
<지난 시간>
비주얼 스튜디오 코드에서 제공하는 데이터 사이언스 튜토리얼을 통해 타이타닉셋으로 데이터를 준비하는 실습 진행
<이번 시간>
다음 단계인 데이터 훈련 및 평가 실습
1. 데이터 불러오기
vsc에서 아래 코드를 입력해준다. 데이터를 불러와 train, test 데이터로 나누는 코드이다. 보통 80%의 train, 20%의 test 데이터로 나눈다.
📍 x : 입력값
📍 y : 출력값
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data[['sex','pclass','age','relatives','fare']], data.survived, test_size=0.2, random_state=0)역시나 당연히 오류가 생긴다. sklearn이 설치되어있지 않으니까!
(해결방법) 터미널에 pip install scikit-learn 을 입력해 설치한다.
2. 스케일링
다음은 스케일링 작업이다. 이게 뭐냐? 하면~
예를 들어 a와 b라는 클래스가 있다. a는 0과 1로 이루어져있고, b는 1부터 47의 숫자 데이터로 이루어져있다고 치자.
그렇게 되면 서로의 평균값이 크게 차이가 나 항상 b의 평균이 크다고 판단된다. 이를 데이터 불균형이라고 하고, 이 현상을 방지하기 위해 스케일링 작업이 이루어진다.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(x_train)
X_test = sc.transform(x_test)3. 분류
이 레퍼런스에서는 Gaussian Naïve Bayes algorithm을 사용하여 분류를 진행한다. 코드는 다음과 같다!
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)4. 평가
모델을 평가하는 코드이다.
from sklearn import metrics
predict_test = model.predict(X_test)
print(metrics.accuracy_score(y_test, predict_test))🔻실행 결과
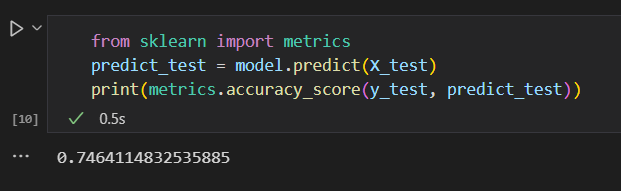
실행한 결과, 정확도는 74.6% 라는 것을 알 수 있다!
