- 교집합(Intersection): ∩
- 차집합(Difference): -
- 카티션 프로덕트(CARTESIAN Product): ×
순수 관계 연산자(셀프조디)
- 셀렉트(Select): σ
- 프로젝트(Project): π
- 조인(Join): ⋈
- 디비전(Division): ÷

◆ 관계 해석
: 튜플 관계해석과 도메인 해석을 하는 비절차적 언어
◆ 논리 데이터 모델링 속성(개속관)
- 개체(Entitiy) : 데이터베이스에 표현하려는 것으로, 사람이 생각하는 개념이나 정보 단위 같은 현실 세계의 대상체
- 속성(Attributes) : 데이터베이스를 구성하는 가장 작은 논리적 단위 (디그리 Degree)
- 관계(Relationship) : 개체와 개체 사이의 논리적인 연결, 개체 간의 관계와 속성 간의 관계가 있다.
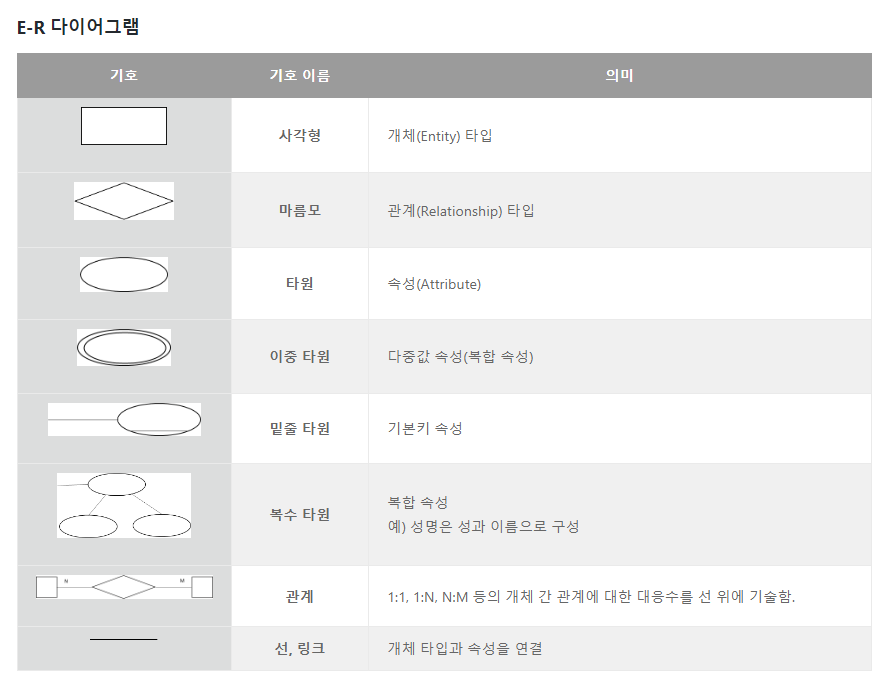
◆ 개체-관계(E-R) 모델
: 데이터와 그들간의 관계를 사람이 이해할 수 있는 형태로 표현한 모델
- E-R다이어그램 기호
◆ 정규화(Normalization)
: 데이터 모델에서 데이터의 중복성을 제거하여 이상 현상을 방지하고, 데이터의 일관성과 정확성을 유지하기 위해 무손실 분해하는 과정
◆ 이상현상(Anomaly)(삽삭갱)
: 데이터의 중복성으로 인해 릴레이션을 조작할때 발생하는 비합리적 현상
- 삽입이상: 불필요한 세부정보 입력 하는 경우
- 삭제이상: 원치 않는 다른 정보가 같이 삭제되는 경우
- 갱신이상: 특정부분만 수정되어 중복된 값이 모순을 일으키는 경우
◆ 정규화 단계(원부이결다조)
- 1정규형(1NF): 도메인이 원자값으로 구성
- 2정규형(2NF): 부분함수 종속제거 (완전 함수적 종속을 만족)
- 3정규형(3NF): 이행함수 종속제거
- 보이스-코드 정규형(BCNF): 결정자 후보 키가 아닌 함수 종속 제거
- 4정규형(4NF): 다중 값 종속제거
- 5정규형(5NF): 조인 종속 제거
◆ 반정규화(De-Nomalization)
: 정규화된 개체, 속성, 관계에 대해 성능향상과 개발운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링 기법
Chapter02 물리 데이터 저장소 설계 (중요도: ★★★)
◆ 참조무결성 제약조건
: 릴레이션과 릴레이션 사이에 대한 참조의 일관성을 보장하기 위한 조건
- 제한(Restricted): 다른테이블이 삭제할 테이블을 참조 중이면 제거하지 않는 옵션
- 연쇄(Cascade): 참조하는 테이블까지 연쇄적으로 제거하는 옵션
- 널값(Set Null): 참조되는 릴레이션에서 튜플을 삭제하고, 참조하는 튜플들의 외래값에 NULL값을 넣는 옵션. / 만약, NOT NULL 명시시 삭제 연산 거절됨.
