1. TLB 캐시 (Translation Lookaside Buffer) 1수준
-
최근에 사용된 PTEs(Page Table entrys) 저장
-
속도가 메모리를 엑세스하는 속도가 아니라 CPU를 엑세스하는 속도라 매우 빠름(한번만 접근하는 것과 같은 속도를 뽑아냄)
- TLB Lookup(VPN)
- TLB가 있으면 TLB Hit이라 하고 TLB로 접근
- TLB가 없으면 TLB Miss라 하고 PTE를 직접 찾아가서 access하고 TLB에 저장하고 빠져나옴
- 그러고 다시 TLB에 다시 접근
유효 메모리 접근 시간(Teff) = h (Tb + Tm) + (1 - h) (Tb + Tm + Tm)
- TLB hit: TLB의 페이지 테이블 탐색(Tb) 후 바로 메모리 프레임에 접근(Tm)
- TLB miss: TLB의 페이지 테이블 탐색했는데(Tb) 없으므로 메모리 OS영역 내의 페이지 테이블 탐색(Tm), 찾아서 해당 프레임 접근(Tm)
ex.
메모리 접근 시간(Tm): 100ns
TLB 탐색 시간(Tb): 20ns
TLB hit ratio(h): 80% 일때,유효 메모리 접근 시간(Teff)
= 0.8 (100 + 20) + 0.2 (20 + 100 + 100)
= 0.8 * 120 + 0.2 + 220
= 140 (ns)
locality 지역성
-
locality의 특성을 이용해 캐시를 사용함, 캐시는 성능을 높일 수 있는 가장 큰 요소
-
spetial locatlity(공간적인 지역성) - 어떤 주소를 접근하게 되면, 그 인접한 주소를 접근할 확률이 높아진다.
-
temporal locality(시간적인 지역성) - 어떤 주소를 접근했다면, 가까운 시간내에 똑같은 주소를 접근 할 확률이 높아진다.
캐시를 사용할때 주의 해야 할 점
여러개의 프로세스가 존재할 때, context switching이 일어난다면 physical address를 제대로 찾아가지 못하는 오류가 발생할 수 있다.
VPN과 PFN이 서로 다르기 때문에
따라서 그걸 해결하기 위한 방법으로는 아래의 두가지 방법이 존재한다.
- TLB를 전부 날려버린 후 새로 다시 입력
- ASID - TLB entry에 써져 있어 현재 프로세스가 갖고 있는 ASID를 checking함
그리고 이렇게 데이터를 입력한 후에 추후에 공간이 꽉차서 대체해야 될 상황이 오게되는데 그때 3가지 대체 방법이 존재한다.
- FIFO - 먼저 들어온애가 제일 먼저 나감
- Random - Random하게 쫓아냄
- LRU - 가장 최근에 사용되지 않았던 것을 쫓아냄
TLB의 관리를 어떻게 할것인가
hardware vs software
| Hardware TLB | Software TLB | |
|---|---|---|
| Advantages | 커널 개발자의 작업이 적고 CPU가 많은 작업을 수행 | 페이지 테이블에 대해 사전 정의된 데이터 구조가 없다 OS는 새로운 TLB 교체 정책을 자유롭게 구현할 수 있음 |
| Disadvantages | 페이지 테이블 데이터 구조 형식은 하드웨어 사양을 준수해야 한다. CPU TLB 교체 정책을 수정하는 제한된 기능 | 커널 개발자를 위한 추가 작업 OS 페이지 결함 핸들러는 항상 TLB에 있어야 한다. |
| 프로그래밍이 더 쉬움 | 유연성 향상 |
2. Page system의 크기 문제
페이지테이블의 크기가 커서 메모리에 올라가야 되니깐 메모리에 두번 접근해야 된다는 문제점이 있었는데, TLB라는 캐시를 이용해 spped issue를 해결했는데 table 사이즈가 너무 크다는 문제가 아직 남아있음
페이지 테이블의 사이즈를 줄이기 위한 방법을 소개하면 다음과 같다.
일단 이러한 방법은 TLB를 사용한다는 전제하에 이용되야, 속도측면에서 떨어지지 않을것입니다.
