회고
정글에서의 3주차가 끝났다.
또 알고리즘 주차지만 인간의 사고방식을 내려놓고
컴퓨터의 사고방식으로 바꾸는 한주였다.
저번주가 논리 오류와 싸웠다면
이번 주차는 '시간초과'와 싸웠다
왜 코드를 짜줘도 먹지를 못할까...
못먹겠다 투정해도 억지로 먹이질 못하니
컴퓨터의 입맛에 맞춰져야 했다.
이분탐색
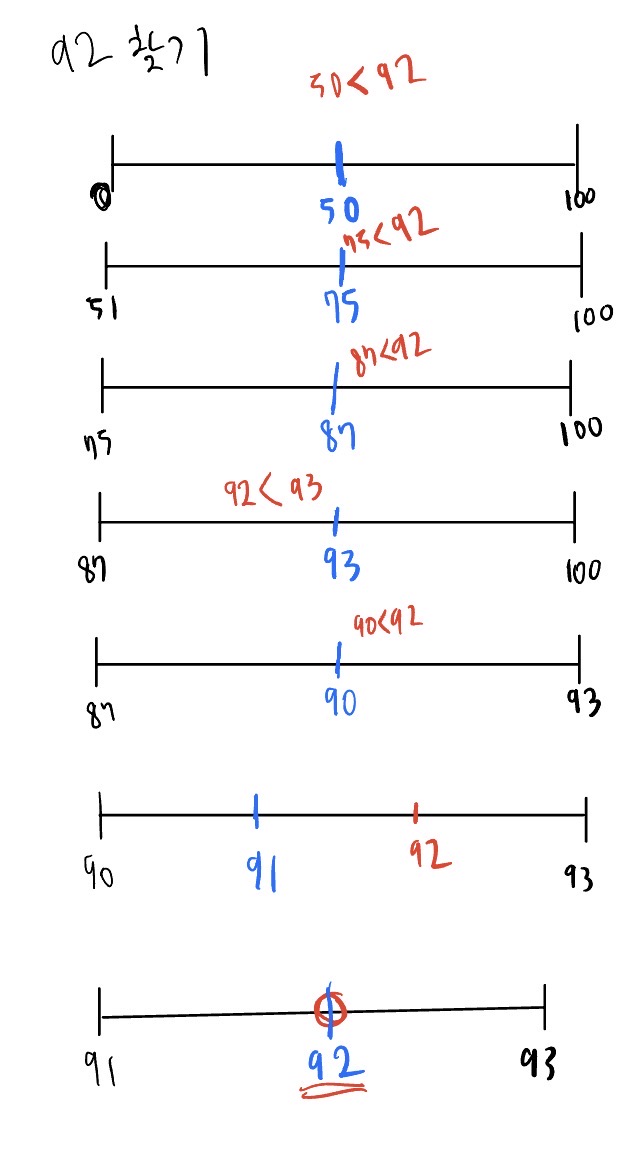
정렬되어있는 데이터들에서 원하는 값을 찾아내는 방법 중 하나다.
가운데 값보다 큰지 작은지만 비교하면 되고, 그 값들 기준으로 또 비교해서 값을 찾아가는 방법이다
시간복잡도는 O(log n)이 때문에 매우 빠르다.
인간은 가운데 값 찾는게 오히려 시간이 걸리기 때문에, 컴퓨터의 사고방식에 맞춘 방법이라 할수 있다.
