
데이터베이스 성능 최적화를 위한 쿼리 튜닝 방법
ERP를 설계하다보면, 수많은 테이블의 조인연산이 이뤄지고, 원하는 데이터를 얻기위해 서브쿼리도 자주 사용하였습니다. 이렇게 되다 보니, 조인을 10~20개씩 걸어서 데이터를 조회 했습니다.
예를들어, 프로젝트 관련된 정보를 조회하고 싶다.
프로젝트 테이블 - 영업기회 테이블 - 수주 테이블 - 사원 테이블 - 부서 테이블 - 거래처 테이블 - 신용정보 테이블 - 프로젝트 타입 테이블 - 라이선스 테이블...
원하는 데이터를 얻고자 쿼리는 계속 늘어나게 됐습니다.
처음에는 성능상의 이슈가 없다가도 데이터가 늘어나게 되면 WAS서버가 다운되는 일까지 발생했습니다.
![]()
이를 해결하기 위해, 다양한 방법으로 쿼리를 튜닝해보고 비즈니스에 맞게 DB 아키텍쳐도 구성해보는 등 의미 있는 시간을 가져봤습니다.
1. 인덱스(Index) 설계 최적화
인덱스는 데이터 검색 속도를 크게 향상시키는 데이터베이스 구조입니다. 하지만 모든 컬럼에 인덱스를 추가하는 것은 성능 저하를 초래할 수 있습니다.
기술적 원리와 작동 방식
- B-Tree 기반 인덱스: 데이터를 정렬된 트리 구조로 저장하여 검색 연산의 시간 복잡도를 O(log n)으로 감소.
- 해시 기반 인덱스: 키 값에 대한 해시 함수를 사용하여 데이터 위치를 직접 참조, 특정 값을 찾는 데 매우 빠름.
- 클러스터드 인덱스: 테이블의 실제 데이터가 인덱스 순서에 따라 정렬.
적용 예시
- 조회 빈도가 높은
user_id컬럼에 인덱스를 추가. - 주문 상태(
status)를 기준으로 조회하는 경우status컬럼에 인덱스를 설정.
CREATE INDEX idx_user_id ON users(user_id);
