서론
시간이 슬슬 빠르게 지나간다.
첫주만 해도 언제 지나가나 생각했는데, 이제야 좀 시간이 돌아간다.
이번에 단순히 프로젝트만 하지 않고 옵시디언, ollama등 안 써본 툴들을 좀 해봤는데 맥북에어다보니 ollama는 좀 아쉬웠는데 옵시디언은 내가 원하던 툴을 드디어 찾은 기분이었다. 확실히 애플 메모보다는 쓰기 편했다.
이번 주는 malloc lab의 malloc 기능 구현이 목표였다.
이전 알고리즘 주차에 비해 과제량은 터무니 없이 낮았지만,
구현을 위해 가상 메모리가 어떻고, 메모리 할당하는 법, 힙, brk, free, implicit & explicit free list, 메모리 단편화, 등등 공부해야 할 내용이 많았다.
나름 전공자라 가상 메모리까지는 아는데 배워야 할 내용들은 확실히 더 깊게 들어갔다.
가상메모리 구조
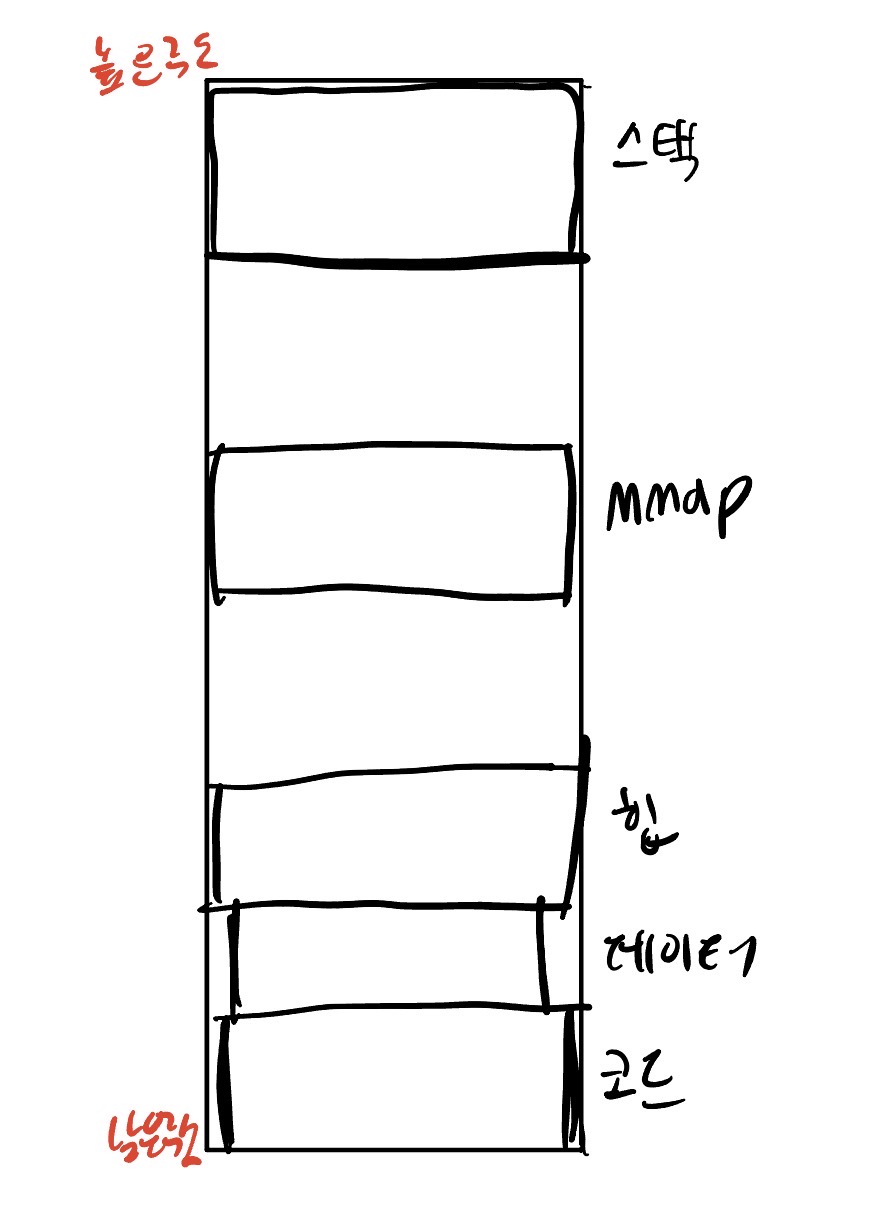
스택에는 지역 변수, 매개 변수들이 저장 된다. 함수가 종료 되면 그 함수에 할당된 별수들도 해제 시킨다. 재귀함수에서 stack overflow가 터지고는 하는데, 재귀가 너무 깊어지면 발생한다.