분할정복
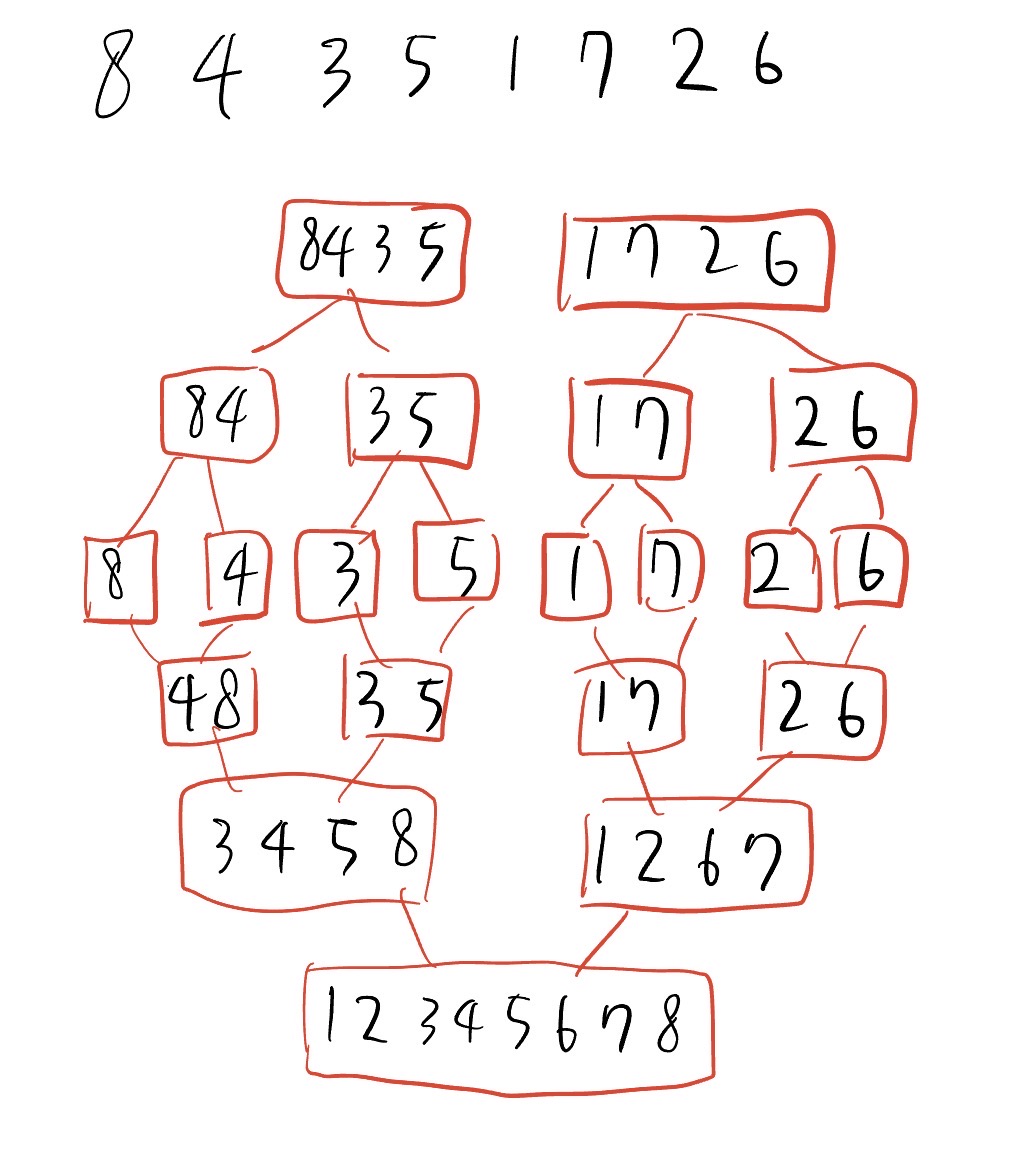
큰문제를 작은문제로 나누어 해결하는 방법이다.
문제를 병렬적으로 해결할수 있다는 장점이 있지만 다량으로 호출하면 오버헤드가 발생할수 있다.
그림은 분할정복중 하나인 머지정렬이다.
퀵정렬

피벗을 하나 설정하고 그 피벗을 기준으로 작은값 큰값으로 분할, 분할한 배열에서 또 피벗을 설정하고 분할하여 정렬하는 방법이다.
보통 빠르지만 잘 정렬되어있고 피벗을 끝값으로 설정하면 시간 복잡도가 O(n^2)이 나올수 있다는 단점이 있다.
