업무자동화의 필요성
- 매일 똑같은 엑셀 파일을 오전 마다 부여 받아 특정 데이터를 정리해야 한다던가,
- 특정 업체에 올라오는 새로운 상품이나, 정보를 매일매일 수집해야 한다던가 하는 일들을 반복하는 것
--> 귀찮고 비효율적
이를 우리가 구축한 서버를 통해 자동화, 즉 업무를 자동화 할 수 있다면 아주 편리할 겁니다.
위에서 언급한 업무 자동화 기술들은 보통 파이썬으로 많이 알려져 있습니다.
--> 자바스크립트 즉, Node.js로도 파이썬 업무자동화가 모두 가능합니다.
가장 대표적인
1) 웹 사이트의 데이터를 가져오는 : 크롤링
2) 엑셀 파일을 만들거나 분석/가공하는 : 엑셀 업무자동화
두 작업 모두 가능
크롤링
크롤링 = 단어 그대로 " 데이터를 긁어오는 " 것을 뜻함
웹 크롤링 = 웹 사이트의 데이터를 긁어오는 것
--> 특정 웹사이트의 정보를 주기적으로 가지고 오고 싶으면??
--> 방대한 자료가 들어 있는 특정 웹 사이트의 데이터를 한 번에 다 가져오고 싶으면??
=======> 크롤링 기술을 사용
크롤링 기술
웹 사이트는 HTML과 CSS 그리고 자바스크립트로 그림화면을 만들어 브라우저에 표현될 수 있습니다.