mmap은 파일이나 메모리를 프로그램 주소 공간에 붙여서 메모리처럼 사용할수 있게 한다. 파일을 직접 매핑한 것처럼 다룰 수 있게 한다.
힙은 동적 메모리 할당에 사용되는 영역으로 사용자가 할당해서 사용하는 공간이다. 우리가 이번주에 하는 것도 이 힙을 다루는거다.
데이터 영역과 코드 영역은 각각 전역변수나 static 데이터, 실행 코드가 저장이 된다.
동적 메모리 할당
brk, sbrk
동적 메모리 할당기에서 힙 영역이 부족할 때 힙의 끝(program break)을 늘려 더 많은 메모리를 확보하는 데 사용하는 방식이다.
brk는 힙 끝 주소 자체를 설정하는 시스템 콜이고, sbrk는 현재 힙 끝에서 얼마나 늘리거나 줄일지를 기준으로 조정하는 함수이다.
즉, malloc이 줄 수 있는 free block이 더 이상 없으면 내부적으로 힙을 확장해야 하고, 그때 전통적으로 brk/sbrk가 사용된다.
블록(block)
힙은 하나의 큰 덩어리로 관리되는 것이 아니라 여러 개의 블록으로 나뉘어 관리된다.
각 블록은 보통 헤더(header), 사용자에게 주는 데이터 영역(payload), 필요하면 푸터(footer)로 이루어진다.
헤더와 푸터에는 블록 크기와 할당 여부 같은 관리 정보가 들어간다.
블록 연결
힙 안의 블록들은 메모리 주소상에서 연속으로 놓여 있다.
그래서 현재 블록의 크기를 알면 다음 블록의 시작 위치를 계산할 수 있다.
이런 의미에서 블록은 물리적으로 이어져 있다.
또 free block만 따로 연결 리스트로 관리하는 방식도 있는데, 이것은 explicit free list에서 사용된다.
경계 태그(boundary tag)
블록의 앞쪽 헤더와 뒤쪽 푸터에 크기와 할당 여부를 저장하는 방식이다.
이 구조를 사용하면 현재 블록의 이전 블록이나 다음 블록이 free인지 빠르게 확인할 수 있다.
특히 free를 했을 때 인접한 free block끼리 병합(coalescing)하기 쉬워진다.
프롤로그 블록, 에필로그 블록
프롤로그 블록은 힙의 맨 앞에 두는 작은 가짜 할당 블록이다.
에필로그 블록은 힙의 맨 끝에 두는 크기 0의 가짜 할당 블록 헤더이다.
이 둘은 힙의 시작과 끝에서 예외 처리를 줄이기 위해 사용된다.
즉, 첫 블록 앞이나 마지막 블록 뒤에도 마치 블록이 있는 것처럼 처리하게 해 주는 장치이다.
implicit free list
힙에 있는 모든 블록을 처음부터 끝까지 순서대로 검사하면서 free block을 찾는 방식이다.
각 블록의 헤더를 확인해서 free인지 allocated인지 판단하고, free block 중 조건에 맞는 것을 선택한다.
구현은 단순하지만 할당된 블록까지 전부 검사해야 하므로 블록 수가 많아지면 비효율적이다.
explicit free list
free block들만 따로 연결 리스트로 묶어서 관리하는 방식이다.