스택과 큐
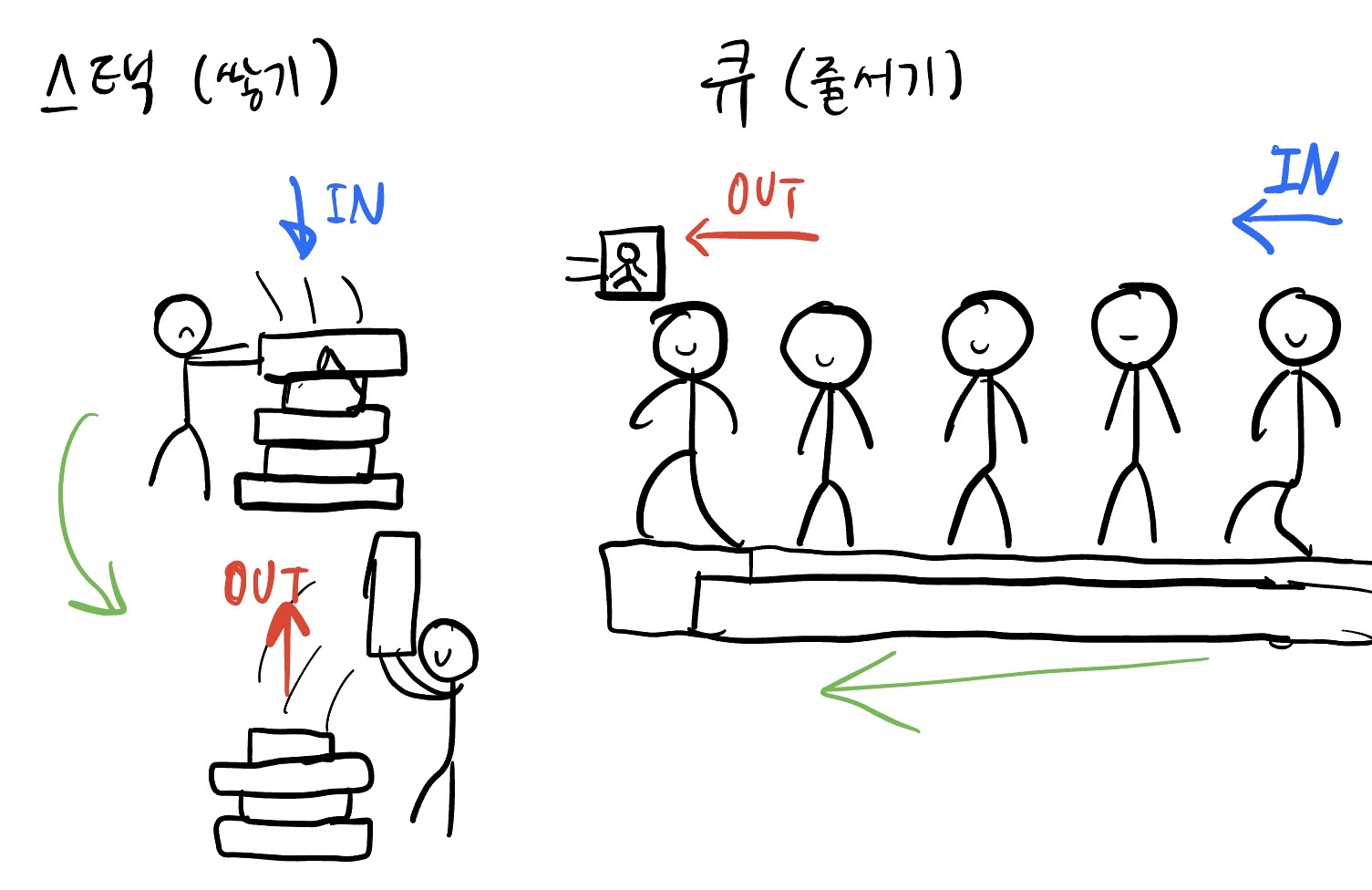
나중에 들어간것이 먼저 나오는게 스택, 먼저 들어간것이 먼저 나오는게 큐다
스택은 취소, 뒤로가기등 직전에 했던 것들을 수행하는데 유용하고
큐는 대기나 예약같이 순서가 있는것들을 수행하는데 유용하다
해시 테이블
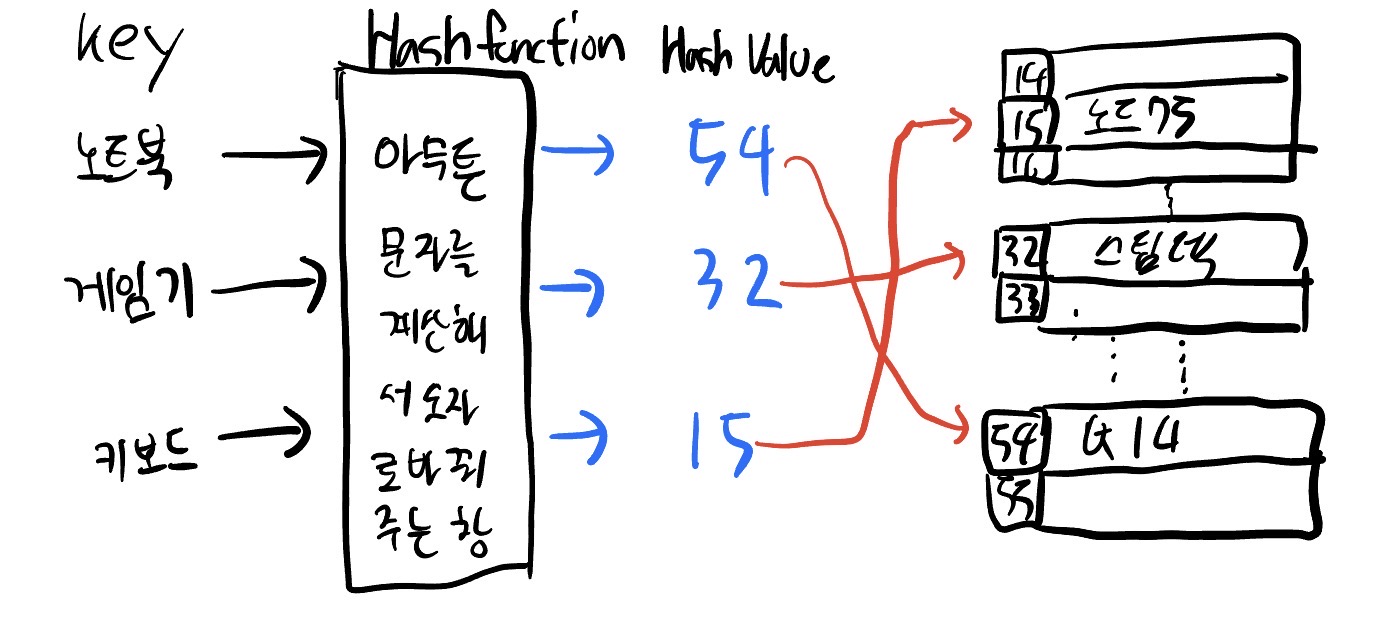
굳이 정렬하지 않고 이름을 입력해서 해시함수에 넣고 나오는 주소에 값을 저장하는 방법이다.