1. Bigger Pages
page 크기가 ↑, page Table size ↓
32bit system 기준으로, page size = 4KB = Page offset = 12bit, Page Table entry = 20bit
page size = 4MB, Page offset = 22bit, Page Table entry = 10bit
page size가 커지니깐 internal fragmentation이 생기게 됨
2. Alternate Date Structure (자료구조)
Hardware로 구현되어 있는 경우 사용 X, Software로 구현되어 있는 경우 사용 가능
항상 사용 가능한 방법이 아님
3. Inverted Page Tables
고정 크기 페이지테이블 개념
-
메모리 프레임마다 하나의 페이지 테이블 항목을 할당하여 프로세스 증가와 관계없이 크기가 고정된 페이지 테이블에 프로세스를 맵핑하여 할당하는 메모리 관리 기법
-
분산 메모리 할당 기법 중 페이징 방식에 사용
역 페이지 테이블의 장단점
| 장점 | 단점 |
|---|---|
| 프로세스 증가가 페이지 테이블의 증가로 이어지지 않아 메모리 활용 효율성 증가 | 최악의 경우 페이지 테이블 전체 탐색이 필요하므로 성능 저하 발생 가능 |
페이지 테이블의 크기가 증가되지 않아 효율적 메모리 관리를 통해 스레싱 예방 가능
– 시스템에 하나의 페이지 테이블만 존재, 테이블 내 항목은 메모리 한 프레임씩 맵핑
– 논리 주소는 Process-ID(pid), Page Number(p), Offset(d)으로 구성
– 물리 주소는 메모리 프레임 번호(i)와 Offset(d)으로 구성
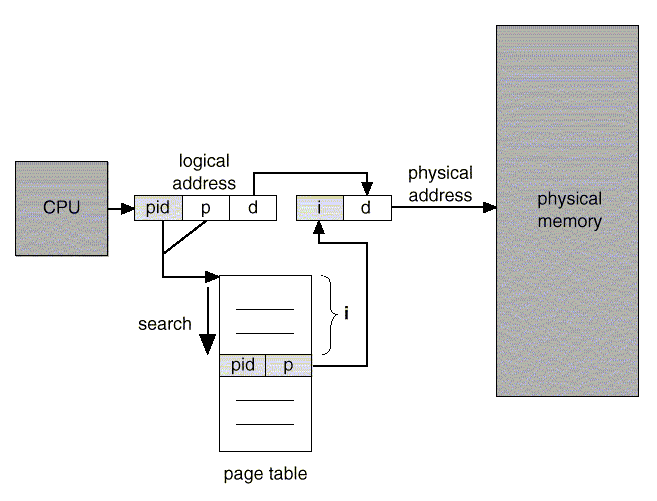
참조 = 역 페이지 테이블
4. Multi-Level Page Tables
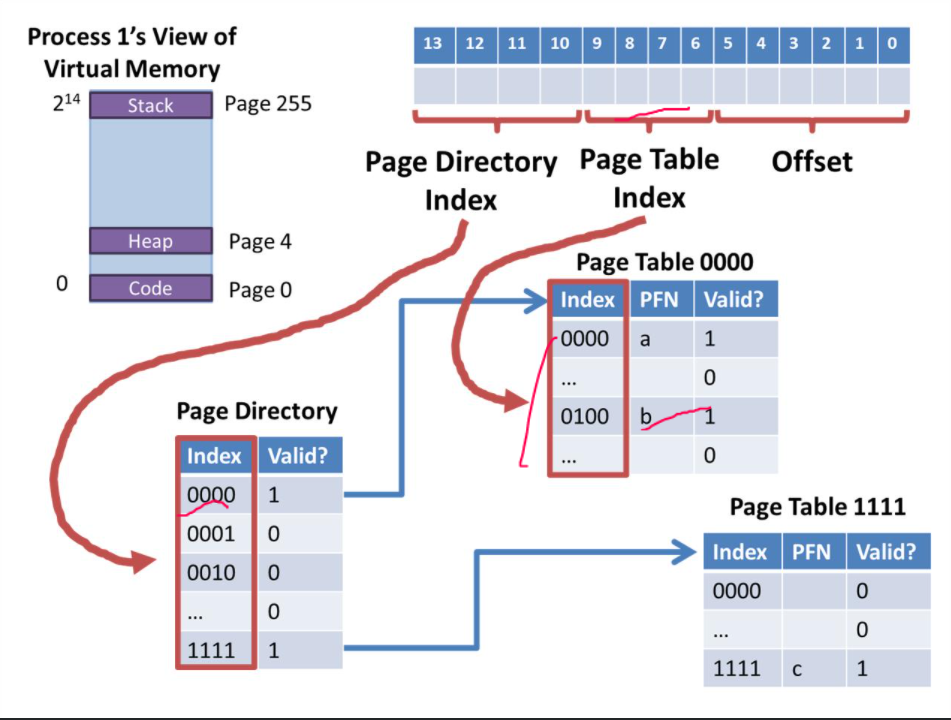
VPN을 절반으로 나눠 절반bit는 Page Directory Index, 나머지 절반은 Page Table Index로 구성해놓고 위와 사진과 같이 찾게된다.