웹사이트 = { 브라우저에 표현됨 <== ( HTML + CSS + 자바스크립트로 구성된 그림 화면) }따라서 HTML 구조만 잘 안더라도 화면 속 정보들이 어느 태그에 들어 있는 지 쉽게 알 수 있습니다.
즉, 크롤링은
1) 기존에 공부한 HTML 태그 문법 지식을 통해 웹 사이트의 구조를 파악하고
2) 가지고 오고 싶은 데이터의 HTML 영역을 특정하여
3) 데이터를 쉽게 가져오고 조작할 수 있는 크롤링 라이브러리를 사용! 하면
가능한 기술입니다.
크롤링 준비
간단한 HTML 기본 지식 + 외부 라이브러리
크롤링 작업 순서와 연결해서 생각해보면 다음과 같은 라이브러리들이 필요합니다.
1) Node.js 서버에서 외부에 있는 특정 웹사이트에 접근 ⇒ axios
2) 특정 웹사이트 HTML 코드를 가져와 조작하기 ⇒ cheerio
3) 한글 깨짐 방지! ⇒ iconv-lite
--> 이것들이 있으면 크롤링 구현 가능
크롤링 도구 설치
npm install axios cheerio iconv-lite -s
크롤링할 사이트 분석
예시) yes24의 베스트셀러 페이지