해시함수는 변하지 않으니 똑같은 이름을 넣으면 그 주소를 찾을수 있다. 찾지 않으니 시간복잡도는 O(1)이다
가끔 다른 이름을 넣어도 같은 주소가 나오는 해시 충돌이 발생하는데, 체이닝이나 개방주소법 등으로 해결한다
연결 리스트
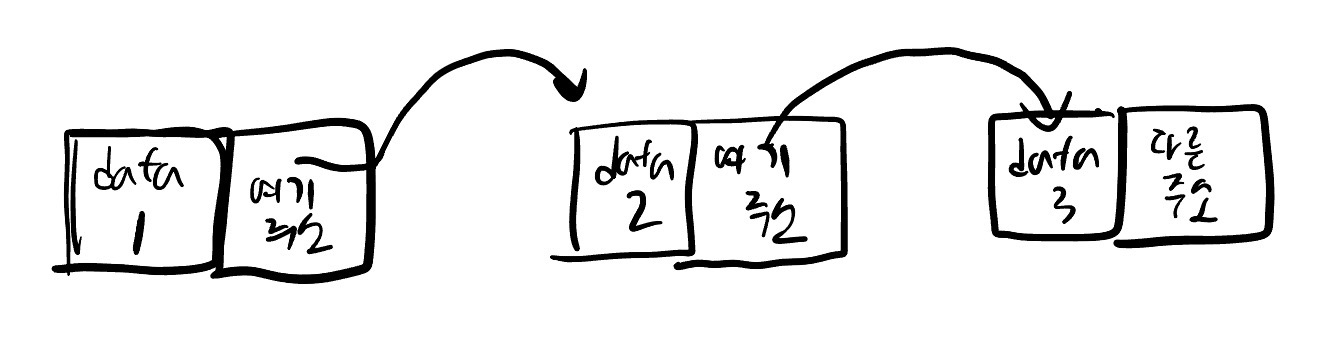
데이터들을 포인터로 연결하는 방법이다. 다음 또는 이전 데이터의 주소만 입력해놓으면 되니 데이터 추가, 삭제할때 주소만 바꿔주면 되서 배열보다 더 편하다.