Page Directory를 통해 Index를 찾고 Valid한지 체크한 후, 만약 Valid 하다면, Page Table Indexx를 통해 Index를 찾고 PFN을 찾게 되는 과정으로 이루어진다.
3. Swap Space
- paging을 가정

MMU에 의해 실행되는 거고, PAGE_FAULT만 운영체제 핸들러가 작동하는거임
PTE.Present를 제일 먼저 확인하고 1이라면
누구를 쫓아낼 것 인가
- On-demand approach (요구가 있을경우)
- 페이지가 요청이 됐는데, 들어갈 공간이 없으면 그때 처리
- Proactive approach (미리 예방)
할일 없을때 미리 swapping
- high watermak(기준) - 이 기준 아래일때
어떤 페이지를 교체할 것인가
미래에 사용할 것을 안다고 가정한다면, 그 애를 쫓아내는것이 가장 optimal 한 방법이다.
하지만 이 방법을 구현하는 것은 현실적으로 불가능하기 때문에, 기준을 삼아 비교할 수 있는 수단으로 사용할 수 있다.
실질적으로 구현해볼 수 있는 방법들을 아래 3가지와 같다.
- FIFO
- Random
- LRU (Least recently used) - 가장 최근에 사용되지 않았던 것을 쫓아냄
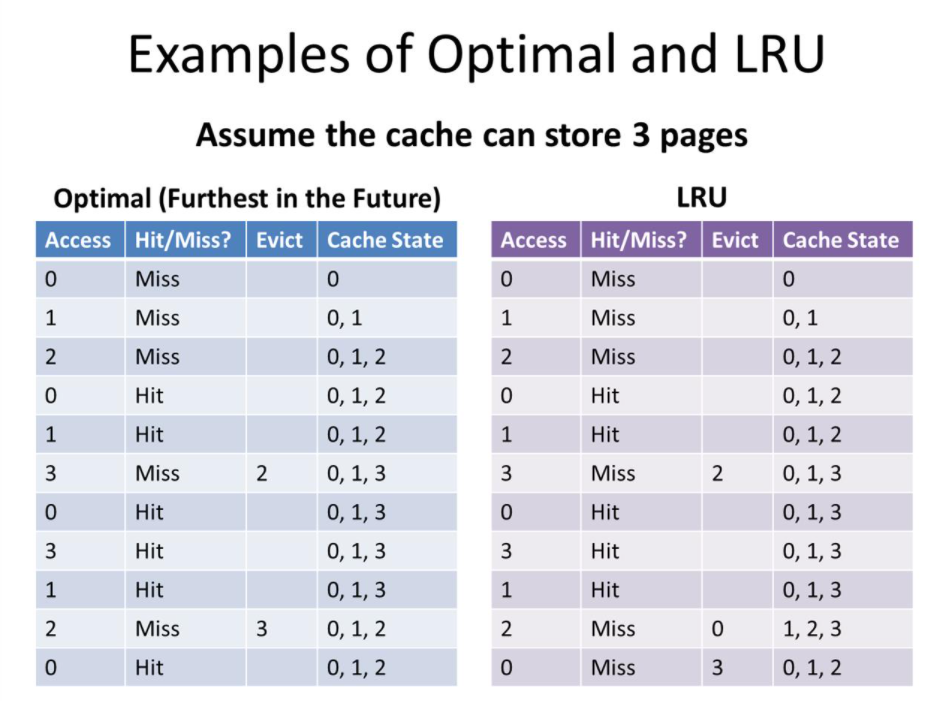
call miss를 제외하면 Optimal은 2번, LRU는 3번으로 최악의 경우에도 Optimal의 2배를 넘지 않는다는 것이 수학적인 결론이다.