ALTER TABLE 테이블 ADD
FOREIGN KEY (외래키)
REFERENCES 참조테이블(기본키)
ON DELETE [ RESTRICT | CASCADE | SET NULL ] ;◆ 인덱스(Index)
: 데이터 레코드를 빠르게 접근하기 위해 ‘키값, 포인터’ 쌍으로 구성되는 데이터 구조
- 클러스터드 인덱스(Clustered Indext): 인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식
- 넌클러스터드 인덱스(Non-Clustered Indext): 인덱스의 키값만 정렬되어 있고 실제 데이터는 정렬되지 않는 방식
◆ 뷰(View)
: 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로 구성된 가상 테이블
◆ 클러스터(Cluster)
: 데이터 액세스 효율을 향상시키기 위해 동일한 성격의 데이터를 동일한 데이터 블록에 저장하는 물리적 저장 방법. 클러스터의 분포도가 넓을수록 유리하다.
◆ 파티션(Partition)(레해리컴)
: 대용량의 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것
- 범위분할(Range Partitioning): 연속적인 숫자나 날짜을 기준으로 분할함
- 해시분할(Hash Partitioning): 해시 함수를 적용한 결과 값에 따라 데이터를 분할.
- 리스트분할(List Partitioning): 특정 파티션에 저장 될 데이터에 대한 명시적 제어가 가능한 분할 기법
- 조합분할(Composite Partitioning): 범위,해시,리스트 분할 중 2개의이상의 파티셔닝을 결합하는 방식. 파티션이 너무 클때 사용
◆ 파티션 장점(성가백합)
: 성능 향상, 가용성 향상, 백업 가능, 경합 감소
Chapter03 데이터베이스 기초 활용하기 (중요도: ★★★)
◆ 데이터베이스(Database)
: 다수의 인원, 시스템 또는 프로그램이 사용할 목적으로 통합하여 관리되는 데이터의 집합
◆ 데이터베이스 정의(통저운공)
- 통합된 데이터: 자료의 중복을 배제한 데이터의 모임
- 저장된 데이터: 저장 매체에 저장된 데이터
- 운영 데이터: 조직의 업무를 수행하는 데 필요한 데이터
- 공용 데이터: 여러 애플리케이션, 시스템들이 공동으로 사용하는 데이터
◆ 데이터베이스 특성
- 실시간 접근성: 쿼리에 대하여 실시간 응답이 가능해야 함
- 계속적인 변화: 새로운 데이터의 삽입, 삭제 갱신 으로 항상 최신의 데이터를 유지
- 동시공용: 다수의 사용자가 동시에 같은 내용의 데이터를 이용할 수 있어야함
- 내용참조: 사용자가 요구하는 데이터 내용으로 데이터를 찾음
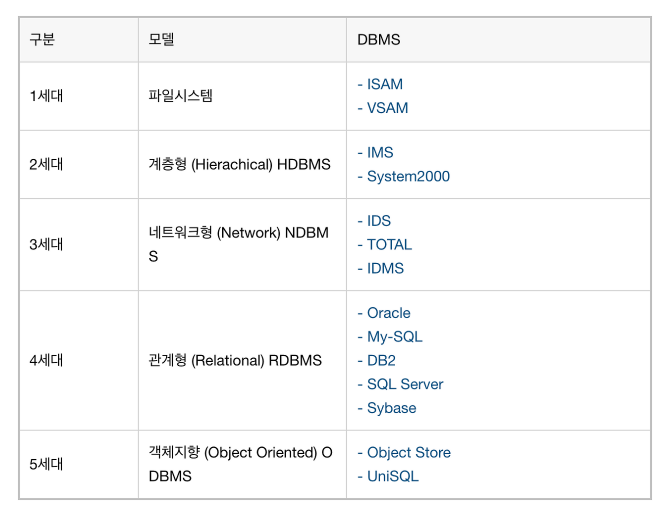
◆ 데이터베이스 종류
-
파일 시스템(File System): 파일에 이름을 부여하고 저장이나 검색을 위해 논리적으로 그것들을 어디에 위치시켜야 하는지 등을 정의한 뒤 관리하는 데이터베이스 전 단계의 데이터 관리 방식
-
계층형 데이터베이스 시스템(HDBMS): 데이터를 상하 종속적인 관계로 계층화화여 관리, 데이터의 관계를 트리 구조로 정의, 부모-자식 형태를 가짐
- 종류: IMS, System2000 등
-
네트워크 데이터베이스 관리시스템(NDBMS): 데이터를 네트워크상의 망상(노드) 형태로 표현한 데이터 모델
- 종류: IDS, IDMS 등
-
관계형 데이터베이스 시스템(RDBMS):

관계형 모델을 기반 행(Column)과 열(Row)을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스
- 종류: Orcle, SQL Server, MySQL, Mari DB 등
◆ DBMS(Database Management System)
: 데이터 관리의 복잡성을 해결하는 동시에 데이터 추가, 변경, 검색, 삭제 및 백업, 복구, 보안 등의 기능을 지원하는 소프트웨어