하지만 특정 데이터에 바로 접근하기 힘들다는 단점이 있다.
그리고 이 연결 리스트로 문제를 풀다가 시간초과 문제가 터졌다.

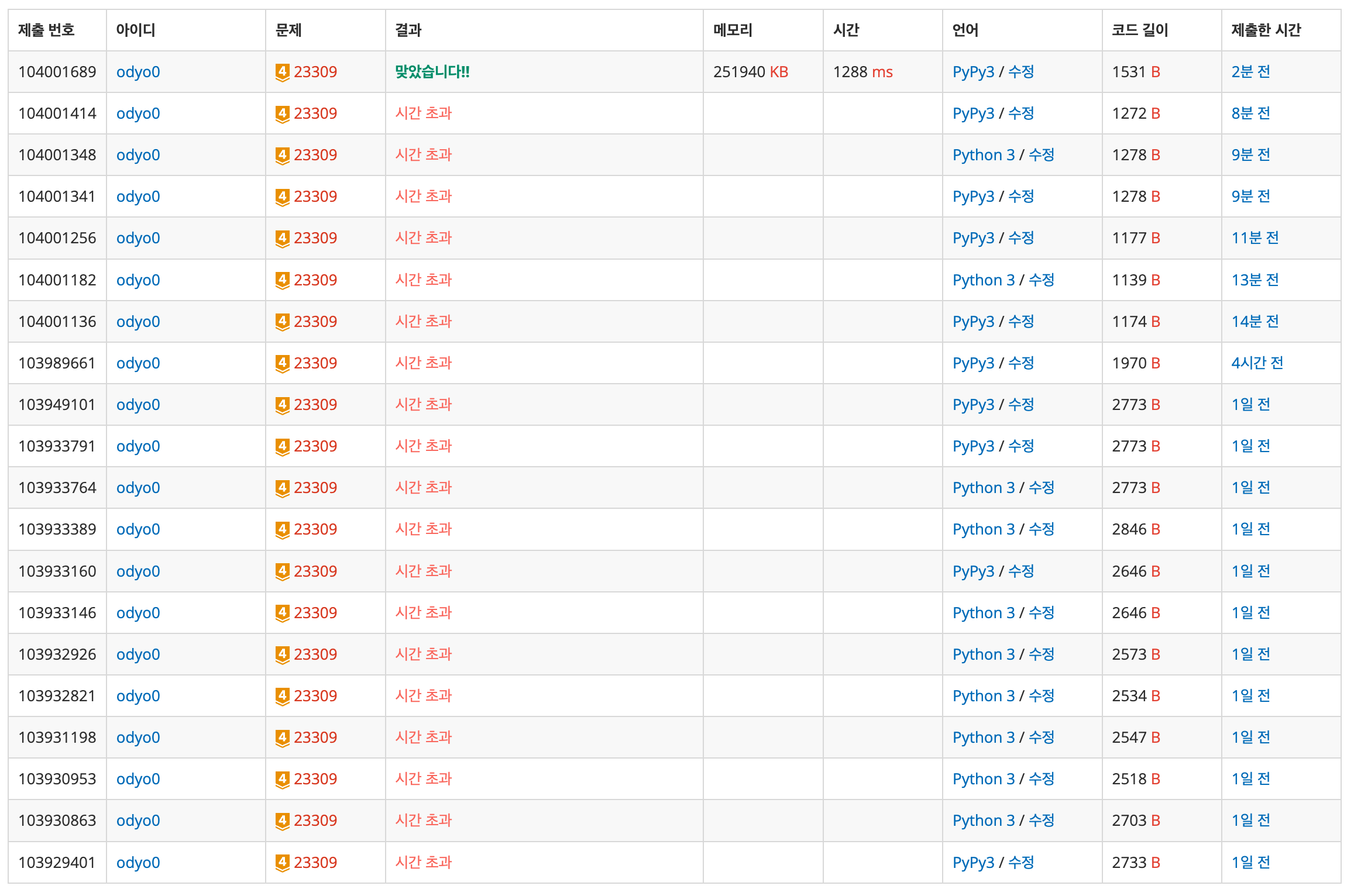
https://www.acmicpc.net/problem/23309
역에 고유번호라는 정보가 있고, 역들간 다음, 이전역으로 연결 되어있으니 연결리스트로 풀면 분명 괜찮아 보였다.