--> http://www.yes24.com/24/Category/BestSeller
--> 먼저 해당 페이지의 도서 정보가 어떤 HTML 태그 구조로 이루어 져있는 지 파악
윈도우는 F12
맥은 alt + command + i 를 눌러 개발자 콘솔 접근
예를 들어)
요소 검색 버튼을 눌러 도서 제목을 클릭하면, 아래와 같이 도서 제목이 어떠한 태그 안에 쓰여져 있는 지 확인이 가능
.png)
--> 개발자 콘솔에서 왼쪽 위에 마우스 버튼이 요소검색 버튼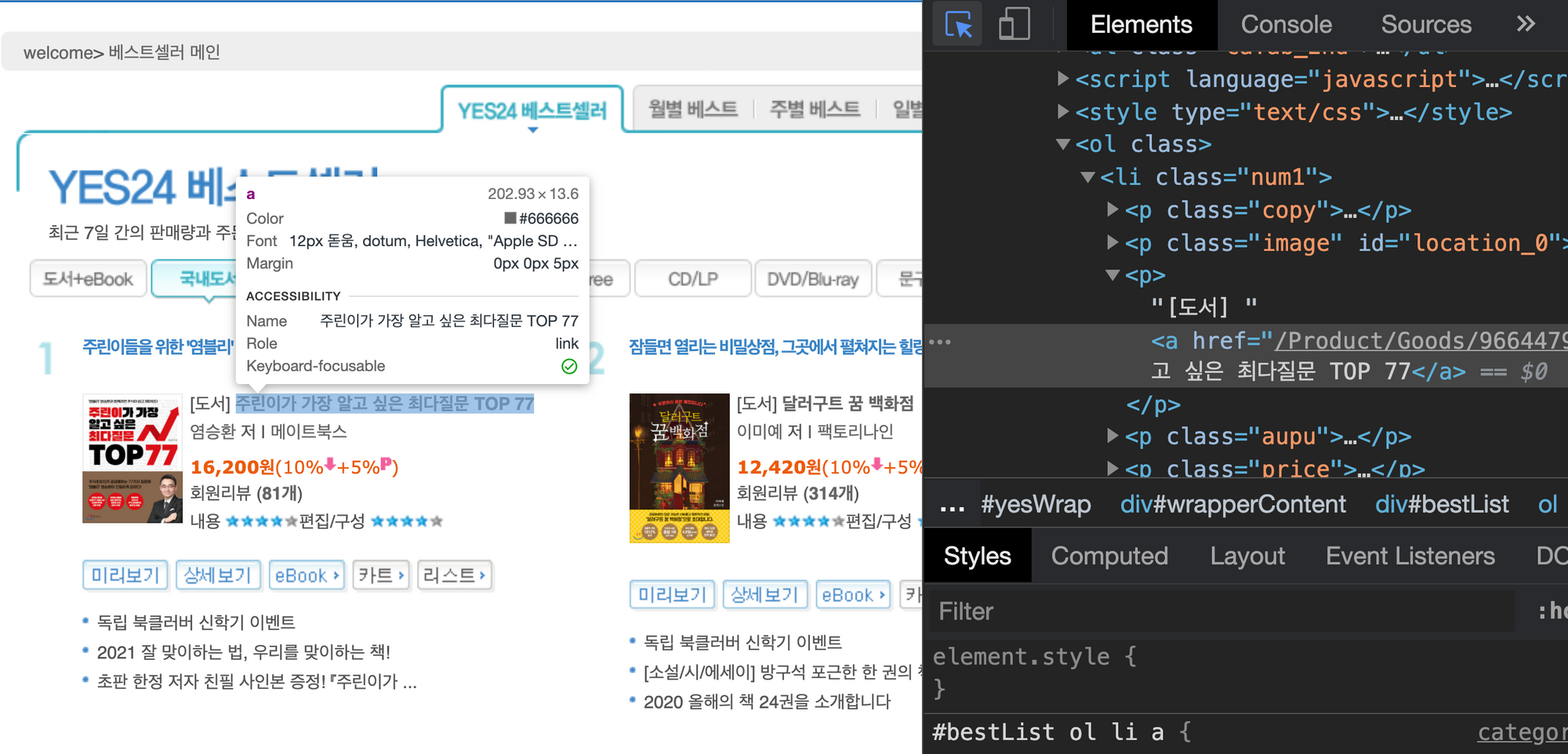
--> 이와 같은 요령으로 도서 전체에 대한 태그를 가져온다면,
아래와 같이 li 태그 안에 들어 있고, 결국 ol 태그 안에 li 태그들로 도서 정보들을 나열한 구조란 것을 확인할 수 있음
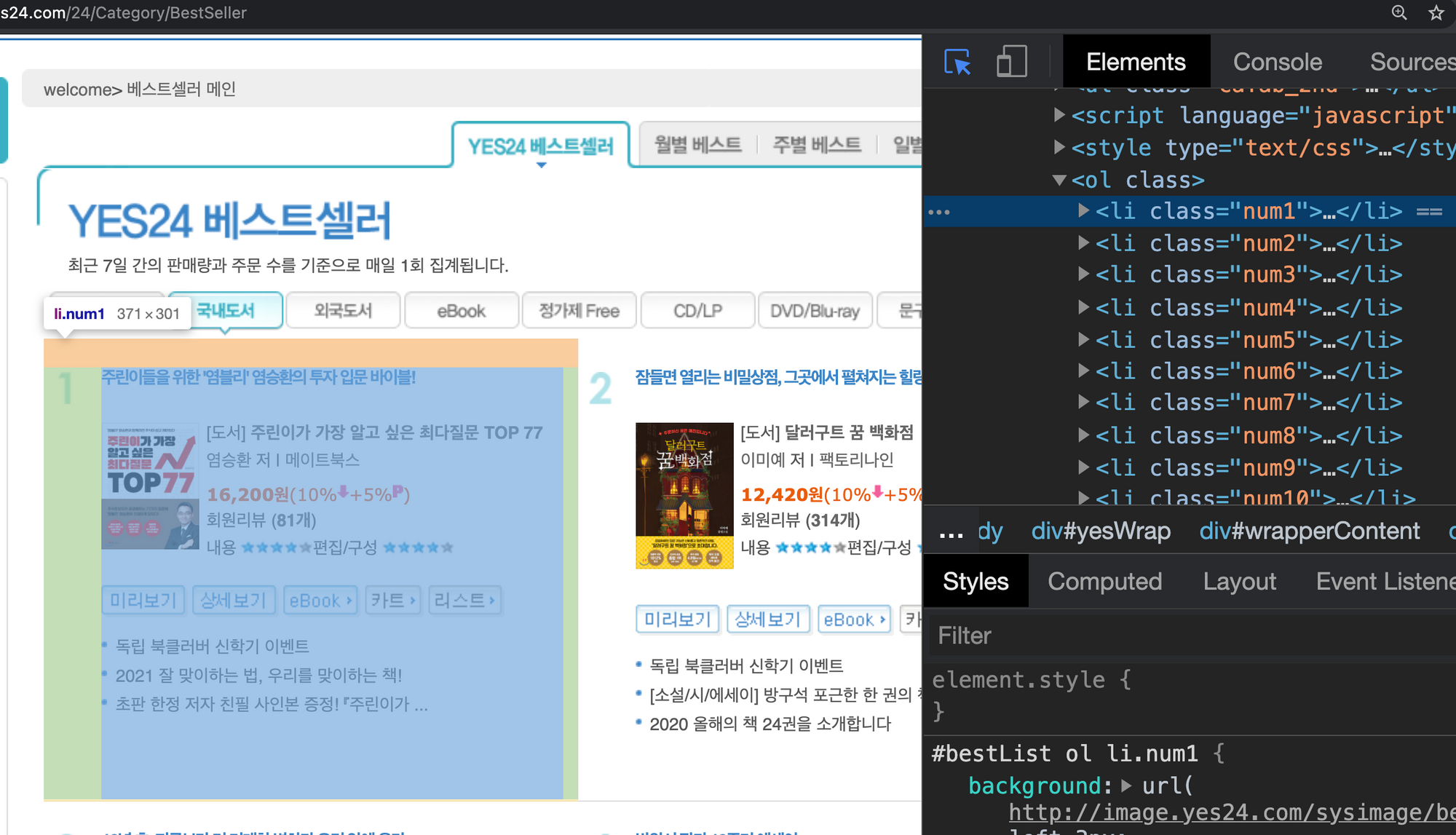
정리하자면
ol 태그 > li 태그 > p태그나 a, img 태그
순서로 접근하여 원하는 정보를 가져올 수 있음
--> 이러한 방식으로 구조를 파악하여 어떤 태그에 접근해야하며 어떻게 접근해야하는지 파악해야함