CREATE INDEX idx_status ON orders(status);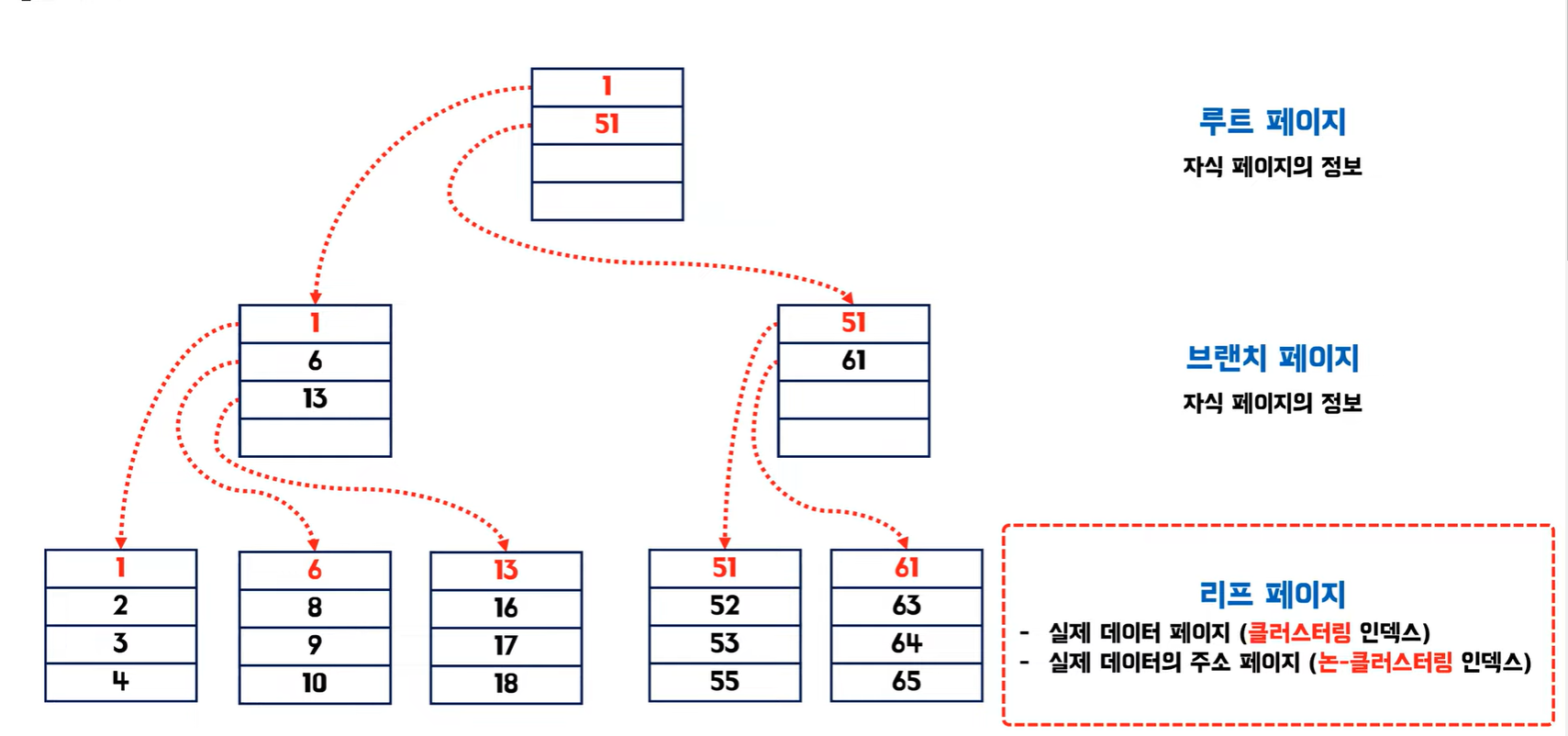
예시: B-Tree 인덱스 구조
2. 쿼리 작성 방식 개선
비효율적인 쿼리는 데이터베이스 리소스를 과도하게 소모합니다. 이를 방지하기 위해 쿼리를 간소화하고 최적화해야 합니다.
기술적 원리와 작동 방식
- SELECT 최적화:
SELECT *는 모든 컬럼을 불필요하게 조회하므로 특정 컬럼만 선택. - JOIN 최적화: 서브쿼리는 각 쿼리를 독립적으로 실행하므로, JOIN으로 병합하여 성능 개선.
- 필터 조건 최적화: WHERE 절을 사용하여 데이터를 미리 필터링.
적용 예시
order_items테이블에서 수량(quantity)이 10 이상인 데이터를 조회.
-- 비효율적인 쿼리
SELECT * FROM orders WHERE id IN (SELECT order_id FROM order_items WHERE quantity > 10);
-- 최적화된 쿼리
SELECT o.id, o.date
FROM orders o
JOIN order_items oi ON o.id = oi.order_id
WHERE oi.quantity > 10;3. 데이터 정규화와 비정규화
데이터 정규화는 중복을 최소화하고 데이터 일관성을 유지하는 데 효과적입니다. 반면, 비정규화는 읽기 성능을 높이는 데 유리합니다.
기술적 원리와 작동 방식
- 정규화: 테이블을 분리하여 중복 데이터를 제거하고 데이터 무결성 유지. 대표적으로 1NF, 2NF, 3NF 등이 있음.
- 비정규화: 읽기 성능을 위해 필요한 데이터를 하나의 테이블에 결합하여 저장.
적용 예시
- 정규화: 고객 테이블과 주문 테이블을 분리.
- 비정규화: 고객 이름과 주문 데이터를 하나의 테이블에 저장.