◆ DMBS 유형(키컬도그)
- 키-값(Key-Value) DBMS: Unique 한 키에 하나의 값을 가지고 있는 형태
- 컬럼 기반 데이터 저장(Column Family Data Store) DMBS: Key안에(Column, Value) 조합으로 된 여러개의 필드를 갖는 DBMS
- 문서 저장(Document Store) DBMS: 값(Value)의 데이터 타입이 문서(Documnet)라는 타입을 사용하는 DBMS
- 그래프(Graph) DBMS: 시맨틱 웹과 온톨로지 분야에서 활용되는 그래프로 데이터를 표현하는 DBMS
◆ DBMS 특징
: 무결성, 일관성, 회복성, 보안성, 효율성
◆ 빅 테이터(Big Data)
: 시스템, 서비스, 조직(회사) 등에서 주어진 비용, 시간 내에 처리 가능한 수십 페타바이트(PB) 크기의 비정형 데이터
-
빅데이터 특성 3V: 데이터의 양(Volume), 데이터의 다양성(Variety), 데이터의 속도(Velocity)
-
빅데이터 수집, 저장, 처리 기술
- 비정형/반정형 데이터 수집: 내/외부 정제되지 않은 데이터를 확보하여 수집 및 전송하는 기술
- 정형 데이터 수집: 내/외부 정제된 대용량 데이터의 수집 및 전송 기술
- 분산데이터 저장/처리: 대용량 파일의 효과적인 분산 저장 및 분산 처리 기술
- 분산데이터 베이스: HDFS 칼럼 기반 데이터베이스로 실시간 랜덤 조회 및 업데이트 가능
- HDFS(Hadoop Distributed File System): 대용량 데이터의 집합을 처리하는 응용 프로그램에 적합하도록 설계된 하둡 분산 파일 시스템
◆ NoSQL(Not Only SQL)(스키마x,조인연산x)
: 데이터 저장에 고정된 테이블 스키마가 필요하지 않고 조인 연산을 사용할 수 없으며, 수평적으로 확장이 가능한 DBMS
- NoSQL 특성
- Basically Available: 언제든지 데이터 접근 할 수 있는 속성
- Soft-State: 외부에서 전송된 정보를 통해 결정되는 속성
- Eventually Consistency: 일관성이 유지되는 속성
- NoSQL 유형(키컬도그)
- Key-Value Store: Unique 한 키에 하나의 값을 가지고 있는 형태
- Column Family Data Store : Key안에(Column, Value) 조합으로 된 여러개의 필드를 갖는 DB
- Document Store: 값(Value)의 데이터 타입이 문서(Documnet)라는 타입을 사용하는 DB
- Graph DBMS: 시맨틱 웹과 온톨로지 분야에서 활용되는 그래프로 데이터를 표현하는 DBMS’
- 시맨틱 웹: 온톨로지를 활용하여 서비스를 기술하고, 온톨로지의 의미적 상호 운용성을 이용해서 서비스 검색, 조합, 중재 기능을 자동화하는 웹
- 온톨로지: 실세계에 존재하는 모든 개념들과 개념들의 속성, 그리고 개념들간의 관계 정보를 컴퓨터가 이해할 수 있도록 서술해 놓은 지식베이스
◆ 데이터 마이닝(Data Minning)
: 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아내는 기술
◆ 데이터 마이닝 절차
: 목적 설정 → 데이터 준비 → 가공 → 마이닝 기법 적용 → 정보 검증
◆ 데이터 마이닝 주요 기법(분연연데)
- 분류(Classification) 규칙: 과거 데이터로를 토대로 새로운 레코드의 결과 값을 예측하는 기법
- 연관(Association) 규칙: 데이터 안에 항목들 간의 종속관계를 찾아내는 기법
- 연속(Sequence) 규칙: 연관 규칙에 시간 관련 정보가 포함된 형태의 기법
- 데이터 군집화(Clustering): 대상 레코드들을 유사한 특성을 지닌 몇 개의 소그룹으로 분할하는 작업
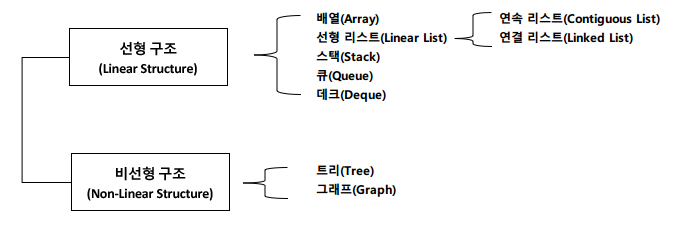
◆ 자료구조
- 자료를 기억장치의 공간 내에 저장하는 방법과 자료 간의 관계 처리 방법 등을 연구 분석 하는것