할당된 블록은 리스트에 넣지 않고, free block 안에 prev와 next 같은 포인터를 저장해서 free block끼리만 연결한다.
이렇게 하면 전체 블록을 다 보지 않고 free block만 탐색하면 되므로 implicit free list보다 더 효율적이다.
대신 구현은 더 복잡해진다.
segregated free list
free list를 하나만 두지 않고 블록 크기별로 여러 개의 free list로 나누어 관리하는 방식이다.
예를 들어 작은 블록용 리스트, 중간 블록용 리스트, 큰 블록용 리스트처럼 나눈다.
이렇게 하면 요청한 크기와 비슷한 free block을 더 빨리 찾을 수 있어서 explicit free list보다도 탐색 효율이 좋아질 수 있다.
대신 리스트를 여러 개 관리해야 하므로 구현 복잡도가 더 올라간다.
블록 배치 정책(placement policy)
free block을 찾았을 때 어떤 블록을 실제로 선택할지 정하는 규칙이다.
같은 free block 집합이 있어도 어떤 정책을 쓰느냐에 따라 성능과 단편화가 달라진다.
first fit
처음부터 탐색해서 처음 발견한 충분히 큰 free block을 바로 선택하는 방식이다.
빠르고 구현이 단순하지만 힙 앞부분에 작은 조각들이 많이 쌓일 수 있다.
next fit
항상 처음부터 탐색하지 않고, 직전 탐색이 끝난 위치 다음부터 다시 탐색하는 방식이다.
앞부분만 반복해서 훑는 일을 줄일 수 있지만 실제 성능이 항상 더 좋은 것은 아니다.
best fit
사용 가능한 free block들 중에서 요청 크기에 가장 딱 맞는 블록, 즉 남는 공간이 가장 적은 블록을 선택하는 방식이다.
겉보기에는 공간 낭비가 적어 보이지만, 탐색 비용이 커질 수 있고 너무 작은 free block 조각들이 많이 생길 수도 있다.
내부 단편화(internal fragmentation)
할당된 블록 내부에서 사용되지 못하고 남는 공간이다.
예를 들어 사용자가 13바이트를 요청했는데 정렬이나 최소 블록 크기 때문에 16바이트 또는 그보다 큰 블록을 받았다면, 남는 부분이 내부 단편화이다.
즉, 이미 할당된 블록 안에 낭비가 들어 있는 경우이다.
외부 단편화(external fragmentation)
전체 free 공간의 총합은 충분하지만, 큰 연속 공간이 없어서 원하는 크기의 할당을 못 하는 경우이다.
예를 들어 free 공간이 여러 군데 흩어져 있어서 합치면 충분하지만, 한 번에 필요한 큰 블록이 없으면 외부 단편화가 발생한 것이다.
즉, free 공간이 블록 바깥쪽에서 조각조각 흩어진 상태이다.
malloc 구현
malloc 구현은 교재에 나오는 malloc.c부분을 먼저 참고해서 적었다..
그런데 기본적인 구현이 util(44) + thru(34)로 총 78점이 나왔다...
M4칩 만만세다.
//수정 전
void *mm_realloc(void *ptr, size_t size)
{
void *oldptr = ptr;
void *newptr;
size_t copySize;
newptr = mm_malloc(size);
if (newptr == NULL)
return NULL;
copySize = GET_SIZE(HDRP(oldptr)) - DSIZE;
//copySize = *(size_t *)((char *)oldptr - SIZE_T_SIZE);
if (size < copySize)
copySize = size;
memcpy(newptr, oldptr, copySize);
mm_free(oldptr);
return newptr;
}아무튼 더 개선하긴 해야해서 realloc(재할당)을 수정하였다.