# 아니 온갖 난리를 다 쳐도 시간초과가 나오네 이걸 어쩌라고
import sys
input = sys.stdin.readline
output = [] #ㄴ시간초과 방지용
class Node:
def __init__(self,data):
self.prev = None
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def append(self, data, next_data): #역 초기화
if self.head == None:
self.head = Node(data)
station_id[data] = self.head
if next_data != None:
node = station_id[data]
next_node = Node(next_data)
node.next = next_node
next_node.prev = node
station_id[next_data]= next_node
else:
node = station_id[data]
node.next = self.head
self.head.prev = node
def build_next(self, current, data): #다음역 개설
output.append(str(current.next.data))
new_node = Node(data)
new_node.next = current.next #역 연결
current.next.prev = new_node
current.next = new_node
new_node.prev = current
station_id[data] = new_node
def build_prev(self, current, data): #이전 역 개설
output.append(str(current.prev.data))
new_node = Node(data)
new_node.prev = current.prev
current.prev.next = new_node
current.prev = new_node
new_node.next = current
station_id[data] = new_node
def clear_next(self, current): #다음역 폐쇄
next_node = current.next
output.append(str(next_node.data))
current.next = next_node.next
next_node.next.prev = current
next_node = None
def clear_prev(self, current): #이전역 폐쇄
prev_node = current.prev
output.append(str(prev_node.data))
current.prev = prev_node.prev
prev_node.prev.next = current
prev_node = None
N, M = map(int, input().split())
nums = list(map(int, input().split()))
station_id = {}
stations = LinkedList()
for i in range(len(nums)):
if i != len(nums) -1:
stations.append(nums[i], nums[i+1])
else:
stations.append(nums[i], None)
for _ in range(M):
commands = list(input().split())
command = commands[0]
if command == "BN":
station = station_id[int(commands[1])]
stations.build_next(station, int(commands[2]))
elif command == "BP":
station = station_id[int(commands[1])]
stations.build_prev(station, int(commands[2]))
elif command == "CN":
station = station_id[int(commands[1])]
stations.clear_next(station)
elif command == "CP":
station = station_id[int(commands[1])]
stations.clear_prev(station)
else:
print("wrong command")
sys.stdout.write("\n".join(output))시간초과가 나온다. 분명 이게 맞는데 안된다고 나온다.
나중에 찾아보니 파이썬에서는 연결리스트가 비효율적이니 다르게 풀라는 정보를 들었다.
겨우 구현해서 풀었더니 다르게 풀어야 된다니 좀 씁쓸한면이 없잖아 있었다.
수요 코딩회
이번주 수요코딩회는 mini Redis를 만드는 거였다.
기존에 구현하던 DB랑은 달리 디스크가 아니라 메모리에서 데이터를 읽고 쓰므로 빠르다는 장점이 있다.
메모리에 구현하지만 영속성을 지녀야 하기 때문에 사용한 명령어들을 로그로 저장해 추후에 복구하거나 특정시점의 메모리의 모든 데이터를 디스크에 저장해 복구할수도 있다. 전자가 AOF(Append Only File)이고 후자는 RDB방식이다.
우리 팀은 RDB방식으로 구현하였고, 잘 작동... 했을거다
TTL 기능을 담당했는데 시간을 서버 기준으로 절대 시간을 저장해놓고 그 시간이 지나면 나중에 키값 읽으려 할때 죽이는 식으로 구현했다.
마치며..
이번주는 저번주와 똑같은걸 더 어려운 내용으로 진행하니 참으로 지겨우면서도 힘들었다.
주차 후반부에 가서는 지쳐서 뛰쳐나가고 싶을 정도였다.
다음 주차때는 이런 상황이 익숙해지길 바랄뿐이다