-- 정규화된 테이블 설계
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
-- 비정규화된 테이블 설계
CREATE TABLE orders_with_customer (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
date DATE
);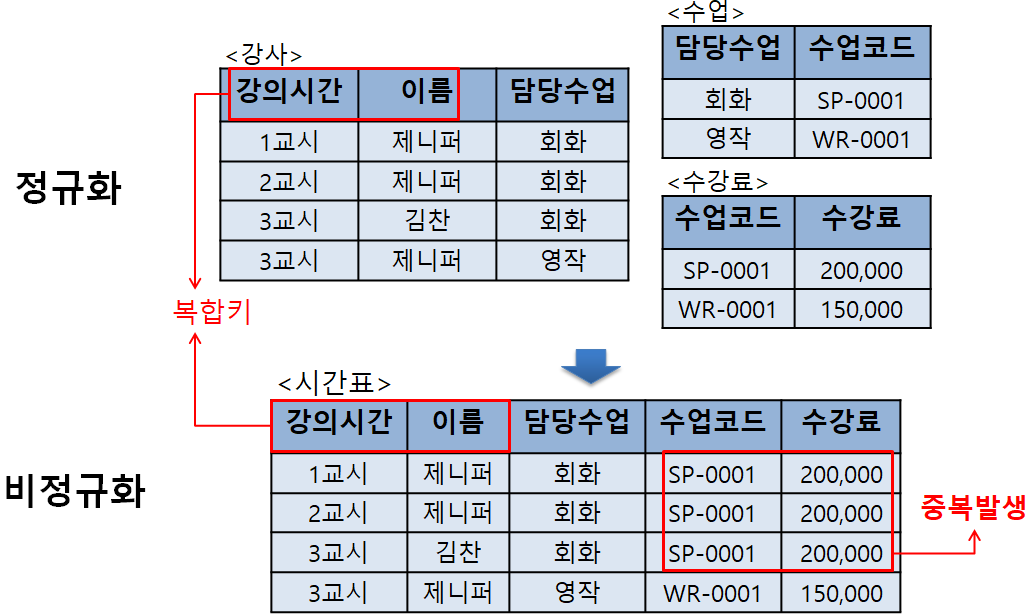
예시: 정규화와 비정규화 비교
4. 실행 계획(Execution Plan) 분석
데이터베이스가 쿼리를 처리하는 과정을 분석하여 병목 지점을 식별할 수 있습니다.
기술적 원리와 작동 방식
- Access Path: 테이블 전체를 스캔하는 Full Table Scan을 피하고 인덱스를 활용.
- Cost: 실행 계획에서 비용이 높은 연산(예: Sort, Hash Join 등)을 줄임.
적용 예시
- EXPLAIN 명령어로 실행 계획 확인.
EXPLAIN SELECT o.id, o.date FROM orders o WHERE o.status = 'completed';5. 데이터베이스 통계 정보 최신화
최신 통계 정보는 쿼리 최적화 도구가 효율적인 실행 계획을 수립하는 데 도움을 줍니다.
기술적 원리와 작동 방식
- 옵티마이저(Optimizer): 통계 정보를 활용하여 가장 적합한 실행 계획을 자동으로 선택.
- 통계 정보 갱신: 테이블과 인덱스의 데이터 분포를 주기적으로 분석.
적용 예시
ANALYZE명령어로 통계 정보 갱신.
ANALYZE TABLE orders;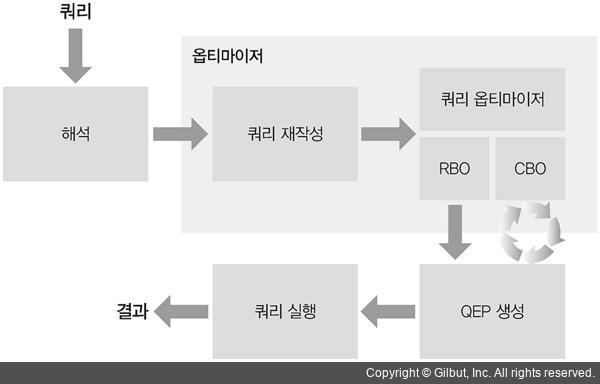
예시: 옵티마이저와 통계 정보