LRU가 가장 성능이 좋은데, 어떻게 구현 할 것인가
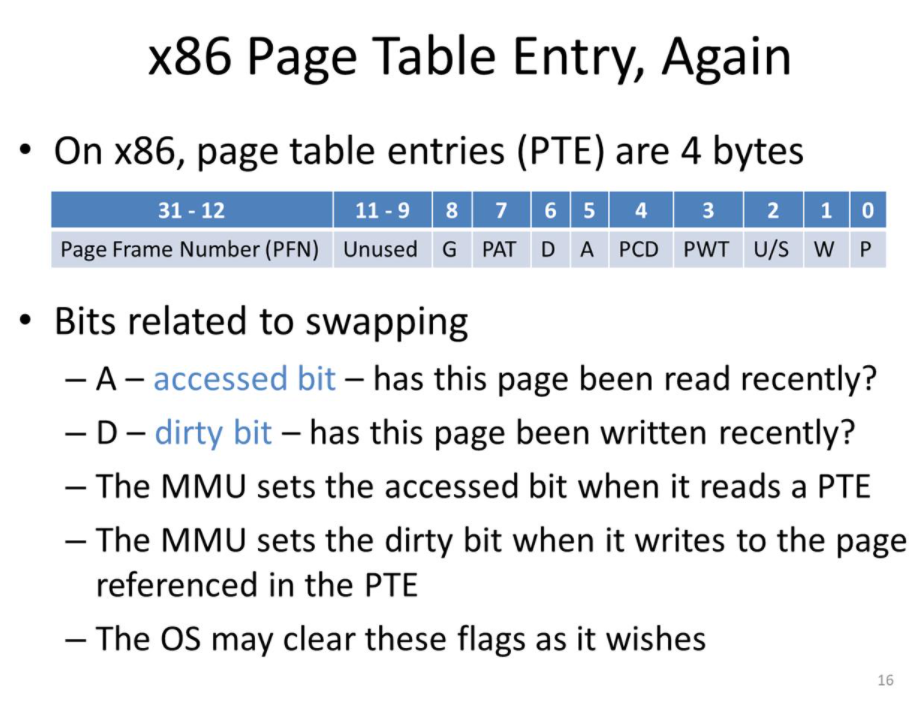
A(accessed bit) - 페이지가 최근에 read를 했는가
D(Dirty bit) - 페이지가 최근에 write를 했는가
이렇게 두개의 bit를 참고하면서 접근했는지 읽었는지 체킹할 수 있음
LRU Approximation algorithms
Reference bit algorithm
- 각 page는 0이라는 하나의 bit를 가진다.
- page가 referenced(참조되면) 1로 bit를 바꾼다.
- bit가 0인 page를 교체한다.
- timer를 두고 주기적으로 모든 page의 bit를 0으로 바꾼다.
타이밍이 좋지 않다면 문제가 발생할 수 있는데 이를 second-chance가 해결
타이밍이 좋지 않다 : 나는 bit가 1인데 timer 때문에 0으로 되고 그 즉시 대체될 때
Second-chance algorithm(Clock algorithm)
- 차례대로 FIFO를 수행하되, reference bit algorithm을 적용한다.
- page가 replace(교체)될 때, reference bit가 0이면 replace !
- 1이면 0으로 바꾼다. (다시 한 번 기회를 줌)