기존 realloc의 경우 다음 블록을 확인하지 않고 사이즈를 찾아 재할당을 했는데,
이걸 다음과 같이 고쳤다.
void *mm_realloc(void *bp, size_t size)
{
void *oldptr = bp;
void *newptr;
size_t oldSize; //현재블록 사이즈
size_t asize; //실제 할당할 사이즈
size_t copySize; //현재 블록의 payload 사이즈
size_t nextSize;
size_t totalSize;
if (bp == NULL)
return mm_malloc(size);
if (size == 0) {
mm_free(bp);
return NULL;
}
oldSize = GET_SIZE(HDRP(oldptr));
if(size <= DSIZE)
asize = 2 * DSIZE;
else
asize = DSIZE * ((size + DSIZE + (DSIZE - 1)) / DSIZE);
copySize = oldSize - DSIZE;
//헤더, 풋터 제외하고 데이터 만큼만 기존 크기 가져옴
//copySize = *(size_t *)((char *)oldptr - SIZE_T_SIZE);
//수정하기
void *nextbp = NEXT_BLKP(oldptr);
//만약 다음 블록이 free이고 블록 크기가 충분할때
nextSize = GET_SIZE(HDRP(nextbp));
totalSize = oldSize + nextSize;
if (asize <= totalSize && !GET_ALLOC(HDRP(nextbp))){
//확장하고 남는 공간은 free 블록으로
if ((totalSize - asize) >= (2 * DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
nextbp = NEXT_BLKP(bp);
PUT(HDRP(nextbp), PACK(totalSize - asize, 0));
PUT(FTRP(nextbp), PACK(totalSize - asize, 0));
}
else {
PUT(HDRP(bp), PACK(totalSize, 1));
PUT(FTRP(bp), PACK(totalSize, 1));
}
return oldptr;
}
//그렇지 않을 경우
newptr = mm_malloc(size); //사이즈만큼 할당
if (newptr == NULL) //만약 새로운 포인터가 할당 안될시에
return NULL;
if (size < copySize)
copySize = size;
memcpy(newptr, oldptr, copySize);
mm_free(oldptr);
return newptr;다음 블록을 가져 올수 있을 때 이걸 쪼갤수 있느냐를 또 확인해야 하기 때문에 코드가 많이 길어졌다.
그래도 덕분에 util(50) + thru(36) 총합 86점으로 높은 점수가 나왔다.
그 외에 순서대로 next fit, best fit, segregated free list를 적용했지만 thru가 높아져도 util이 낮아져 86점보다 높은 점수가 나오지는 않았다.
수요 코딩회
이번에 구현하는건 B+트리를 구현하는 것이다.
B+트리
많은 키를 정렬된 상태로 저장하면서도 검색과 삽입 삭제를 효율적으로 처리하기 위해 사용한다.
B트리와 달리 리프노드에만 실제 데이터가 들어가고 내부 노드는 찾아가는 용도로만 사용한다.
일반 적인 트리와 달리 트리의 높이가 상대적으로 낮기 때문에 메모리 탐색시 건너뛰는 너비가 더 크기 때문에 메모리가 아니라 디스크에서 작동시에 더 유리하고, 리프노드가 연결리스트 형태로 연결 되어있기 때문에 내부 노드로 올라갈 필요 없이 범위 검색시에 더 좋다.
이번 구현에서는 저번 주에 조장이 만든 조에서 만든 sql처리기가 이해하기 쉽게 구현 되어있어서 거기에 다른 사람이 구현해놓은 B+트리를 붙여놓는 식으로 만들었다.
문제는 가져온 B+트리가 정석이랑 좀 많이 달라서 이해하는데 굉장히 애를 먹었다.
나름 단순하고 로우레벨로 짠 것 같은데 B+트리도 하루만에 이해해야 하는데 구현방식도 이해해야 하다보니 일이 대차게 꼬였다. 원래 간단한 서비스도 만드는게 목표였었는데 결국 못 만들었다.
게임 데이터 로그나 게시판 구현 같은걸 해보려고 했는데... 아쉬웠다.
마치며..
이번주차부터는 확실히 난이도가 많이 올라갔다고 느꼈다.
특히나 일단 구현보다는 이해를 하는게 먼저다보니 혼자서는 절대 안되겠다는걸 확실히 느낀 주차였다.
